Jackson系列
详情参阅:Jackson系列

注:下文涉及到的 jackson 源码的版本为 2.11.0
1 Jackson介绍
(对应 Jackson系列 文章1)
Jackson是一个基于JVM平台(所以支持Java、Scala、Kotlin等语言)的数据(不限于JSON格式的数据)序列化、反序列化工具集,包括:JSON解析器(读)/ JSON生成器(写)、数据绑定库(POJOs to and from JSON);并且提供了相关模块来支持 Avro、BSON、CBOR、CSV、Smile、Properties、Protobuf、XML、YAML等数据格式,甚至还支持大数据格式模块的设置。
特性
性能且稳定:低内存占用,对大/小JSON串解析、大/小对象的序列化表现均很优秀。
流行度高:是很多流行框架的默认选择。
易使用:提供高层次的API,极大简化了日常使用的难度。
无需自己手动创建映射:内置了绝大部分序列化时和Java类型的映射关系。
干净的JSON:创建的JSON具有干净、紧凑、体积小等特点。
无三方依赖:仅依赖于JDK。
可扩展性强:与GSON等其他库相比的另一大特点是具有很强的可扩展性。
Spring生态加持:jackson是Spring家族的默认JSON/XML解析器。
其他:考虑安全性,预防JSON解析时的Dos攻击(ByteQuadsCanonicalizer)等。
模块
三个核心模块:(说明:核心模块的groupId均为:<groupId>com.fasterxml.jackson.core</groupId>,artifactId见下面各模块所示)
json解析和生成的核心模块(jackson-core):主要包括JsonParser、JsonGenerator、JsonFactory三个内容,分别用于解析JSON数据、生成JSON数据、配置和构建JsonParser与JsonGenerator。此模块是jackson其他所有模块的基础,属于low-level API。jackson-core 模块提供了两种处理JSON的方式(纵缆整个Jackson共三种):
数据流式API:读取并将JSON内容写入作为离散事件 -> JsonParser读取数据,而JsonGenerator负责写入数据。
树模型:JSON文件在内存里以树形式表示。此种方式也很灵活,它类似于XML的DOM解析,是层层嵌套的。这种模式下无需定义POJO就可以用它快速读写JSON数据,同时它也可以达到「模糊掉类型的概念」,做到更抽象和更公用。
Annotations标准注解模块(jackson-annotations):包含标准的Jackson注解。
Databind数据绑定模块(jackson-databind):在streaming包上实现数据绑定(和对象序列化)支持,它依赖于上面的两个模块,也是Jackson的high-level API(如ObjectMapper)所在的模块。
实际应用级开发中,我们只会使用到Databind数据绑定模块。
数据类型模块:这些模块为Jackson插件模块(通过ObjectMapper.registerModule()注册),并通过添加序列化器和反序列化器来支持各种常用的Java库数据类型,以便Jackson databind包(ObjectMapper / ObjectReader / ObjectWriter)能够顺利读写/转换这些类型。包括官方维护和非官方维护两类。
官方维护:Guava、HPPC、PCollections、Hibernate、Joda、Java8、JSR310、JSR353 等(groupId统一为:<groupId>com.fasterxml.jackson.datatype</groupId>,且版本号和主版本号保持一致)。
第三方开源维护:jackson-datatype-bolts、jackson-datatype-commons-lang3 等。
数据格式模块:Data format modules(数据格式模块)提供对JSON之外的数据格式的支持。它们中的大多数只是实现streaming API抽象,以便数据绑定组件可以按原样使用。两类(groupId统一为<groupId>com.fasterxml.jackson.dataformat</groupId>,且版本号和主版本号保持一致):它们的artifactId为:<artifactId>jackson-dataformat-[FORMAT]</artifactId>
Avro/CBOR/Ion/Protobuf/Smile(binary JSON) :这些均属于二进制的数据格式,
CSV/Properties/XML/YAML:文本数据序列化和反序列化。例如yaml的jackson-dataformat-yaml
JVM平台其他语言支持:Jackson是一个JVM平台的解析器,因此语言层面不局限于Java本身,还涵盖了另外两大主流JVM语言:Kotlin和Scala。两类(groupId均为:<groupId>com.fasterxml.jackson.module</groupId>,版本号跟着主版本号走):
jackson-module-kotlin:处理kotlin源生类型
jackson-module-scala_[scala版本号]:处理scala源生类型
移动端简化版(Jackson jr):Jackson databind(如ObjectMapper)是通用数据绑定的良好选择,但它占用空间(Jar包大小)和启动开销在移动端等常见下较为笨重,故官方推出了更简单、更小的库——Jackson jr。它仍旧构建在Streaming API之上,但不依赖于databind和annotation。因此,它的大小(jar和运行时内存使用)要小得多,它的API非常紧凑,所以适合APP等移动端
2 Java数据转成JSON数据(jackson-core之 JsonGenerator)
(对应 Jackson系列 文章2)
JsonGenerator是jackson-core提供的JSON数据生成器,用于将Java数据对象转成JSON数据。
在应用开发层面一般不推荐直接使用JsonGenerator(而是用ObjectMapper),因为它的API比较底层比较灵活,因此易错;但如果是框架开发,则很适合用这个(Spring MVC对JSON消息的转换器 AbstractJackson2HttpMessageConverter 就用到了Jackson底层流式API -> JsonGenerator写数据),因为它的性能更高,是ObjectMapper等的基础。

如上图所示,最终负责生成JSON数据的实现类有 WriterBasedJsonGenerator、UTF8JsonGenerator 两种。
WriterBasedJsonGenerator:基于 java.io.Writer 来输出JSON内容,由该Writer来处理字符编码。
UTF8JsonGenerator:该实现类自己对Java数据进行UTF8字符编码,编码后的JSON数据内容直接输出到OutputStream而不是借助Writer输出。
基本使用:
写key:JSON中的key只有String一种类型
写value:Java中的数据类型多种多样,但JSON中只有 【字符串、数值、布尔、null、数组、对象 】6种。
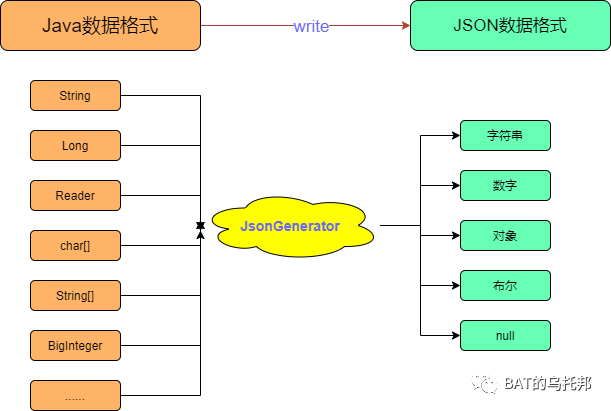
关于JsonGenerator中写key、写value的各种API使用示例可参阅本节首的文章。
writeFieldName
writeString、writeNumber、writeBoolean、writeNull、writeStartArray/writeArray、writeStartObject/writeObject
writeRaw、writeRawValue、writeBinary
等
JsonGenerator的 writeObject/writeTree 方法要求事先给JsonGenerator指定一个编解码器 ObjectCodec/TreeCodec,否则会报错。而Jackson里我们最为熟悉的API ObjectMapper 实际上就是一个ObjectCodec 的唯一实现,实现了序列化和反序列化、POJO、Tree Model 等操作。
(对应 Jackson系列 文章3)
JsonGenerator#Feature 枚举类:


public enum Feature { // Low-level I/O AUTO_CLOSE_TARGET(true), AUTO_CLOSE_JSON_CONTENT(true), FLUSH_PASSED_TO_STREAM(true), // Quoting-related features @Deprecated QUOTE_FIELD_NAMES(true), @Deprecated QUOTE_NON_NUMERIC_NUMBERS(true), @Deprecated ESCAPE_NON_ASCII(false), @Deprecated WRITE_NUMBERS_AS_STRINGS(false), // Schema/Validity support features WRITE_BIGDECIMAL_AS_PLAIN(false), STRICT_DUPLICATE_DETECTION(false), IGNORE_UNKNOWN(false); ... }
StreamWriterFeature:
2.10版本新增的,用于完全替换上面的Feature,被JsonFactory所使用。目的:完全独立的属性配置,不依赖于任何后端格式,因为JsonGenerator并不局限于写JSON,因此把Feature放在JsonGenerator作为内部类是不太合适的,所以单独摘出来。
3 JSON数据转成Java数据(jackson-core之 JsonParser)
(对应 Jackson系列 文章4)
关于JsonParser的基本使用及配置可参阅该文章。
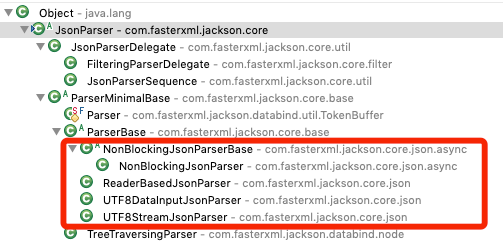
如上图所示,最终负责解析JSON数据的实现类有 ReaderBasedJsonParser、UTF8StreamJsonParser、UTF8SDataInputJsonParser、NonBlockingJsonParser 几种。其中前两种最常用,这两种Parser的区别与前述Generator的两种实现的区别类似。
JSON数据解析(反序列化)的配置项:
JsonParser#Feature 枚举类:
public enum Feature { AUTO_CLOSE_SOURCE(true), ALLOW_COMMENTS(false), ALLOW_YAML_COMMENTS(false), ALLOW_UNQUOTED_FIELD_NAMES(false), ALLOW_SINGLE_QUOTES(false), @Deprecated ALLOW_UNQUOTED_CONTROL_CHARS(false), @Deprecated ALLOW_BACKSLASH_ESCAPING_ANY_CHARACTER(false), @Deprecated ALLOW_NUMERIC_LEADING_ZEROS(false), @Deprecated ALLOW_LEADING_DECIMAL_POINT_FOR_NUMBERS(false), @Deprecated ALLOW_NON_NUMERIC_NUMBERS(false), @Deprecated ALLOW_MISSING_VALUES(false), @Deprecated ALLOW_TRAILING_COMMA(false), STRICT_DUPLICATE_DETECTION(false), IGNORE_UNDEFINED(false), INCLUDE_SOURCE_IN_LOCATION(true); }
比较值得一提的是 ALLOW_COMMENTS、ALLOW_YAML_COMMENTS ,开启后将允许待解析的JSON数据里带有注释,包括 //good /* good */ # good 三种格式的注释。
4 创建JsonParser、JsonGenerator (jackson-core之JsonFactory)
(对应 Jackson系列 文章5)
JsonFactory是Jackson的(最)主要工厂类,用于 配置和构建 JsonGenerator、JsonParser,可见其虽作为工厂类但职责并不单一。该这个工厂实例是「线程安全」的,因此可以重复使用。
基本API:
JsonFactory创建JsonParser、JsonGenerator实例的相关API:

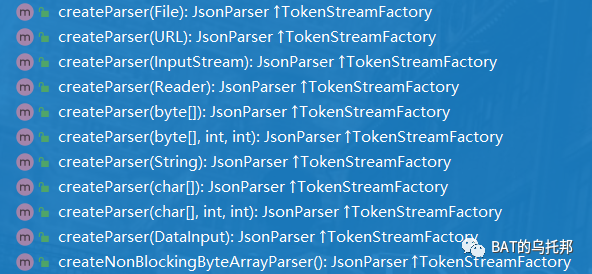
编码自动检测:
从前面关于JsonParser、JsonGenerator的介绍可知两者分别用于反序列化、序列化,因此都涉及到编码问题。对于JsonParser,在解析输入的文本内容时如何知道内容的编码方式呢?这得益于jackson的编码自动检测机制:JsonFactory在创建JsonParser时会调用 ByteSourceJsonBootstrapper#constructParser -> detectEncoding 方法来检测输入内容的编码。相关源码:
public JsonParser constructParser(int parserFeatures, ObjectCodec codec, ByteQuadsCanonicalizer rootByteSymbols, CharsToNameCanonicalizer rootCharSymbols, int factoryFeatures) throws IOException { JsonEncoding enc = detectEncoding(); if (enc == JsonEncoding.UTF8) { /* and without canonicalization, byte-based approach is not performant; just use std UTF-8 reader * (which is ok for larger input; not so hot for smaller; but this is not a common case) */ if (JsonFactory.Feature.CANONICALIZE_FIELD_NAMES.enabledIn(factoryFeatures)) { ByteQuadsCanonicalizer can = rootByteSymbols.makeChild(factoryFeatures); return new UTF8StreamJsonParser(_context, parserFeatures, _in, codec, can, _inputBuffer, _inputPtr, _inputEnd, _bufferRecyclable); } } return new ReaderBasedJsonParser(_context, parserFeatures, constructReader(), codec, rootCharSymbols.makeChild(factoryFeatures)); }
JsonFactory的配置项:
/** * Enumeration that defines all on/off features that can only be * changed for {@link JsonFactory}. */ public enum Feature { // // // Symbol handling (interning etc) /** * Feature that determines whether JSON object field names are * to be canonicalized using {@link String#intern} or not: * if enabled, all field names will be intern()ed (and caller * can count on this being true for all such names); if disabled, * no intern()ing is done. There may still be basic * canonicalization (that is, same String will be used to represent * all identical object property names for a single document). *<p> * Note: this setting only has effect if * {@link #CANONICALIZE_FIELD_NAMES} is true -- otherwise no * canonicalization of any sort is done. *<p> * This setting is enabled by default. */ INTERN_FIELD_NAMES(true), /** * Feature that determines whether JSON object field names are * to be canonicalized (details of how canonicalization is done * then further specified by * {@link #INTERN_FIELD_NAMES}). *<p> * This setting is enabled by default. */ CANONICALIZE_FIELD_NAMES(true), /** * Feature that determines what happens if we encounter a case in symbol * handling where number of hash collisions exceeds a safety threshold * -- which almost certainly means a denial-of-service attack via generated * duplicate hash codes. * If feature is enabled, an {@link IllegalStateException} is * thrown to indicate the suspected denial-of-service attack; if disabled, processing continues but * canonicalization (and thereby <code>intern()</code>ing) is disabled) as protective * measure. *<p> * This setting is enabled by default. * * @since 2.4 */ FAIL_ON_SYMBOL_HASH_OVERFLOW(true), /** * Feature that determines whether we will use {@link BufferRecycler} with * {@link ThreadLocal} and {@link SoftReference}, for efficient reuse of * underlying input/output buffers. * This usually makes sense on normal J2SE/J2EE server-side processing; * but may not make sense on platforms where {@link SoftReference} handling * is broken (like Android), or if there are retention issues due to * {@link ThreadLocal} (see * <a href="https://github.com/FasterXML/jackson-core/issues/189">Issue #189</a> * for a possible case) *<p> * This setting is enabled by default. * * @since 2.6 */ USE_THREAD_LOCAL_FOR_BUFFER_RECYCLING(true) ; /** * Whether feature is enabled or disabled by default. */ private final boolean _defaultState; /** * Method that calculates bit set (flags) of all features that * are enabled by default. */ public static int collectDefaults() { int flags = 0; for (Feature f : values()) { if (f.enabledByDefault()) { flags |= f.getMask(); } } return flags; } private Feature(boolean defaultState) { _defaultState = defaultState; } public boolean enabledByDefault() { return _defaultState; } public boolean enabledIn(int flags) { return (flags & getMask()) != 0; } public int getMask() { return (1 << ordinal()); } }
JsonFactory的实例的创建共有三种方式:
直接new实例,此方式比较常用。
使用JsonFactoryBuilder构建(需要2.10或以上版本),这是推荐的使用方式。
SPI方式创建实例,此方式很少使用。
5 高层API之ObjectMapper
(对应 Jackson系列 文章6)
前面介绍的 jackson-core 模块的 JsonParser、JsonGenerator、JsonFactory 都是底层API,虽然很灵活,但对用户来说使用较为繁琐。因此Jackson提供了更高层的API,即jackson-databind模块。
jackson-databind 是Jackson提供的高层API,包含用于Jackson数据处理器的通用 「数据绑定功能」和「树模型」。它构建在 jackson-core 模块的API之上,并使用 jackson-annotations 进行配置。它是开发者使用得最多的方式,重要程度可见一斑。
虽然Jackson最初的用例是JSON数据绑定,但现在它也可以用于其它数据格式,只要提供 数据的解析器和生成器 的实现即可。但需要注意的是:类的命名在很多地方仍旧使用了“JSON”这个词(比如JsonGenerator),尽管它与JSON格式没有实际的硬依赖关系。
基本介绍
ObjectMapper 是jackson-databind模块最为重要的一个类,它完成了coder对数据绑定的「几乎所有功能」。主要功能如下:
- 提供解析和生成JSON的功能(最重要的功能)
- 普通POJO的序列化/反序列化
- JSON树模型的读/写
- 可以被「高度定制」,以使用不同风格的JSON内容
- 使用Feature进行定制
- 使用可插拔
com.fasterxml.jackson.databind.Module模块来扩展/丰富功能 - 支持「更高级」的对象概念:比如多态泛型、对象标识
- 充当更为高级(更强大)的API:ObjectReader和ObjectWriter的「工厂」
ObjectReader和ObjectWriter底层亦是依赖于jackson-core的API实现读写- 支持丰富的数据格式,而不是局限于JSON格式。如自 2.10 版本起,提供了JsonMapper、YAMLMapper 子类,分别用于处理json数据、yaml 格式的数据(需额外导包)。
尽管绝大部分的读/写API都通过ObjectMapper暴露出去了,但有些功能还是只放在了ObjectReader/ObjectWriter里,比如对于读/写 「长序列」 的能力你只能通过ObjectReader#readValues(InputStream) / ObjectWriter#writeValues(OutputStream)去处理。
基本使用
详情参阅本大节首的参考文章。
生成JSON数据(序列化)
主要API:
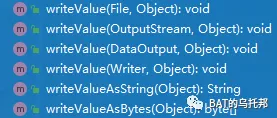
用的最多的是 writeValueAsString(obj) 方法
代码示例及执行结果:
// 代码 ObjectMapper objectMapper = new ObjectMapper(); System.out.println("----------写简单类型----------"); System.out.println(objectMapper.writeValueAsString(18)); System.out.println(objectMapper.writeValueAsString("YourBatman")); System.out.println("----------写集合类型----------"); System.out.println(objectMapper.writeValueAsString(Arrays.asList(1, 2, 3))); System.out.println(objectMapper.writeValueAsString(new HashMap<String, String>() {{ put("zhName", "A哥"); put("enName", "YourBatman"); }})); System.out.println("----------写POJO----------"); System.out.println(objectMapper.writeValueAsString(new Person("A哥", 18))); // 执行结果 18 "YourBatman" ----------写集合类型---------- [1,2,3] {"zhName":"A哥","enName":"YourBatman"} ----------写POJO---------- {"name":"A哥","age":18}
解析JSON数据(反序列化)
主要API:
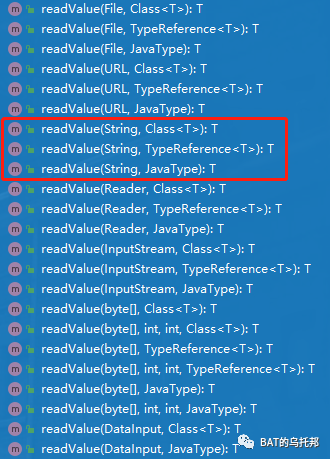
用得最多的是 readValue(String content, Class<T> valueType) 方法
代码示例及执行结果:
1 // 代码 2 ObjectMapper objectMapper = new ObjectMapper(); 3 4 System.out.println("----------读简单类型----------"); 5 System.out.println(objectMapper.readValue("18", Integer.class)); 6 // 抛错:JsonParseException 单独的一个串,解析会抛错 7 // System.out.println(objectMapper.readValue("YourBatman", String.class)); 8 9 System.out.println("----------读集合类型----------"); 10 System.out.println(objectMapper.readValue("[1,2,3]", List.class)); 11 System.out.println(objectMapper.readValue("{\"zhName\":\"A哥\",\"enName\":\"YourBatman\"}", Map.class)); 12 13 System.out.println("----------读POJO----------"); 14 System.out.println(objectMapper.readValue("{\"name\":\"A哥\",\"age\":18}", Person.class)); 15 16 17 18 System.out.println("----------读集合类型 泛型问题----------"); 19 List<Long> ids = objectMapper.readValue("[1,2,3]", new TypeReference<List<Long>>() { 20 }); 21 Long id = ids.get(0); 22 System.out.println(id); 23 24 List<Long> list = objectMapper.readValue("[1,2,3]", List.class); 25 //Long id = list.get(0);// 因泛型擦除问题,会报类型转换错误ClassCastException 26 27 28 29 // 执行结果 30 ----------读简单类型---------- 31 18 32 ----------读集合类型---------- 33 [1, 2, 3] 34 {zhName=A哥, enName=YourBatman} 35 ----------读POJO---------- 36 Person(name=A哥, age=18) 37 ----------读集合类型 泛型问题---------- 38 1
反序列化成数组类型,示例: Area[] zhAreas = objectMapper.readValue(areaJsonString, Area[].class);
需要特别注意泛型擦除问题:「若反序列化成为一个集合类型(Collection or Map),泛型会被擦除」,此时你应该使用readValue(String content, TypeReference<T> valueTypeRef)方法代替。详情可参阅本大节首的参考文章。
其他
其他格式数据的序列化和反序列化,以yaml为例,详情参阅:yaml文件的五种读取方式中的相关部分。
6 TreeModel
(对应 Jackson系列 文章7)
虽然ObjectMapper在数据绑定上既可以处理简单类型(如Integer、List、Map等),也能处理完全类型(如POJO),看似无所不能。但是,若有如下场景它依旧「不太好实现」:
硕大的JSON串中我只想要「某一个」(某几个)属性的值而已
临时使用,我并不想创建一个POJO与之对应,只想直接使用「值」即可(类型转换什么的我自己来就好)
数据结构高度「动态化」
TreeModel
为了解决这些问题,Jackson提供了强大的「树模型」 API供以使用。树模型虽然是jackson-core模块里定义的,但是是由jackson-databind模块实现的。
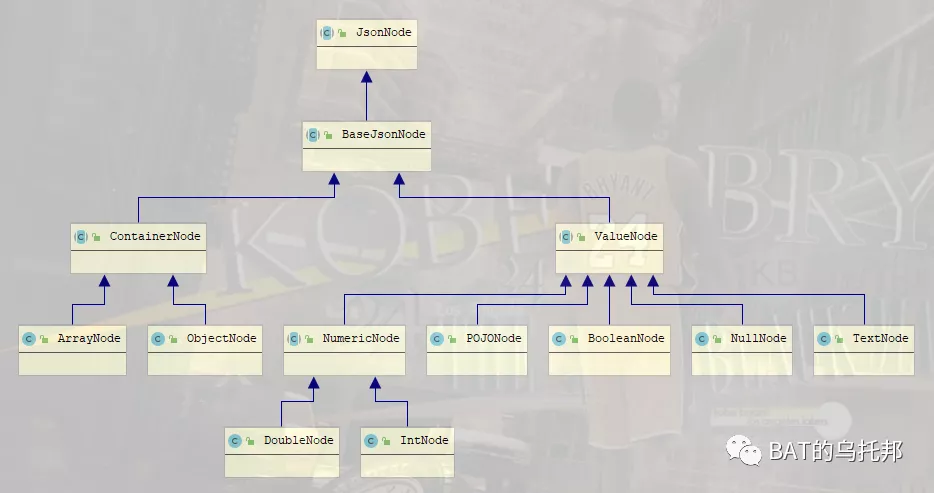
树模型是JSON数据内存树的表示形式,这是最灵活的表示,可以动态增减、从任意节点进行遍历。。Jackson提供了树模型API来「生成和解析」 JSON串,主要用到如下三个核心类:
JsonNode:表示json节点,类似XML的DOM树节点。可以往里面塞值,从而最终构造出一颗json树。
JsonNodeFactory:用来构造各种JsonNode节点的工厂。例如对象节点ObjectNode、数组节点ArrayNode等。
ObjectMapper:实现JsonNode和JSON字符串的互转。
代码示例及执行结果:
1 // 代码 2 JsonNodeFactory factory = JsonNodeFactory.instance; 3 4 System.out.println("------ValueNode值节点示例------"); 5 // 数字节点 6 JsonNode node = factory.numberNode(1); 7 System.out.println(node.isNumber() + ":" + node.intValue()); 8 9 // null节点 10 node = factory.nullNode(); 11 System.out.println(node.isNull() + ":" + node.asText()); 12 13 // missing节点 14 node = factory.missingNode(); 15 System.out.println(node.isMissingNode() + "_" + node.asText()); 16 17 // POJONode节点 18 node = factory.pojoNode(new Person("YourBatman", 18)); 19 System.out.println(node.isPojo() + ":" + node.asText()); 20 21 System.out.println("---" + node.isValueNode() + "---"); 22 23 24 System.out.println("------构建一个JSON结构数据------"); 25 ObjectNode rootNode = factory.objectNode(); 26 27 // 添加普通值节点 28 rootNode.put("zhName", "A哥"); // 效果完全同:rootNode.set("zhName", factory.textNode("A哥")) 29 rootNode.put("enName", "YourBatman"); 30 rootNode.put("age", 18); 31 32 // 添加数组容器节点 33 ArrayNode arrayNode = factory.arrayNode(); 34 arrayNode.add("java") 35 .add("javascript") 36 .add("python"); 37 rootNode.set("languages", arrayNode); 38 39 // 添加对象节点 40 ObjectNode dogNode = factory.objectNode(); 41 dogNode.put("name", "大黄") 42 .put("age", 3); 43 rootNode.set("dog", dogNode); 44 45 System.out.println(rootNode); 46 System.out.println(rootNode.get("dog").get("name")); 47 48 49 50 // 结果 51 52 ------ValueNode值节点示例------ 53 true:1 54 true:null 55 true_ 56 true:Person(name=YourBatman, age=18) 57 ---true--- 58 59 ------构建一个JSON结构数据------ 60 {"zhName":"A哥","enName":"YourBatman","age":18,"languages":["java","javascript","python"],"dog":{"name":"大黄","age":3}} 61 "大黄"
TreeModel数据的序列化与反序列化
ObjectMapper中提供了TreeModel数据的序列化、反序列化的实现。
序列化
相关API:

示例代码及执行结果:
1 // 示例1 2 public void test1() { 3 ObjectMapper mapper = new ObjectMapper(); 4 5 Person person = new Person(); 6 person.setName("YourBatman"); 7 person.setAge(18); 8 9 person.setDog(new Person.Dog("旺财", 3)); 10 11 JsonNode node = mapper.valueToTree(person); 12 13 System.out.println(person); 14 // 遍历打印所有属性 15 Iterator<JsonNode> it = node.iterator(); 16 while (it.hasNext()) { 17 JsonNode nextNode = it.next(); 18 if (nextNode.isContainerNode()) { 19 if (nextNode.isObject()) { 20 System.out.println("狗的属性:::"); 21 22 System.out.println(nextNode.get("name")); 23 System.out.println(nextNode.get("age")); 24 } 25 } else { 26 System.out.println(nextNode.asText()); 27 } 28 } 29 30 // 直接获取 31 System.out.println("---------------------------------------"); 32 System.out.println(node.get("dog").get("name")); 33 System.out.println(node.get("dog").get("age")); 34 } 35 36 //示例1 结果 37 Person(name=YourBatman, age=18, dog=Person.Dog(name=旺财, age=3)) 38 YourBatman 39 18 40 狗的属性::: 41 "旺财" 42 3 43 --------------------------------------- 44 "旺财" 45 3 46 47 48 // 示例2 49 public void test2() throws IOException { 50 ObjectMapper mapper = new ObjectMapper(); 51 52 JsonFactory factory = new JsonFactory(); 53 try (JsonGenerator jsonGenerator = factory.createGenerator(System.err, JsonEncoding.UTF8)) { 54 55 // 1、得到一个jsonNode(为了方便我直接用上面API生成了哈) 56 Person person = new Person(); 57 person.setName("YourBatman"); 58 person.setAge(18); 59 JsonNode jsonNode = mapper.valueToTree(person); 60 61 // 使用JsonGenerator写到输出流 62 mapper.writeTree(jsonGenerator, jsonNode); 63 } 64 } 65 66 //示例2结果 67 {"name":"YourBatman","age":18,"dog":null}
反序列化
相关API:
代码示例:
public void test4() throws IOException { ObjectMapper mapper = new ObjectMapper(); String jsonStr = "{\"name\":\"YourBatman\",\"age\":18,\"dog\":{\"name\":\"旺财\",\"color\":\"WHITE\"},\"hobbies\":[\"篮球\",\"football\"]}"; JsonNode node = mapper.readTree(jsonStr); System.out.println(node.get("dog").get("color").asText()); } public void test5() throws JsonProcessingException { String jsonStr = "{\"name\":\"YourBatman\",\"age\":18}"; JsonNode node = new ObjectMapper().readTree(jsonStr); System.out.println("-------------向结构里动态添加节点------------"); // 动态添加一个myDiy节点,并且该节点还是ObjectNode节点 ((ObjectNode) node).with("myDiy").put("contry", "China"); System.out.println(node); }
可见,在只需要取出一个大json串中的少数几个字段时用 TreeModel API 比较方便。
7 其他
SpringBoot中默认用的序列化工具就是Jackson,其默认配置及修改可参阅这篇文章。相关类:
interface Jackson2ObjectMapperBuilderCustomizer -> class JacksonAutoConfiguration
序列化时保存元素类型:
对于形如 Map<String, Object> map的数据,默认情况下,如果map的value是POJO,则map序列化成json数据后将无法反序列化回POJO的类型,而是反序列化成LinkedHashMap类型的value。实际场景:借助Redis实现DistributedHttpSession时,执行session.setAttribute(key, ltisessionObj) 时是将会把key、ltisessionObj作为map的元素存到redis,若无法反序列化成原来的类型则执行 ltisessionObj= (LtiSessionData)session.getAttribute(key) 时将会出现类型不匹配的错误。
如何保证能反序列化回来?进行 objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL) 配置即可。此时对于复杂类型(可通过 DefaultTyping 参数指定哪类字段要保存类型)的值进行序列化时,结果中将会保存序列化前的值的类型信息——序列化的结果将会是个包含两个元素的数组:分别为序列化前值类型(全限定名)、value的值,这样就能够反序列化成原来的类型。注,这里不仅指map的value,实际上对于任何一个待序列化的Java对象,只要是复杂类型都会被这样处理,例如对于Map<Object, Object> map,其key也可能被这样处理。
缺点:复杂类型的对象序列化后保存了对象的类型信息,因此只能被反序列化成原来的类型,与默认情况相比可能通用性更低些(后者则可以被反序列化成多种类型的对象,只要这些类型里字段名一致);此外,按官方说法,这种方案安全风险,详情可参阅 DefaultTyping 类源码。
NOTE: use of Default Typing can be a potential security risk if incoming content comes from untrusted sources, and it is recommended that this is either not done, or, if enabled, use
setDefaultTypingpassing a customTypeResolverBuilderimplementation that white-lists legal types to use.
序列化和反序列化时忽略指定属性: @JsonProperty//(access = Access.AUTO) private List<AreaNode> children;
序列化时忽略指定属性: @JsonProperty(access = Access.WRITE_ONLY) private List<AreaNode> children;
反序列化时忽略指定属性: @JsonProperty(access = Access.READ_ONLY) private List<AreaNode> children;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号