

结对作业
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 结对编程项目作业 |
| 这个作业的目标 | 小学四则运算题目自动生成程序的实现+PSP表格使用+GitHub代码管理+双人结对编程练习 |
| GitHub项目地址 | 地址 |
| 成员及Github地址 | 3219005447 连婉玲 + 3119005411 冯子垚 |
1.需求分析:
题目:实现一个自动生成小学四则运算题目的命令行程序(也可以用图像界面,具有相似功能)。
说明:
自然数:0, 1, 2, …。
真分数:1/2, 1/3, 2/3, 1/4, 1’1/2, …。
运算符:+, −, ×, ÷。
括号:(, )。
等号:=。
分隔符:空格(用于四则运算符和等号前后)。
算术表达式:
e = n | e1 + e2 | e1 − e2 | e1 × e2 | e1 ÷ e2 | (e),
其中e, e1和e2为表达式,n为自然数或真分数。
四则运算题目:e = ,其中e为算术表达式。
需求:
(1)使用 -n 参数控制生成题目的个数,例如
Myapp.exe -n 10
将生成10个题目。
(2)使用 -r 参数控制题目中数值(自然数、真分数和真分数分母)的范围,例如
Myapp.exe -r 10
将生成10以内(不包括10)的四则运算题目。该参数可以设置为1或其他自然数。该参数必须给定,否则程序报错并给出帮助信息。
(3)生成的题目中计算过程不能产生负数,也就是说算术表达式中如果存在形如e1− e2的子表达式,那么e1≥ e2。
(4)生成的题目中如果存在形如e1÷ e2的子表达式,那么其结果应是真分数。
(5)每道题目中出现的运算符个数不超过3个。
(6)程序一次运行生成的题目不能重复,即任何两道题目不能通过有限次交换+和×左右的算术表达式变换为同一道题目。例如,23 + 45 = 和45 + 23 = 是重复的题目,6 × 8 = 和8 × 6 = 也是重复的题目。3+(2+1)和1+2+3这两个题目是重复的,由于+是左结合的,1+2+3等价于(1+2)+3,也就是3+(1+2),也就是3+(2+1)。但是1+2+3和3+2+1是不重复的两道题,因为1+2+3等价于(1+2)+3,而3+2+1等价于(3+2)+1,它们之间不能通过有限次交换变成同一个题目。
(7)生成的题目存入执行程序的当前目录下的Exercises.txt文件,格式如下:
四则运算题目1
四则运算题目2
……
其中真分数在输入输出时采用如下格式,真分数五分之三表示为3/5,真分数二又八分之三表示为2’3/8。
(8)在生成题目的同时,计算出所有题目的答案,并存入执行程序的当前目录下的Answers.txt文件,格式如下:
答案1
答案2
特别的,真分数的运算如下例所示:1/6 + 1/8 = 7/24。
(9)程序应能支持一万道题目的生成。
(10)程序支持对给定的题目文件和答案文件,判定答案中的对错并进行数量统计,输入参数如下:
Myapp.exe -e
统计结果输出到文件Grade.txt,格式如下:
Correct: 5 (1, 3, 5, 7, 9)
Wrong: 5 (2, 4, 6, 8, 10)
其中“:”后面的数字5表示对/错的题目的数量,括号内的是对/错题目的编号。为简单起见,假设输入的题目都是按照顺序编号的符合规范的题目。
2.前言:
2.1开发环境:
-
编程语言:python3
-
IDE:pycharm
-
单元测试:unittest
-
代码性能分析工具:pycharm自带的插件
-
代码管理:GitHub
2.2流程设计:
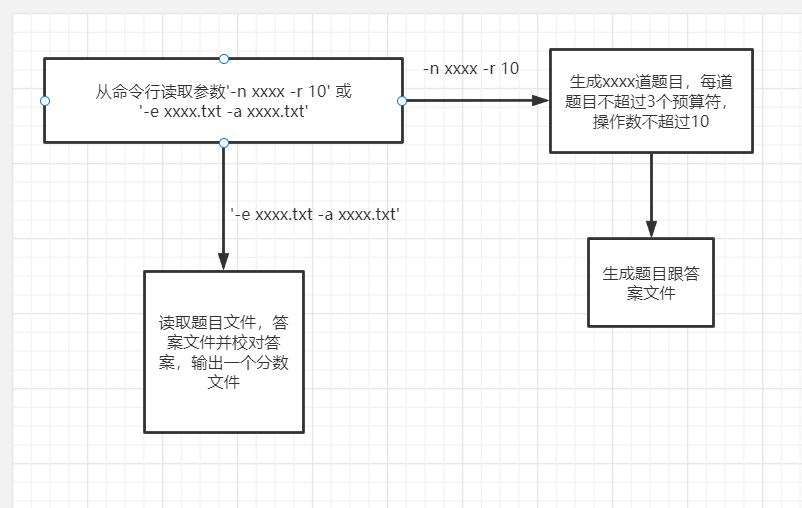
2.3函数与类接口:
![]()
- BinaryTree.py 生成二叉树,存放后缀表达式,与新生成的式子查重
- Compute Equation.py 处理式子并计算出式子的答案
- GenerateEquation.py 生成随机式子
- Proofread.py 校对答案是否正确,并将校对结果放入Grade.txt
- unit_test.py 单元测试

2.4核心算法:
逆波兰算法
1. 算法简介:
逆波兰表达式又叫做后缀表达式。逆波兰表示法是波兰逻辑学家J・卢卡西维兹(J・ Lukasiewicz)于1929年首先提出的一种表达式的表示方法。
2.后缀表达式
- 表达式有前缀、后缀、中缀表达式,其中的区别是运算符的位置分别在运算数的前,中,后的位置。例如:1-(2+3) 等价于-1 + 2 3,这是前缀表达式,(3 + 4) × 5 - 6 这是中缀表达式,3 4 + 5 × 6 - 后缀表达式
3.算法实现:
-
运算符在操作数后面,这有助于计算机计算式子的值。
-
运算符是按顺序优先级计算的。例:
(1+1)*(2+2) 等价于 1 1 + 2 2 + *,1+1 的值与 2+2 的值相乘
4.算法原理:
- 项目算法
-
先是将生成的中缀表达式转换成后缀表达式存放在二叉树中,然后计算式子的值输出
-
中缀转后缀算法。
你需要设定一个栈 operators_stack,和一个线性表 suffix_stack 。operators_stack 用于临时存储运算符和左括号分界符 '(' ,suffix_stack 用于存储后缀表达式。
遍历原始表达式中的每一个表达式元素
(1)如果是操作数,则直接追加到 suffix_stack 中。只有 运算符 或者 分界符( 才可以存放到栈
operators_stack 中
(2)如果是分界符
Ⅰ 如果是左括号 '(', 则 直接压入 operators_stack ,等待下一个最近的 右括号 与之配对。
Ⅱ 如果是右括号 ')',则说明有一对括号已经配对(在表达式输入无误的情况下)。不将它压栈,丢弃它,然后从
operators_stack 中出栈,得到元素e,将e依次追加到 suffix_stack 里。一直循环,直到出栈元素e 是 左括号 ( ,同样丢弃他。
(3)如果是运算符(用op1表示)
Ⅰ如果 operators_stack 栈顶元素(用op2表示) 不是运算符,则二者没有可比性,则直接将此运算符op1压栈。 例如栈顶是左括号 ( ,或者栈为空。
Ⅱ 如果 operators_stack 栈顶元素(用op2表示) 是运算符 ,则比较op1和 op2的优先级。如果op1 > op2 ,则直接将此运算符op1压栈。
如果不满足op1 > op2,则将op2出栈,并追加到L,再试图将op1压栈,如果如果依然不满足 op1>新的栈顶op2,继续将新的op2弹出追加到L ,直到op1可以压入栈中为止。
也就是说,如果在 operators_stack 栈中,有2个相邻的元素都是运算符,则他们必须满足:下层运算符的优先级一定小于上层元素的优先级,才能相邻。
-
最后,如果 operators_stack 中还有元素,则依次弹出追加到L后,就得到了后缀表达式。
3.类与函数的设计和实现过程(含部分关键代码及说明):
# 生成随机式子
def generate_equation(max_value):
operator = [' + ', ' - ', ' x ', ' ÷ '] # 运算符前后加空格
end_opt = ' ='
# 随机生成自然数和分数的个数,但控制总和不超过4,从而控制题目不超过三个运算符
num_nature, num_fraction = np.random.randint(1, 3, size=2)
# 生成 [1,max_value) 之间的自然整数
gen_nature = [str(x) for x in np.random.randint(1, max_value, size=num_nature)]
# np.random.rand()产生的是[0,1)之间的小数,产生 num_fraction 个数
# round()根据四舍五入来取值,+0.5是为了防止取值后为0
gen_float = [str(round(x + 0.5, 1)) for x in np.random.rand(num_fraction)]
gen_fraction = list()
# decimal.Decimal()把 gen_float 中字符串类型转化为十进制数据,然后用fractions.Fraction()再次转化为分数
for fraction in [fractions.Fraction(decimal.Decimal(x)) for x in gen_float]:
# 通过 check_fraction 函数来检查分数,将结果添加至gen_fraction
gen_fraction.append(check_fraction(fraction))
equation = ''
bag = gen_nature + gen_fraction # 将生成的自然整数和分数存在bag里
len_bag = len(bag)
# left_bracket 生成左括号的位置,0代表不生成,1代表生成
left_bracket = np.random.randint(0, 2)
right_bracket = 0
if left_bracket == 0:
right_bracket = 0
else:
if len_bag == 3:
left_bracket = np.random.randint(0, 3)
elif len_bag == 4:
left_bracket = np.random.randint(0, 4)
# 生成有括号的位置
if left_bracket > 0:
if left_bracket != len_bag - 1:
right_bracket = np.random.randint(left_bracket+1, len_bag)
else:
right_bracket = len_bag
for i in range(len_bag):
if left_bracket == i + 1: # 加入左括号
equation += '( '
# 随机生成一个[0,len(bag))之间的整数
randint = np.random.randint(len(bag))
# 从 bag 取出第 randint 位的数,存进 equation 中
equation += bag[randint]
if i + 1 == right_bracket: # 加入右括号
equation += ' )'
if i < len_bag - 1:
# len_bag-1即是i的最大取值,所以当i<len_bag-1时,后面加随机操作符
equation += operator[randint]
else:
# 当i=len_bag时,把等号补上,式子完成,跳出循环
equation += end_opt
bag.pop(randint) # 当数取出的时候,应该把它从bag里去除
return equation
4.效能分析:
- main函数:
def main():
try:
# sys.argv[1:5]只读取前四个输入字符 parameter1/parameter2为两个参数
parameter1, value1, parameter2, value2 = sys.argv[1:5]
#parameter1, value1, parameter2, value2 = '-n','10000','-r','10'
#parameter1, value1, parameter2, value2 = '-e', 'Exercises.txt', '-a', 'Answers.txt'
choice = choice_fun(parameter1, parameter2)
if choice == 1: # 为生成题目和答案的过程
n = value1
r = value2
generate_equation(r)
generate_file(n, r)
print("生成题目成功!请查看 'Exercises.txt' 和 'Answers.txt'\n")
elif choice == 2: # 为校对给定题目和答案的过程
e = value1
a = value2
proofreading(e, a)
print("校对完成!请在 'Grade.txt' 查看结果\n")
except IOError:
print("Error:输入参数错误,请检查后重新输入")
4.1耗时情况:
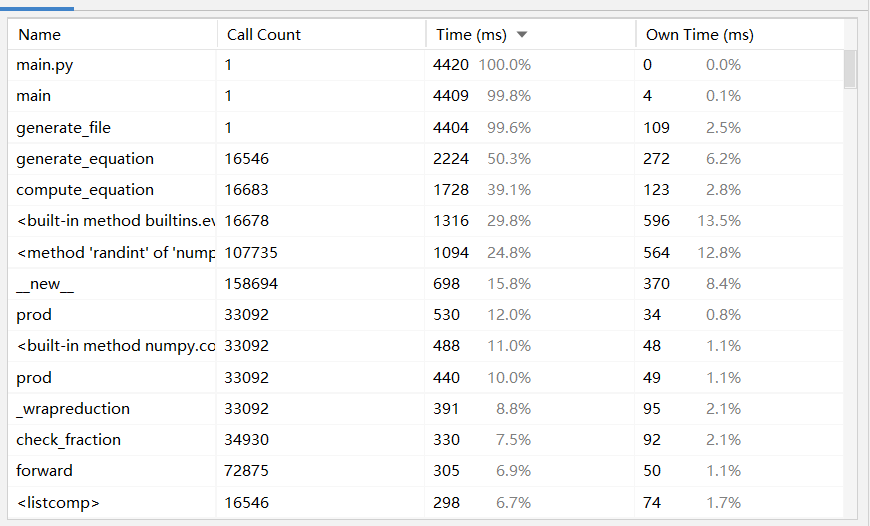
- 为了使用pycharm自带的插件来进性效能分析,修改了参数传入的方式。
- '-n','10000','-r','10'
![]()
- 可以看出,耗时最多的是 generate_file 函数,这个函数的功能是将式子查重并写入文件
。查重需要遍历二叉树,时间应该是最长的,很遗憾暂时找不到优化的方法来减少时间。而
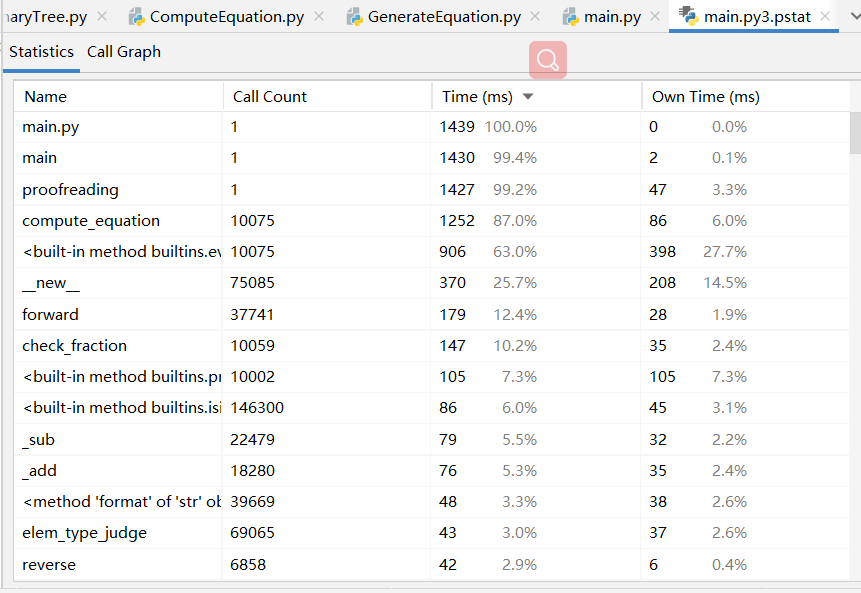
generate_equation 是生成随机式子,几乎也要占一半,毕竟是项目的核心函数之一。 - '-e', 'Exercises.txt', '-a', 'Answers.txt'
![]()
- 而计算式子答案并校对中,proofreading 函数是计算式子答案并校对答案,把得分放入Grade.txt文件中,耗时也是最多的。
- '-n','10000','-r','10'
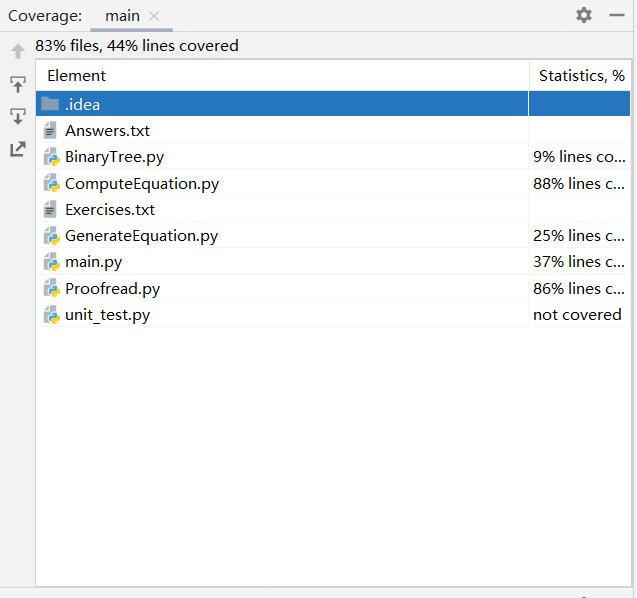
4.2代码覆盖率:
- 生成式子:
![]()
- 校对答案:
![]()
- 以上代码运行时用到的主要函数不同,在不同运行阶段的代码覆盖率也有所不同。例如在校对答案中主要用到的时 proofreading 函数,其中 proofreading 的覆盖率是比生成式子的主要函数要高出许多的。

5.模块单元测试及说明:
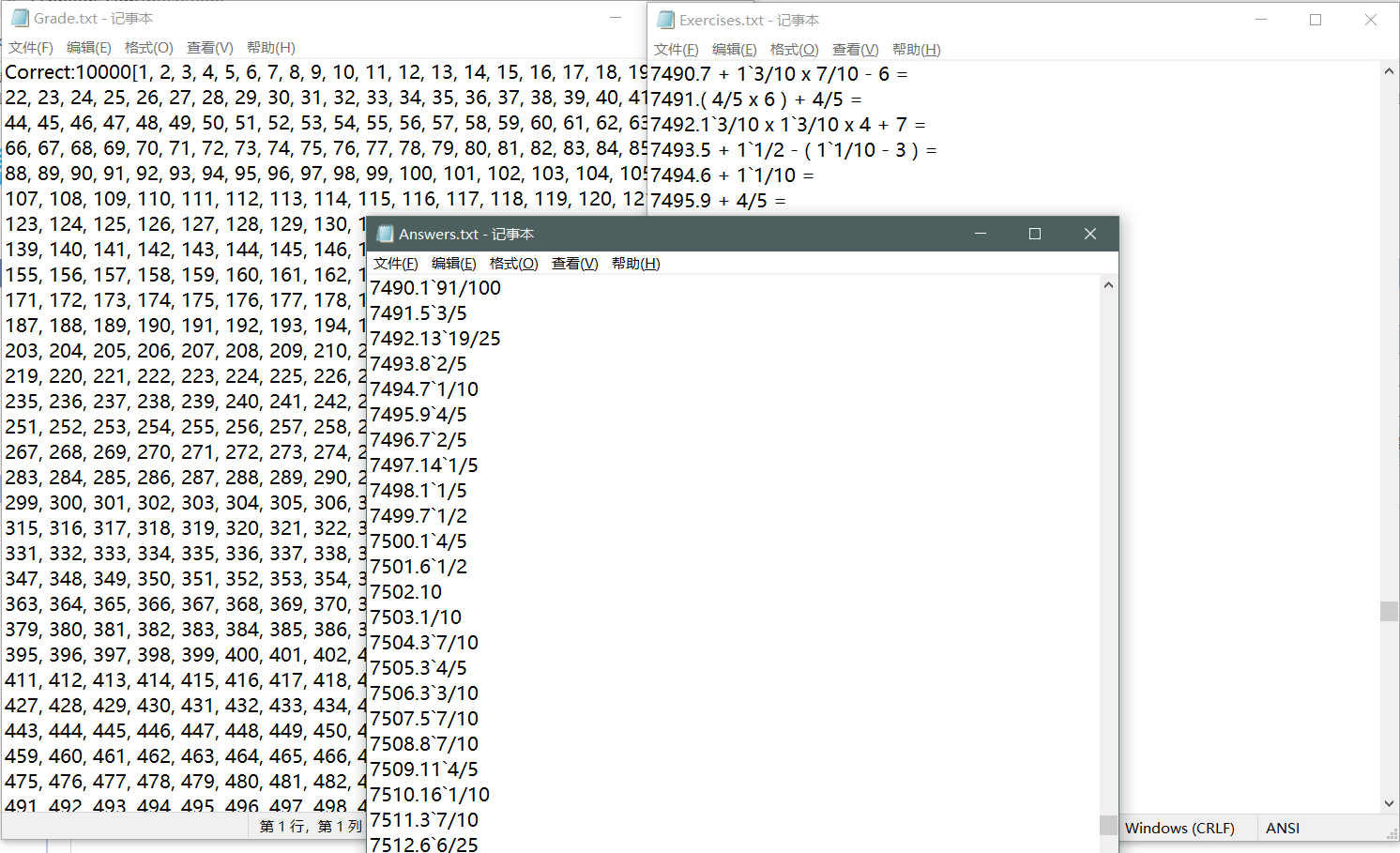
- 10000道题目,数的范围在10以内:
![]() (截取部分)
(截取部分) - 以第7490道题目来说,7 + 1·3/10 x 7/10 - 6 = 1.91 转化为带分数则是 1·91/100,答案正确
- 单元测试:
![]() 引用 unittest 模块
引用 unittest 模块
![]() (截取部分单元测试)
(截取部分单元测试)
 (截取部分)
(截取部分) 引用 unittest 模块
引用 unittest 模块 (截取部分单元测试)
(截取部分单元测试)6.项目小结:
项目成员(冯子垚):
个人反思:
- 结对体验对我来说是从来没有的,是一次奇妙的体验,能感受到每个人都有不同的闪光点,这次来说是一次愉快的合作过程。
- 图形化界面尚且不熟练,所以没有用上,节省了不少时间,但是图形化界面对用户来说是很好的交互方式,希望以后要将图形化界面用在项目上。
项目成员(连婉玲):
个人反思:
- 第一次体验结对项目,感受很新奇,也在这过程中感受到了合作的重要性。
- 这也是我第一次用python写代码,由于对python的不熟悉,刚开始看了很多别人的源代码才开始写,好在python比较简单易懂,所以很快上手。整个过程最困难的就是发现bug和改bug,还好同伴给了我些提醒和建议,所以顺利解决。总的来说,这是一次愉快的合作过程。
7.PSP表:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 25 | 40 |
| Estimate | 估计这个任务需要多少时间 | 15 | 30 |
| Development | 开发 | 300 | 380 |
| Analysis | 需求分析 (包括学习新技术) | 45 | 80 |
| Design Spec | 生成设计文档 | 20 | 40 |
| Design Review | 设计复审 | 15 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| Design | 具体设计 | 60 | 75 |
| Coding | 具体编码 | 300 | 400 |
| Code Review | 代码复审 | 30 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 180 |
| Reporting | 报告 | 40 | 60 |
| Size Measurement | 计算工作量 | 10 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 60 |
| 合计 | 970 | 1465 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号