【并发编程】高并发相关技术
高并发之扩容思路
垂直扩容(纵向扩展):提高系统部件能力
水平扩容(横向扩展):增加更多系统成员来实现
读操作扩展:memcache、redis、CDN等缓存
写操作扩展:Cassandra、Hbase等
高并发之缓存思路
缓存特征
命中率:命中数/(命中数+未命中数)
最大元素(空间)
清空策略:FIFO, LFU, LRU, 过期时间,随机等
缓存命中率影响因素
业务场景和业务需求
缓存的设计(粒度和策略)
缓存容量和基础设施
缓存分类和应用场景
本地缓存:编程实现(成员变量、局部变量、静态变量)、Guava Cache
分布式缓存:Memcache、Redis
高并发场景下缓存的常见问题
缓存一致性
不一致的场景
更新数据库成功->更新缓存失败->数据不一致
更新缓存成功->更新数据库失败->数据不一致
更新数据库成功->淘汰缓存失败->数据不一致
淘汰缓存成功->更新数据库失败->查询缓存miss
缓存并发问题
使用锁

缓存穿透(击穿)问题
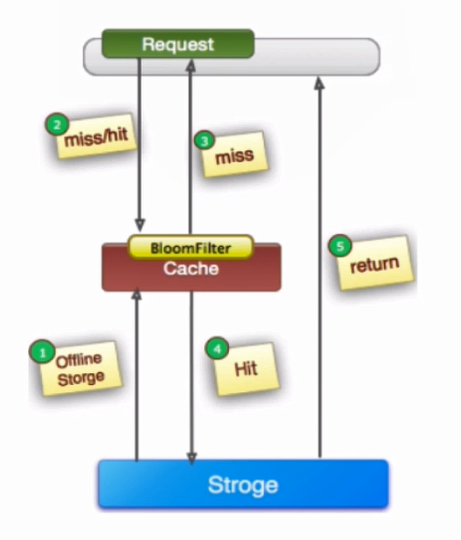
解决方案:
缓存空对象:对查询结果为空的对象也进行缓存,如果是集合,可以缓存一个空集合
如果是缓存单个对象,可以通过对象标识区分,防止请求击穿到数据库。这种方式实现成本低
适合命中不高但是可能频繁更新的数据。
单独过滤处理:对所有可能对应数据为空的对象单独存放,并在请求前拦截,防止请求击穿到数据库。
这种方式实现复杂,适合命中不高,更新不频繁的数据。
缓存的雪崩问题
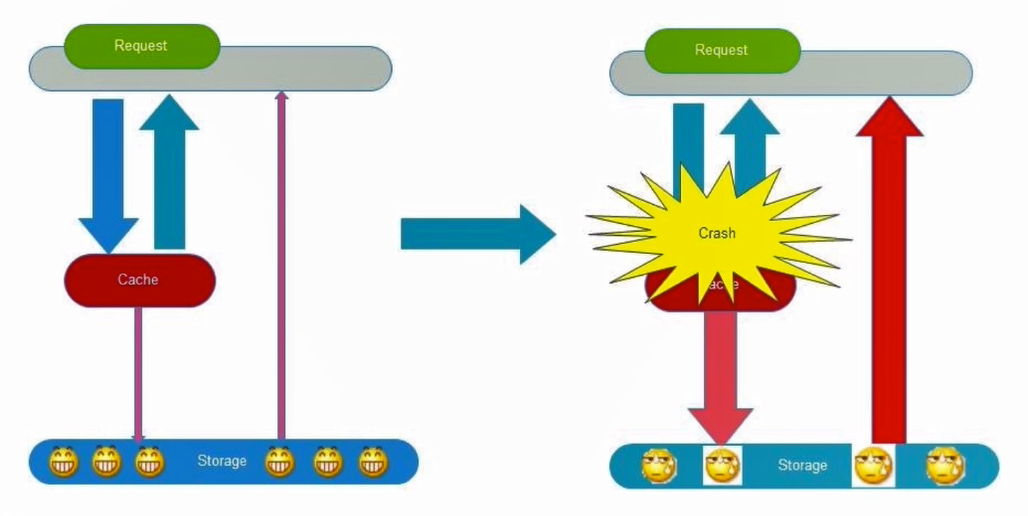
限流、降级、熔断、多级缓存
高并发之消息队列思路
消息队列
开始流程A->发送消息A1到队列->消息A1被处理->处理消息A1(处理流程A)
消息队列特性
业务无关:只做消息分发
FIFO:先投递先到达
容灾:节点的动态增删和消息的持久化
性能:吞吐量提升,系统内部通信效率提高
为什么需要消息队列
【生产】和【消费】的速度或稳定性等因素不一致
消息队列的好处
业务解耦:基于消息的应用关心的是通知不是处理
最终一致性:两个系统最终状态一致,如转账流程,转入和转出要同时成功或失败。(跨JVM一致性问题的通用解决方案包括最终一致性和强一致性(分布式事务,技术难度高))实现相对简单,通过记录和补偿方式处理。状态包括成功、失败(记录、重试)、不确定。最终一致性不是消息队列必备特性,但是可以通过消息队列实现最终一致性。
Kafka等消息队列在设计层面上就有丢消息的可能性,如定时刷盘或掉电都可能丢消息,哪怕只有千分之一可能丢消息也要使用其他手段保证结果正确。
广播
错峰与流控
由于部件或系统性能不一致导致处理能力不同,需要消息队列进行错峰和流控。
消息队列不是万能的,对于需要强事务保证而且延时很敏感的RPC远程调用优于消息队列。对于一些无关痛痒或者对于别人非常重要但是对自己不是那么关心的情事,可通过消息队列做;支持最终一致性的消息队列能够用来处理延迟不那么敏感的分布式事务场景,相对于笨重的分布式事务可能是更优的处理方式;当上下游处理能力存在差异时,可以利用消息队列做一个漏斗,在下游部件有能力处理时再分发,同时如下下游有很多系统关心当前系统发出的通知的时候,也适用消息队列。
消息队列举例
Kafka
RabbitMQ
高并发之应用拆分思路
应用拆分
根据业务功能拆分:
如一个股票系统包括用户信息、开户、股票行情、交易、订单等功能,可以拆分为交易中心(股票买入与卖出)、账户中心(流程处理、定时任务)、用户中心(基础数据维护)、行情中心(定时任务、流程处理)、通知中心(短信、邮件推送)。
优点:便于管理维护。
缺点:增加了成本和开销。
应用拆分基本原则
业务优先
循序渐进
兼顾技术:重构、分层
可靠测试
应用拆分-思考
应用之间通信:RPC(dubbo等)--强一致性、消息队列--最终一致性
应用之间数据库设计:每个应用都有独立的数据库
避免事务操作跨应用
应用拆分-常用组件
服务化 Dubbo
消息队列
微服务 Spring Cloud
高并发之应用限流思路
应用限流
一定时间内代码执行的次数
应用限流--算法
计数器法
临界问题很致命
滑动窗口算法的一种
滑动窗口
时间窗
漏桶算法
接口以恒定速率处理请求
令牌桶算法
可以很好地处理临界问题
高并发之服务降级与服务熔断思路
服务降级
对一些服务和页面有策略的降级,以此缓解保证部分或大部分用户得到响应。若应用处理不了了请求,返回一个默认结果。
服务熔断
软件系统里由于某种原因造成系统过载,为防止系统故障采取的一种保护措施,也称为过载保护。
分类:
自动降级:超时、失败次数、故障、限流
人工降级:秒杀、双11大促等
服务降级与服务熔断对比
共性:目的相同(可用性可靠性方面)、最终表现、粒度(服务级,也有更细粒度)、自治性要求高
区别:触发原因不同(熔断由于下游故障引起、降级是从整体负荷考虑)、管理目标层次不同(熔断是框架级处理每个微服务都需要、降级一般需要对业务有层级区分,降级一般从最外围服务开始)、实现方式不同
服务降级要考虑的问题
核心服务、非核心服务
是否支持降级,降级策略
业务放通场景,策略
Hystrix可用于实现服务降级
高并发之数据库切库分库分表思路
数据库瓶颈
单个库数据量太大(1T~2T):多个库
单个数据库服务器压力过大、读写瓶颈:多个库
单个表数据量过大:分表
数据库切库
切库基础及实际运用:读写分离
一般采用一个主库(实时查询),多个从库(非实时查询)
可以使用Spring MVC、AOP、注解实现。(参考手记)
数据库支持多个数据源与分库
支持多数据源、分库
一个数据库支持多数据源(参考手记)
数据库分表
当单表数据量过大时,大到做优化和索引后还影响正常业务时就需要分表。(需要提前设计)
单表数据量过千万时,基本查询等操作性能会大幅下降
横向(水平)分表:表结构相同
纵向(垂直)分表:根据数据活跃度分表
数据库分表:MyBatic分表插件shrdbatis2.0(参考手记)
高并发之高可用手段
任务调度系统分布式:elastic-job(当当开源) + zookeeper
主备切换:apache curator + zookeeper 分布式锁实现
两台服务器交替作为主备服务器
监控报警(告警)机制(参考手记)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号