
06-Spark on YARN的设计
实施
-
问题:
为什么要将Spark的程序运行在YARN上,不运行在自带的Standalone集群上? -
实现
- 统一化资源管理
- 工作中的计算集群大多数情况下只有1套集群
- 如果Hadoop生态的程序,例如MR、Hive、Sqoop、Oozie等使用YARN来计算
- 而Spark的程序单独用Standalone集群来计算
- 就导致了一套硬件资源被两套资源管理平台所管理,使用时会导致资源竞争冲突等问题
- 不能充分的发挥硬件资源的性能且管理麻烦
- 自由开发模式
- 使用YARN统一化管理整个硬件集群的所有计算资源:公共分布式资源平台
- YARN支持多种类型程序的运行:MR、Tez、Spark、Flink等
- 成熟的资源调度机制
- 支持多队列、多种调度器可以实现不同场景下的计算资源隔离和任务调度
- YARN中Capacity、Fair调度器
- 统一化资源管理
回顾YARN上程序运行的流程
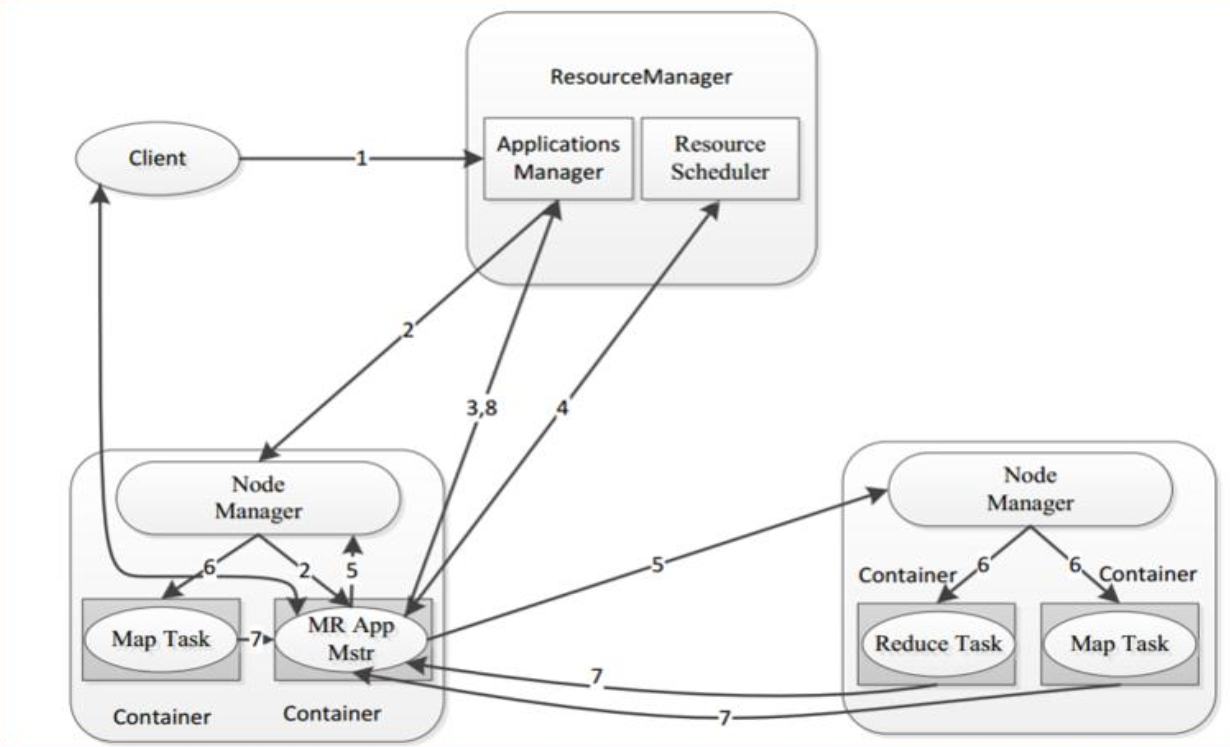
-
step1:客户端申请提交运行MR程序
-
step2:ResourceManager验证是否合法,如果合法,随机选择一台NodeManager启动AppMaster
-
step3:AppMaster根据任务分配向ResourceManager申请Task运行的Container资源
-
step4:ResourceManager根据资源情况分配对应的Container信息返回给AppMaster
-
step5:AppMaster根据ResourceManager分配的Container信息,将Container信息分发给对应的NodeManager
-
step6:NodeManager收到Container信息,启动MapTask和ReduceTask运行
-
step7:每个Task将自己运行的信息汇报给AppMaster,AppMaster监控每个Task的状态,直到Task结束
-
step8:AppMaster等到所有Task结束返回运行结果
核心:
-
问题:
Spark on YARN时,在不同的deploy mode下有什么区别? -
思路
- deploy-mode:决定Driver进程运行的位置
- client:运行在客户端
- cluster:运行在从节点【NM】
- AppMaster的功能:申请资源、调度、监控Task、反馈结果【一定运行在NM】
- Driver的功能:申请资源、解析Task、调度Task、监控Task、反馈结果【由deploymode决定】
- deploy-mode:决定Driver进程运行的位置
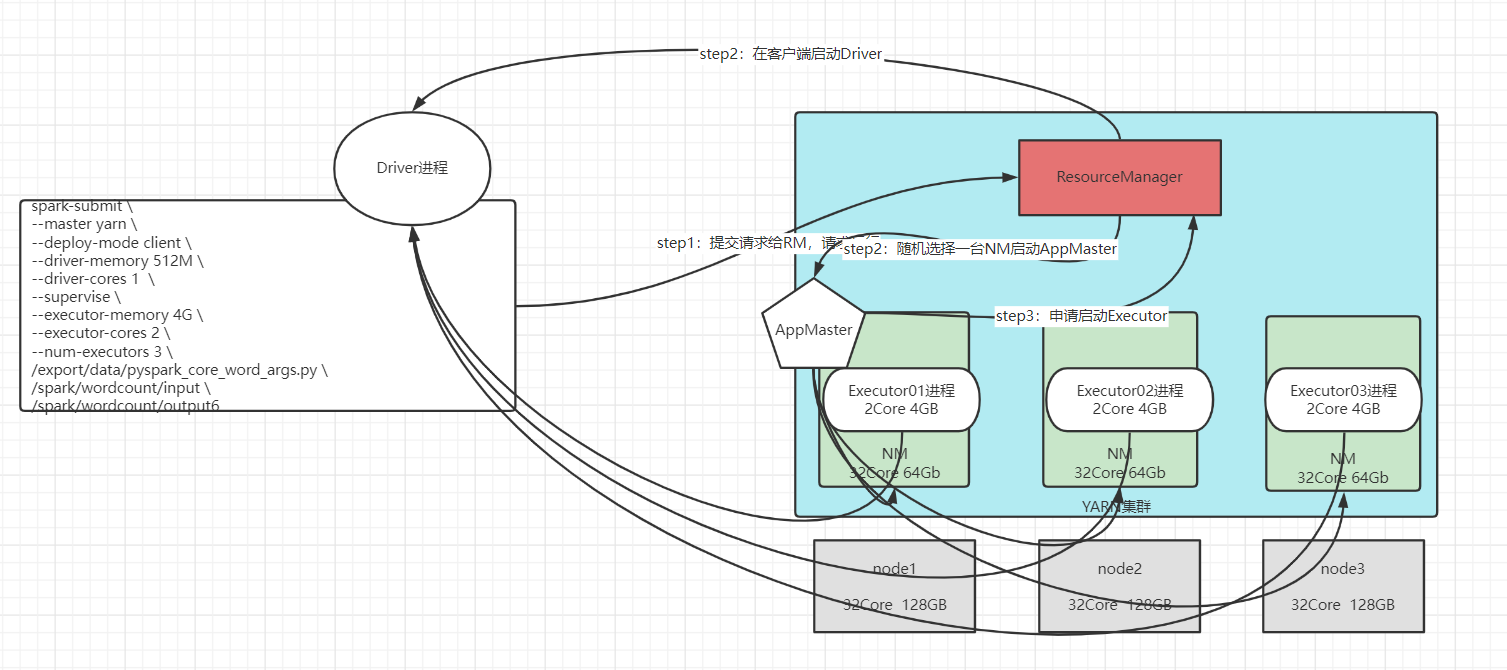
Spark on YARN client模式
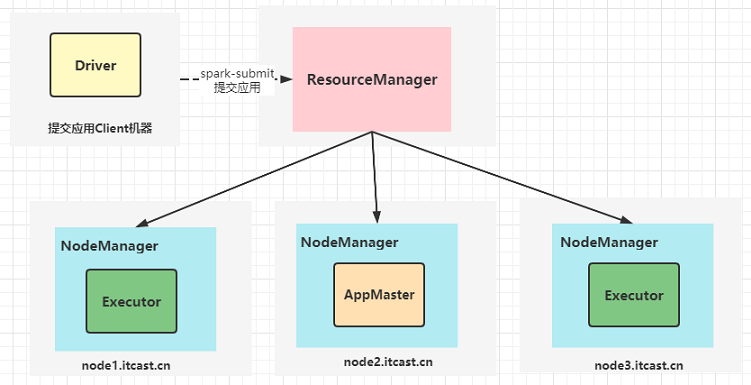
-
AppMaster与Driver共存
-
AppMaster运行在NodeManager上:负责申请资源,启动Executors、反馈结果
-
Driver运行在客户端机器上,运行在客户端进程内部:负责解析、调度和监控Task
-
测试流程图:
![]()
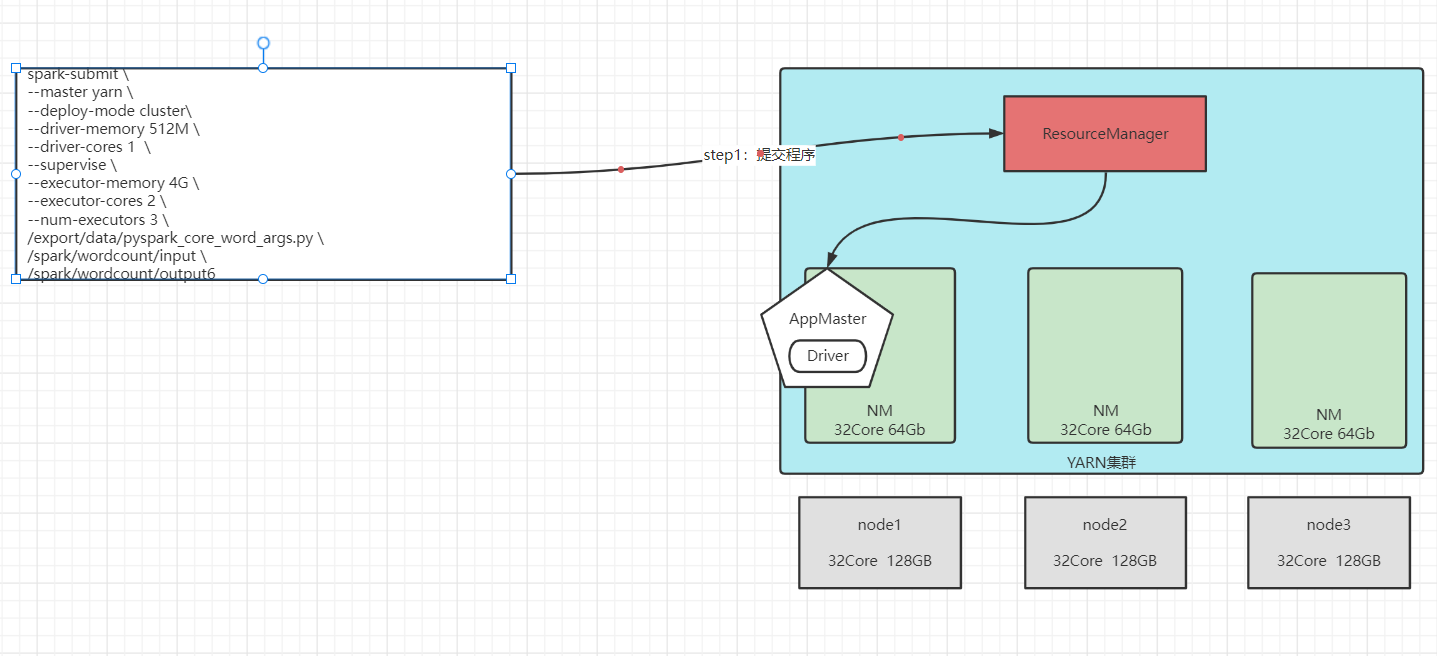
Spark on YARN cluster模式
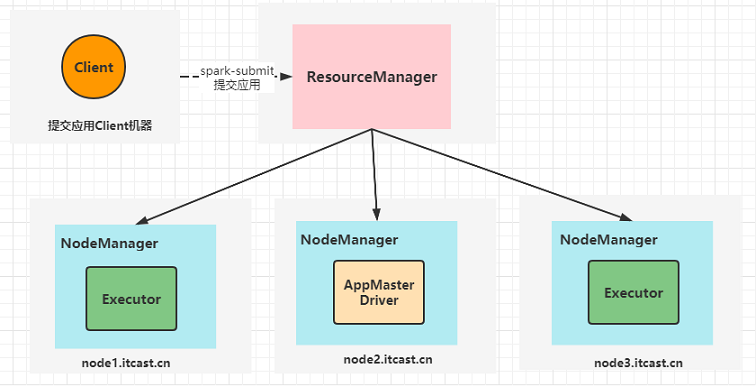
-
AppMaster与Driver合并
-
Driver以子进程的方式运行在AppMaster进程内部,整体负责实现资源申请、Task的解析、调度和监控
-
测试流程图
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号