
迭代器/for循环本质/生成器/常用内置方法
一.迭代器
1.1迭代器的定义:
迭代器:迭代取值的工具
迭代;更新换代的过程,每次迭代都是基于前一次迭代的基础
1.2迭代器的作用:
提供了一种不依赖索引取值的方法
1.3可迭代对象/迭代器对象
可迭代对象:内置有__iter__方法的叫做可迭代对象
迭代器对象:内置有__iter__方法,且还有__next__方法的叫做可迭代对象
可迭代对象----->__iter__------>迭代器对象
ps:1.迭代器对象一定是可迭代对象,但是可迭代对象不一定是迭代器对象
2.迭代器对象执行内置的__iter__之后还是本身,没有任何变化
f = open('xxx.txt','w',encoding='utf-8')
print(f is f.__iter__().__iter__().__iter__())
# True 因为文件本身是一个迭代器,对其执行内置的__iter__后还是其本身
迭代器的取值特点:只能往前取值,不能后退,不能取指定值,取完值后会报错(StopIteration)
d = {
'zhang':10000,
'wang':8000,
'li':7000
}
res = d.__iter__() # 将d转化成迭代器对象
print(res.__next__()) # 迭代取值 zhang
print(res.__next__()) # 迭代取值 wang
print(res.__next__()) # 迭代取值 li
print(res.__next__()) # 报错 StopIteration
print(d.__iter__().__next__()) # zhang
print(d.__iter__().__next__()) # zhang
print(d.__iter__().__next__()) # zhang
print(d.__iter__().__next__()) # zhang
#出现上述结果的原因是每次都重新生成的迭代器,所以每次取值都为zhang
迭代取值的优缺点:
优点:1.不依赖索引取值
2.内存中永远只占据一份空间,不会导致内存的溢出
缺点:1.不能指定取值
2.将迭代器中的值取完后若继续取值会报错StopItertion
二.for循环的本质
for循环的内部本质:
1.将in后面的对象(可迭代对象/迭代器对象)执行内置的__iter__转换成迭代器对象
2.对产生的迭代器对象执行内置的__next__进行迭代取值
3.内部存在异常捕获StopItertion,当__next__报这个错的时候,自动结束循环(迭代器内部值被取完)
如何处理取值中的异常:
d = {
'zhang':10000,
'wang':8000,
'li':7000
}
res = d.__iter__()
while True:
try:
print(res.__next__())
except StopIteration:
print('迭代器中没有值了') # 当迭代器中没有值时会执行这行代码,这样可以使迭代器在取值使不报错,咋没值时直径跳出循环
break
三.生成器
本质:用户自己定义的迭代器,其本质就是迭代器
特点:惰性运算,开发者自己定义
生成器函数:函数内部包含有yield关键字.
ps:1.如果一个函数内含有yield关键字,那么加括号执行函数的时候并不会除法函数的运行
2.yiled后跟的值就是调用迭代器__next__方法你能得到的值
3.yiled既可以返回一个值也可以返回多个值,返沪i多个值以元组的形式返回
def func():
print('first')
yield 1
print('second')
yield 2
print('third')
yield 3,'a','b'
print('forth')
g = func()
print(g.__next__()) # first 1
print(g.__next__()) # second 2
print(g.__next__()) # third (3,'a','b')
print(g.__next__()) # StopIteration
ps:每执行依次__next__从g中取出一个值,会暂停在yield处,直至下次执行__next__直至迭代器中没有值报错
yiled支持外界为其传参:(形参,闭包)
def dog(name):
print('%s 准备开吃'%name)
while True:
food = yield
print('%s 吃了 %s'%(name,food))
g = dog('egon') # 函数体代码中含有yiled的,函数名加括号不会调用函数而是将函数转化成生成器
g.__next__() # 必须先将代码运行至yield 才能够为其传值 egon 准备开吃
g.send('狗不理包子') # 给yield左边的变量传参 触发了__next__方法 egon 吃了 狗不理包子
ps:return和yiled的异同点
相同:1.都有返回值,且都可以返回都和值以元组的形式
不同:1.return只能返回一次值,返回后函数立即结束,yiled可以返回多次
2.yiled可以接收外界传值
生成器表达式:
res = (i for i in range(10)) # <generator object <genexpr> at 0x00000230060FF048>
ps:生成器不会主动运行任何一行代码,必须通过内置的__next__方法来取值,且每运行一次只取出其中的一个值
print(res.__next__()) # 0 print(res.__next__()) # 1 print(res.__next__()) # 2
引用场景:取一个较大的容器类型,在python2中

python3中

这样可以节省内存,当需要值得时候生成器才会产生需要得数量,以节约内存,防止内存溢出
示例:
def add(n,i):
return n+i
def test():
for i in range(4):
yield i
g=test()
for n in [1,10]:
g=(add(n,i) for i in g) # 第一次for循环g=(add(n,i) for i in test())
# 第二次for循环g=(add(n,i) for i in (add(n,i) for i in test())) 此时n=10
res=list(g) # 从生成器中取值
"""
在test()函数中进行for循环取值,第一个值为0,则i为0,此时n为10,执行add函数,得出结果为10在执行for循环取出值为10,执行add函数,得出第一次结果为20.
以此类推,进行四次test()分别输出0,1,2,3.右侧add函数输出结果为10,11,12,13.左侧add输出结果为20,21,22,23
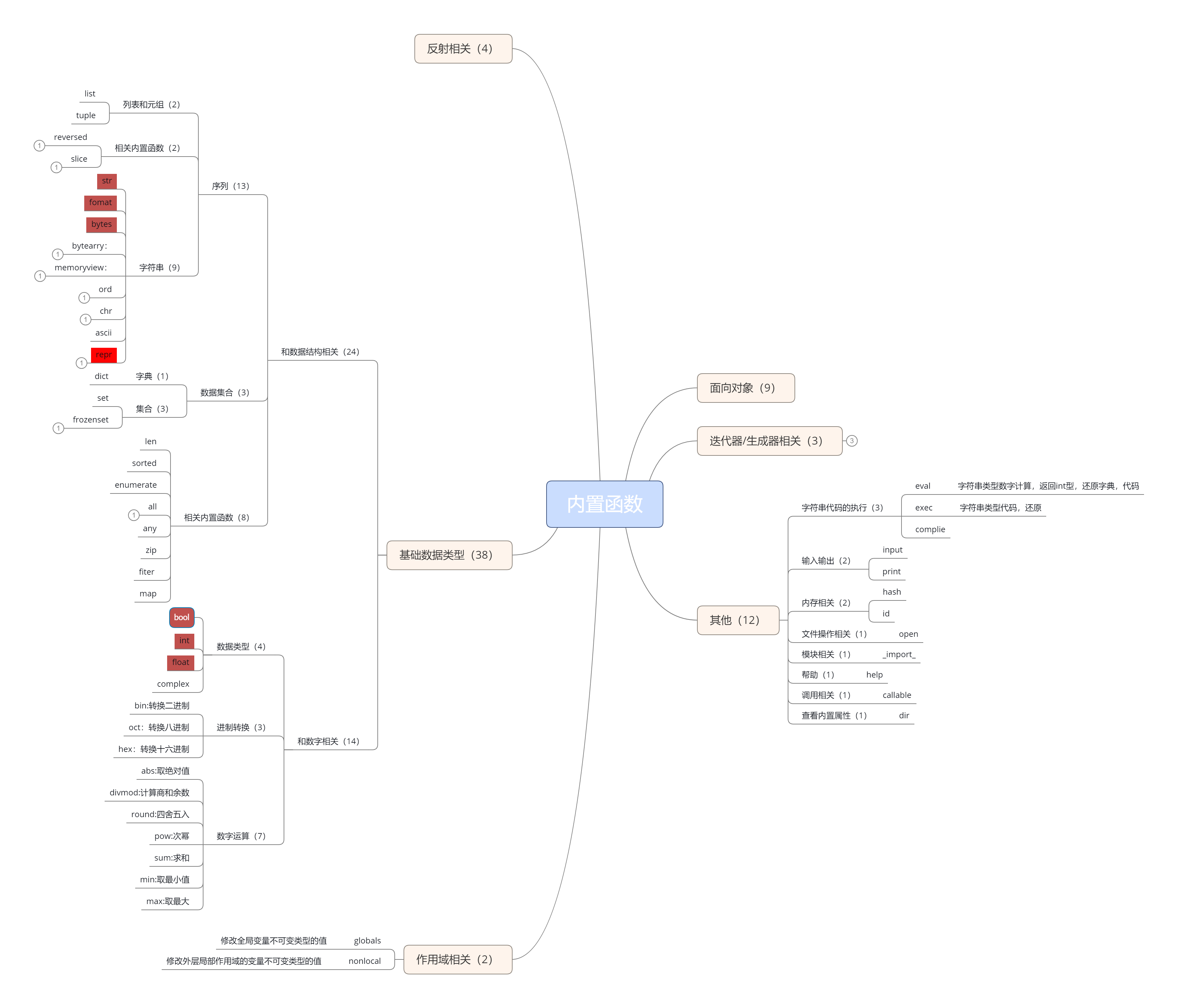
四.常用得内置函数
# abs取绝对值
print(abs(-2)) # 2
#all后跟得可迭代对象中若有一个元素为false则整个为false
a=[1,2,3,0]
print(all(a)) # False
#any后跟得可迭代对象中若有一个元素为True则整个为True
b=[0,{},1]
print(any(b)) # True
#bin10进制转2进制
print(bin(17)) # 0b10001
#hex10进制转16进制
print(hex(17)) # 0x11
#oct10进制转8进制
print(oct(17)) # 0o21
# bool判断bool值
print(bool(1)) # True
#bytes转换成二进制类型
s='qwe'
print(bytes(s,encoding='utf-8')) # b'qwe'
#callable可调用的(加括号执行相应功能得,函数)
#chr
print(chr(97)) # 将数字转换成ascii码表对应的字符 # a
#ord
print(ord('a')) # 将字符按照ascii表转成对应的数字 # 97
# dir获取当前对象名称空间里面的名字
#divmod 用第一个参数除第二个参数,判断余数是否为0,若不为0则商加一.多用在分页
print(divmod(101,10)) # (10, 1)
# enumerate 枚举对迭代对象进行编号,入哦没申明开始序号默认从0开始
l = ['a','b']
for i,j in enumerate(l,1): # 1 a
print(i, j) # 2 b
# eval 只支持简单的python代码不支持逻辑代码 exec支持逻辑代码
s1 = """
print(1 + 2)
for i in range(3):
print(i)
"""
# eval(s1)
exec(s1) #3 1 2 3
# format格式化输出
# 1.{}类似%s占位
# 2.{}按索引
# 3.{name}知名道姓
#print(globals()) # 产看全局名称空间
#locals() # 查看局部名称空间
#help 查看注释
# isinstance 后面统一改方法判断对象是否属于某个数据类型
n = 1
print(type(n))
print(isinstance(n,list)) # 判断对象是否属于某个数据类型 False
print(pow(2,3)) # 前一个数得几次方 8
print(round(3.4)) # 四舍五入 3
补充面试题:
def func():
return [lambda x:i*x for i in range(4)]
print([m(2) for m in func()]) # [6,6,6,6]
def func():
list=[]
for i in range(4):
def inner(x):
return i*x
list.append(inner)
return list
print([m(2) for m in func()]) # [6,6,6,6]
def func():
list=[]
for i in range(4):
def inner(x,i=i):
return i*x
list.append(inner)
return list
print([m(2) for m in func()]) # [0,2,4,6]
def demo():
for i in range(4):
yield i
g=demo() # g为生成器
g1=(i for i in g)
g2=(i for i in g1)
print(list(g1))
print(list(g2))
面向过程:类似于工厂得流水线
优点:能将复杂得问题流程化,从而将问题简单化
缺点:程序得拓展性差,一旦某个地方修改,可能全局都需要修改

 浙公网安备 33010602011771号
浙公网安备 33010602011771号