正表达式
1、正则表达式语法
参考资料:
正则表达式语法总结
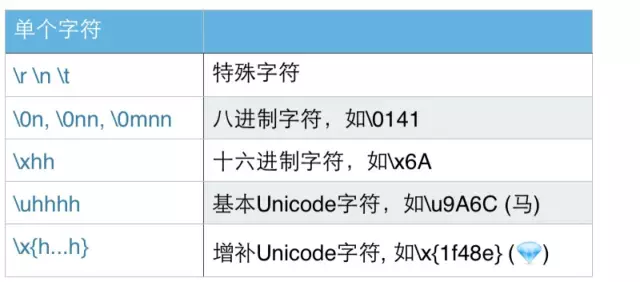


注:加?时表示惰性匹配,即匹配的串尽可能短。如对于aabab,分别用 a.*b、a.*?b 匹配时,前者只有一个匹配结果:aabab,而后者有两个匹配结果:aab、ab。其他通配符的惰性形式同理。

注:
分组命名也可以写为(?'name'X),引用时语法为 \k'name'
使用小括号指定一个子表达式后,匹配这个子表达式的文本(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。默认情况下,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。

注:
\b 匹配单词的开头或结尾、\B匹配不是开头和结尾的位置(也就是单词的分界处,如"good idea"中的空格);^匹配单词开头、$匹配单词结尾。
^ \A 的区别:前者匹配开头、后者匹配字符串开头。如对于"\n\nabcd",两者匹配到的分别是 index为0、2的元素左边的边界
$ \Z \z 的区别:如对于"abc\nde\n",前两者匹配到的分别是 index为6、3的元素左边的边界,而\z匹配到的是 index为6的元素的右边的边界
断言
正零宽断言:
- (?=exp)也叫零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp(预测右包含)。比如\b\w+(?=ing\b),匹配以ing结尾的单词的前面部分(除了ing以外的部分),如查找I'm singing while you're dancing.时,它会匹配sing和danc。
- (?<=exp)也叫零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式exp(预测左包含)。比如(?<=\bre)\w+\b会匹配以re开头的单词的后半部分(除了re以外的部分),例如在查找reading a book时,它匹配ading。
综合例子:(?<=\s)\d+(?=\s)匹配以空白符间隔的数字(不包括这些空白符)。
负零宽断言:
- (?!exp)也叫零宽度负预测先行断言,断言此位置的后面不能匹配表达式exp(预测右不包含)。例如:\d{3}(?!\d)匹配三位数字,而且这三位数字的后面不能是数字;\b((?!abc)\w)+\b匹配不包含连续字符串abc的单词。\b\w*q(?!u)\w*\b匹配出现了q但q后面不能是u的单词,如果用\b\w*q[^u]\w*\b则会有问题,因为当q位于一个单词末尾时分隔符会被[^u]匹配从而单词也被匹配,如Iraq fighting整个都会被匹配。
- (?<!exp)也叫零宽度负回顾后发断言,来断言此位置的前面不能匹配表达式exp(预测左不包含)。如(?<![a-z])\d{7}匹配前面不是小写字母的七位数字。
综合例子:(?<=<(\w+)>).*(?=<\/\1>)匹配不包含属性的简单HTML标签内里的内容。(?<=<(\w+)>)指定了这样的前缀:被尖括号括起来的单词(比如可能是<b>),然后是.*(任意的字符串),最后是一个后缀(?=<\/\1>)。注意后缀里的\/,它用到了前面提过的字符转义;\1则是一个反向引用,引用的正是捕获的第一组,前面的(\w+)匹配的内容,这样如果前缀实际上是<b>的话,后缀就是</b>了。整个表达式匹配的是<b>和</b>之间的内容(再次提醒,不包括前缀和后缀本身)。

2、常用正则表达式
(参考自常用正则表达式)
说明:正则表达式通常用于两种任务:1.验证,2.搜索/替换。用于验证时(如验证邮箱或电话号码),通常需要在表达式前后分别加上^和$,以匹配整个待验证字符串;搜索/替换时是否加上此限定则根据搜索的要求而定,此外,也有可能要在前后加上\b而不是^和$。此表所列的常用正则表达式,除个别外均未在前后加上任何限定,请根据需要,自行处理。
| 说明 | 正则表达式 |
|---|---|
| 网址(URL) | [a-zA-z]+://[^\s]* |
| IP地址(IP Address) | ((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?) |
| 电子邮件(Email) | \w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)* |
| QQ号码 | [1-9]\d{4,} |
| HTML标记(包含内容或自闭合) | <(.*)(.*)>.*<\/\1>|<(.*) \/> |
| 密码(由数字/大写字母/小写字母/标点符号组成,四种都必有,8位以上) | (?=^.{8,}$)(?=.*\d)(?=.*\W+)(?=.*[A-Z])(?=.*[a-z])(?!.*\n).*$ |
| 日期(年-月-日) | (\d{4}|\d{2})-((1[0-2])|(0?[1-9]))-(([12][0-9])|(3[01])|(0?[1-9])) |
| 日期(月/日/年) | ((1[0-2])|(0?[1-9]))/(([12][0-9])|(3[01])|(0?[1-9]))/(\d{4}|\d{2}) |
| 时间(小时:分钟, 24小时制) | ((1|0?)[0-9]|2[0-3]):([0-5][0-9]) |
| 汉字(字符) | [\u4e00-\u9fa5] |
| 中文及全角标点符号(字符) | [\u3000-\u301e\ufe10-\ufe19\ufe30-\ufe44\ufe50-\ufe6b\uff01-\uffee] |
| 中国大陆固定电话号码 | (\d{4}-|\d{3}-)?(\d{8}|\d{7}) |
| 中国大陆手机号码 | 1\d{10} |
| 中国大陆邮政编码 | [1-9]\d{5} |
| 中国大陆身份证号(15位或18位) | \d{15}(\d\d[0-9xX])? |
| 非负整数(正整数或零) | \d+ |
| 正整数 | [0-9]*[1-9][0-9]* |
| 负整数 | -[0-9]*[1-9][0-9]* |
| 整数 | -?\d+ |
| 小数 | (-?\d+)(\.\d+)? |
| 不包含abc的单词 |
\b((?!abc)\w)+\b |
| 用尖括号括起来的以a开头的字符串 |
<a[^>]+> |
文件名不能包含的特殊字符:不同的文件系统的保留字符可能不一样,故这里取一般有交集的;此外,这里还考虑到文件通过URL下载的情况,此时文件名最好不要有一些特殊字符以免在URL中被浏览器忽略不传给后端(如URL中 # 后面的内容不会传给后端)。
英文环境: `~!@#$%^&*=+\\|;:'",/?
中文环境: ·~!#¥%……&*——=+、|;:‘“,。、?
非打印字符: \r\n\t
说明:
如何确定的?键盘上的非字母数字字符,分别有中英文两种情况;但允许有 【横线、空格、下划线、英文句号、中英文三种括号、中英文尖括号】 等。
两个环境上述字符有交集,如两个环境下的加号字符是一样的,使用时取它们并集即可。
不取并集,直接通过或逻辑拼在一起也可,最终结果: [`~!@#$%^&*=+\\|;:'",/?]|[·~!#¥%……&*——=+、|;:‘“,。、?]|[\n|\r|\t] 。
"^(?=.*\\d)(?=.*[A-Z])(?=.*[a-z])([a-zA-Z\\d]{6,20})$";// 大小写字母、数字均至少一个,总共6到20个
3、正则表达式的Java API
正则表达式的字符串表示
(转义字符相关:http://www.cnblogs.com/z-sm/p/6944850.html)
在Java字符串中一出现反斜杠Java就会将之当做ascll转义字符的开始去解析之,因此其与之后的字符不能组成合法的ascll转义字符就会报错。
在Java中没有什么特殊的语法能直接表示正则表达式,需要用字符串表示之(即在字符串里依次表示正则表达式里的每个字符)。在正则语法中有几个元字符( . $ | ( ) [ { ^ ? * + \ )有特殊含义(如 * 在正则表达式中表示匹配0或多个),根据正则语法若要将这些字符当做普通字符而非元字符来对待则需要加斜杠转义(如当我们想匹配该字符本身,则应该在模式定义中对之转义即 \* ),显然用字符串表示这些元字符的转义字符时(如 "\*")会因为解析不成ASCLL转义字符而报错,解决方法如上所述改为 "\\*" 。一个更极端的例子:在字符串中 \ 是元字符,为了在字符串中表示正则表达式的 \ 就需要两个斜杠即 \\ ;而正则表达式中 \ 也是元字符,为了要匹配 \ 自身,根据正则语法需转义为 \\ ,此时字符串表示就需要四个斜杠即 \\\\ 。
正则表达式中可能出现两种转义字符:预定义的一些正则表达式如表示数字的\d表示字符的\w等、正则语法的元字符当普通字符对待时转义字符(特殊转普通)、ASCLL中的转义字符(普通转特殊)。
总结(正则表达式的字符串形式):根据正则语法定义正则表达式,然后将表达式转为字符串表示:一个简单的规则是正则表达式中的任何一个'\',在字符串中,需要替换为两个'\',(对于ASCLL转义字符斜杠替不替换均可)。更简单的方式是在IDE(如Eclipse)中将定义好的正则表达式复制到String类型变量的值中,会自动添加 '\' 。
Java正则表达式特殊字符匹配示例
String regEx = "[ _`~!@#$%^&*()+=|{}':;',\\[\\].<>/?~!@#¥%……&*()——+|{}【】‘;:”“’。,、?]|\n|\r|\t";
System.out.println(Pattern.compile(regEx).matcher(“hello>”).find());
regEx="^(0\\d{1}|1\\d{1}|2[0-3]):([0-5]\\d{1})$"; //24小时制正则,不能省略前导0
获取多个匹配结果示例:(更多可参阅:http://www.runoob.com/java/java-regular-expressions.html)
public class RegexMatches { private static final String REGEX = "\\bcat\\S*"; private static final String INPUT = "cat1 cat2 cat3 cattie cat4"; public static void main(String args[]) { Pattern p = Pattern.compile(REGEX); Matcher m = p.matcher(INPUT); // 获取 matcher 对象 System.out.println(m.groupCount()); while (m.find()) { System.out.println(m.group(0));//依次输出INPUT中各词 } } }
关于Matcher m中的groupCount:若匹配成功,则:
务必在调用group之前调用find方法,相当于查找之后才会有组,否则会报错No match found。
m.group()与m.group(0)一样,表示匹配到的整个串;可见,即使pattern中没有括号(即分组),只要匹配成功group(0)也是有值的;
grouCount与pattern中的括号对数一样。假设groupCount为n,则group 1,2,...n分别表示从左到右左括号对应的分组。
比较特殊的例子如:(/api/resource/public\?b=(\S*?)\&o=([^'"]*)) | (/api/resource/public/(\S*?)/([^'"]*)) 不论是左边的匹配到还是右边的匹配到,groupCount都是6,只不过若左边匹配到则后三个分组值为null,vice verse。
另外注意部分匹配与全部匹配:
区别:参阅:https://stackoverflow.com/questions/4450045/difference-between-matches-and-find-in-java-regex
m.find()表示部分匹配,每次调用后会从上次匹配位置的后面继续匹配,除非中间调用m.reset()进行了重置
m.matches()表示全部匹配,要求被匹配的串与给定的正则全部匹配(相当于内部在正则表达式前后分别加上了 ^ 和 $,若待匹配串本身首尾已由这两字符则不会加)。如上面例子中若用matches,则返回的为false。注:java中的@Pattern constraint指定的regexPattern默认就是用此种方式来匹配的。
示例:如下示例用 find() 或 matches() 效果等价。
"^(?=.*\\d)(?=.*[A-Z])(?=.*[a-z])([a-zA-Z\\d]{6,20})$" :密码——6到12位大小写字母和数字组成且每种必须至少一个字符。若将最后一个分组放到首部则对于"Ss123456"用find可匹配但用matches匹配不了。
"^(?=1.*)([\\d]{11})$" :手机号——以1开头的11位数字。
综合使用示例
这里以解析断点下载(见见https://tools.ietf.org/html/rfc7233、https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Range_requests)的request range为例,相关代码:


1 /** in、out由调用者负责关闭 */ 2 private void downloadWithResum(InputStream in, OutputStream out, long fileTotalLength, String newEtagStr) 3 throws Exception { 4 // 借助Etag判断断点续传前后资源是否发生变化 5 String oldEtag = request.getHeader(HttpHeaders.IF_NONE_MATCH); 6 response.setHeader(HttpHeaders.ETAG, newEtagStr); 7 8 String rangeHeaderVal = request.getHeader(HttpHeaders.RANGE); 9 // 不启用断点续传 或 启用了但没有Range头 或 启用了但是资源发生了变化,则直接下载完整数据 10 if (!resumeDownloadEnabled || null == rangeHeaderVal || (null != oldEtag && !newEtagStr.equals(oldEtag))) { 11 { 12 response.setStatus(HttpServletResponse.SC_OK); 13 response.setContentLengthLong(fileTotalLength); 14 15 // buffer write背后的实现就是循环调单字节的write、buffer read同理。所以用buffer 读写的意义是? 16 byte[] buffer = new byte[20 * 1024]; 17 int length = 0; 18 while ((length = in.read(buffer)) != -1) { 19 out.write(buffer, 0, length); 20 } 21 } 22 } 23 // 断点续传,见https://tools.ietf.org/html/rfc7233、https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Range_requests 24 else { 25 26 // 有传范围,开始解析请求的范围。请求范围格式:bytes= 范围或范围列表 27 // bytes后的范围示例:"1-2"、"3-"、"-3"、"1-2,3-4"、"1-2,3-"、"1-2,-3"。至少须有一个范围;允许指定多个范围;左右边界未成对出现的范围最多只能有一个且只能在末尾 28 // 相应的pattern正则为 ^bytes=(?=[-0-9])(,?(\d+)-(\d+))*?(,?(\d+)-|,?-(\d+))?$ 29 // 第二个问号表示惰性匹配、其他问号表示元素(逗号或区间)为0或1个;第一个断言用于防止""被当成合法范围 30 String rangeHeaderValPatternStr = "^bytes=(?=[-0-9])(,?(\\d+)-(\\d+))*?(,?(\\d+)-|,?-(\\d+))?$"; 31 Matcher m = Pattern.compile(rangeHeaderValPatternStr).matcher(rangeHeaderVal); 32 if (!m.matches()) {// 不符合范围或范围列表格式,结束 33 response.setStatus(HttpServletResponse.SC_REQUESTED_RANGE_NOT_SATISFIABLE); 34 return; 35 } 36 37 // 以下表示所传范围或范围列表符合格式,故开始处理每个范围段 38 String rangeSegmentPatternStr = "((\\d+)-(\\d+))|(\\d+)-|-(\\d+)";// 与上面的rangeHeaderValPatternStr对应,获取其中的每个范围 39 m = Pattern.compile(rangeSegmentPatternStr).matcher(rangeHeaderVal); 40 List<Long[]> rangeSegmengs = new ArrayList<>();// 每个元素为包含两个元素的数组,分别为起、止位置 41 while (m.find()) { 42 long startBytePos = -1, endBytePos = -1; 43 if (m.group(1) != null) {// 类似"1-2"这种范围 44 startBytePos = Long.parseLong(m.group(2)); 45 endBytePos = Long.parseLong(m.group(3)); 46 } else if (m.group(4) != null) {// 类似"3-"这种范围 47 startBytePos = Long.parseLong(m.group(4)); 48 endBytePos = fileTotalLength - 1; 49 } else if (m.group(5) != null) {// 类似"-3"这种范围 50 startBytePos = fileTotalLength - Long.parseLong(m.group(5)); 51 endBytePos = fileTotalLength - 1; 52 } 53 54 // 范围越界 55 if (startBytePos > endBytePos || startBytePos < 0 || endBytePos >= fileTotalLength) { 56 response.setStatus(HttpServletResponse.SC_REQUESTED_RANGE_NOT_SATISFIABLE); 57 return; 58 } else { 59 rangeSegmengs.add(new Long[] { startBytePos, endBytePos }); 60 } 61 } 62 63 // 以下表示各范围均合法,故先进行区间合并再对根据合并后的各区间下载文件 TODO 改为借助本地文件缓存,避免每次访问远程文件 64 mergeOverlapRange(rangeSegmengs); 65 if (rangeSegmengs.size() == 0) { 66 return; 67 } 68 69 // 浏览器貌似不支持multipart/byteranges,故传多范围时只考虑最后一个范围 70 long startBytePos = rangeSegmengs.get(rangeSegmengs.size() - 1)[0]; 71 long endBytePos = rangeSegmengs.get(rangeSegmengs.size() - 1)[1]; 72 73 response.setStatus(HttpServletResponse.SC_PARTIAL_CONTENT); 74 response.setHeader(HttpHeaders.ACCEPT_RANGES, "bytes"); 75 response.setContentLengthLong(endBytePos - startBytePos + 1); 76 response.setHeader(HttpHeaders.CONTENT_RANGE, 77 String.format("bytes %s-%s/%s", startBytePos, endBytePos, fileTotalLength)); 78 79 // 略过不要的内容 80 in.skip(startBytePos); 81 // 返回目标内容 82 try { 83 byte[] buffer = new byte[20 * 1024]; 84 int bfNextPosIndex = 0; 85 for (long i = startBytePos; i <= endBytePos; i++) { 86 if (bfNextPosIndex == buffer.length) { 87 out.write(buffer, 0, buffer.length); 88 bfNextPosIndex = 0; 89 } 90 91 buffer[bfNextPosIndex++] = (byte) in.read(); 92 93 } 94 out.write(buffer, 0, bfNextPosIndex); 95 } catch (IOException e) { 96 // 浏览器加载音视频时,为获取总数据大小,第一次会发"bytes=0-"的请求且收到响应头后立马关闭连接,导致服务端写数据出现Broken 97 // pipe,故忽略之,其他抛到上层 98 if ("Broken pipe".equals(e.getMessage())) { 99 log.error("'Broken pipe' when writing partial content to OutputStream"); 100 } else { 101 log.error(e.getMessage(), e); 102 } 103 } 104 105 } 106 } 107 108 /** 区间合并的算法 */ 109 private List<Long[]> mergeOverlapRange(List<Long[]> ranges) { 110 if (null == ranges || ranges.size() == 0) { 111 return null; 112 } 113 // 区间按左值排序 114 ranges = ranges.stream().sorted((range1, range2) -> (int) (range1[0] - range2[0])).collect(Collectors.toList()); 115 // 遍历并合并区间 116 for (int i = 1; i < ranges.size(); i++) { 117 Long[] curRange = ranges.get(i); 118 Long[] preRange = ranges.get(i - 1); 119 // 说明有交集,则更新前区间的右值并移除当前区间 120 if (curRange[0] <= preRange[1]) { 121 if (preRange[1] < curRange[1]) { 122 preRange[1] = curRange[1]; 123 } 124 ranges.remove(i); 125 i--; 126 } 127 } 128 return ranges; 129 130 }
更多参考资料:老马说编程——正则表达式(中)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号