

团队-爬虫豆瓣top250项目-开发文档
地址:https://gitee.com/ningshuyoumeng/TuanDui-PaChongDouBantop250XiangMu-MoKuaiKaiFa
爬取豆瓣——文档
一。开发语言的选择:
本次系统设计选用Python高级编程语言,其原因:Python易学易用、语法简单、url请求和字符串处理都非常便捷,为高效数据采集的流行工具。
二。本次系统实现的需求(功能):
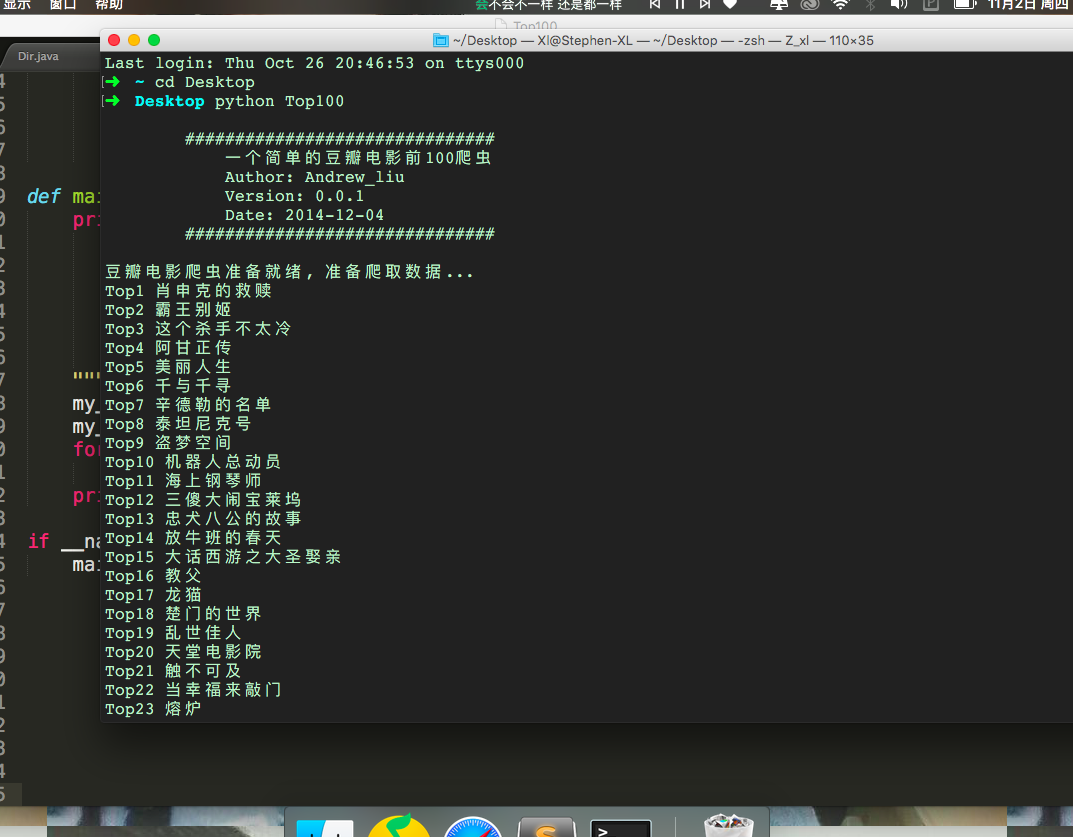
要采集豆瓣电影网所有的电影信息及其排名。
三。实现功能的理论(初步设想):
浏览器把资源文件渲染成了我们看到的网页的样子,我们如果要取出网页中的数据,就需要拿到资源文件。发起Http请求,然后解析服务器返回的响应,就是爬虫的工作,所以爬虫的第一步是获取html文件。
四。爬虫实现的基本工作:
- 获取目标页面源码 -> 调用对应的类库
- 解析html文件,提取出自己想要的信息 -> 使用正则表达式解析字符串或者调用解析html的库
—— —— —— —— —— ——以上是整个系统的架构,本次只是实现部分模块的开发—— —— —— —— —— —— ——
五。部分模块的实现:
Attributes:
page: 用于表示当前所处的抓取页面
cur_url: 用于表示当前争取抓取页面的url
datas: 存储处理好的抓取到的电影名称
_top_num: 用于记录当前的top号码
部分代码:
class DouBanSpider(object) :
def __init__(self) :
self.page = 1
self.cur_url = "http://movie.douban.com/top250?start={page}&filter=&type="
self.datas = []
self._top_num = 1
print "豆瓣电影爬虫准备就绪, 准备爬取数据..."
def get_page(self, cur_page) :
url = self.cur_url
try :
my_page = urllib2.urlopen(url.format(page = (cur_page - 1) * 25)).read().decode("utf-8")
except urllib2.URLError, e :
if hasattr(e, "code"):
print "The server couldn't fulfill the request."
print "Error code: %s" % e.code
elif hasattr(e, "reason"):
print "We failed to reach a server. Please check your url and read the Reason"
print "Reason: %s" % e.reason
return my_page
def find_title(self, my_page) :
temp_data = []
movie_items = re.findall(r'<span.*?class="title">(.*?)</span>', my_page, re.S)
for index, item in enumerate(movie_items) :
if item.find(" ") == -1 :
temp_data.append("Top" + str(self._top_num) + " " + item)
self._top_num += 1
self.datas.extend(temp_data)
def start_spider(self) :
while self.page <= 4 :
my_page = self.get_page(self.page)
self.find_title(my_page)
self.page += 1
def main() :
my_spider = DouBanSpider()
my_spider.start_spider()
for item in my_spider.datas :
print item
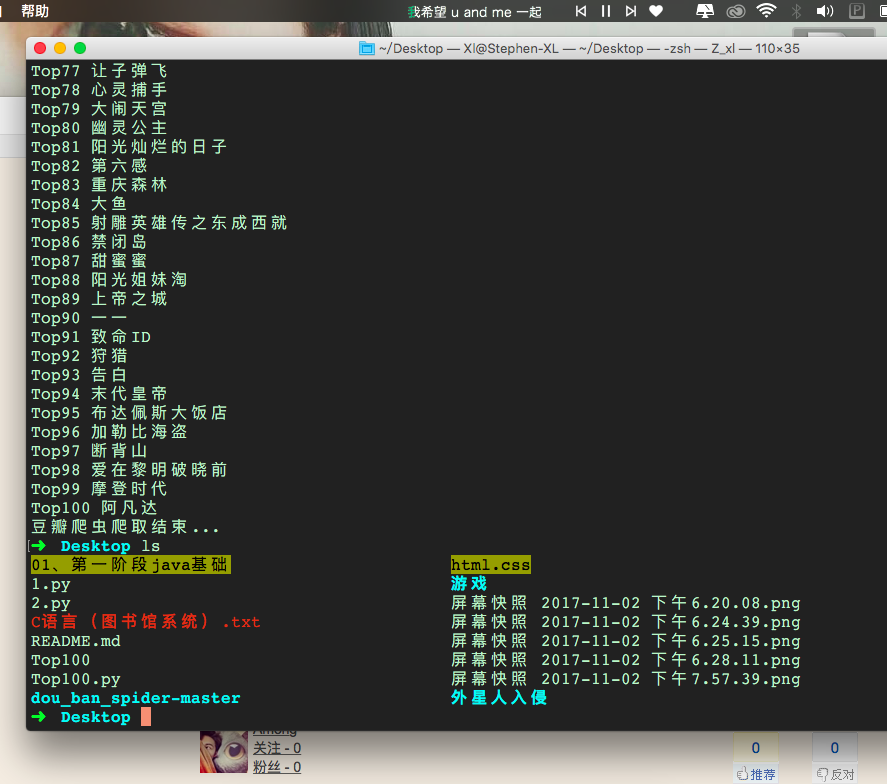
print "豆瓣爬虫爬取结束..."
if __name__ == '__main__':
main()
六。功能:
本次实现了爬取豆瓣Top100名的电影
(尚未实现的功能):
1.本次模块并未实现电影详细信息(如“导演,评价,分数,演员等)
2。并没有存在数据库里或者Excel中
注意:
为了测试该模块,并没有爬取Top250个电影,只测试Top100!!!!
图例:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号