
03-Spark的计算流程设计
MR的计算流程设计
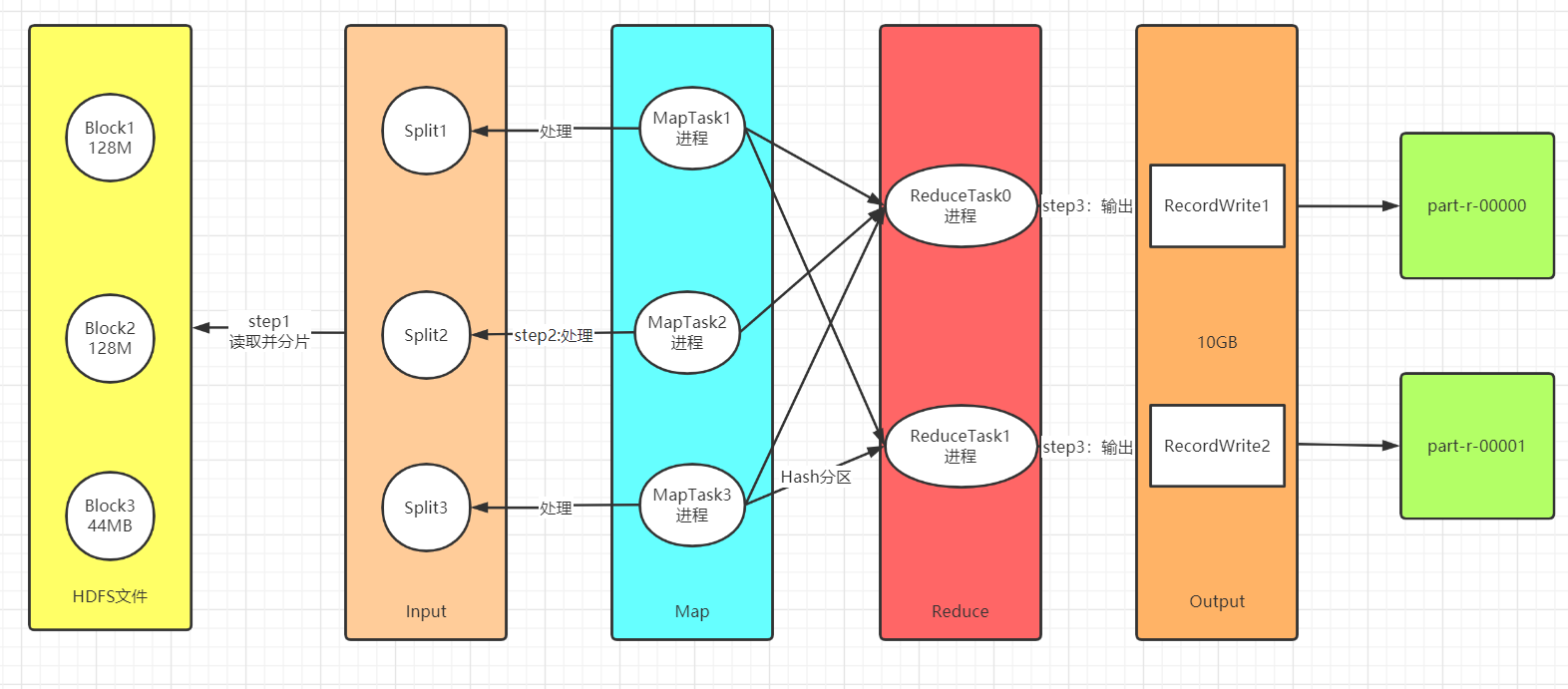
- step1:读取数据:Input
- 功能一:实现分片,将读取到的数据进行划分,将不同的数据才能分给不同Task
- 功能二:转换KV
- step2:处理数据:Map、Shuffle、Reduce
- Map:负责数据处理:一对一的转换,多对一的过滤
- 功能一:构建分布式并行Task,每个分片对应一个MapTask【进程】
- 功能二:每个MapTask负责自己处理的分片的数据的转换,转换逻辑由map方法来决定
- Shuffle:负责数据处理
- Map输出写入数据:磁盘
- 功能:实现全局的:分区、排序、分组
- Reduce读取Map输出的数据:读取磁盘
- Reduce:负责数据处理:多对一的聚合
- 功能:默认由一个ReduceTask【进程】来实现数据的聚合处理
- Map:负责数据处理:一对一的转换,多对一的过滤
- step3:保存结果:Output
- 功能:将上一步的结果写入外部系统
Spark的计算流程设计
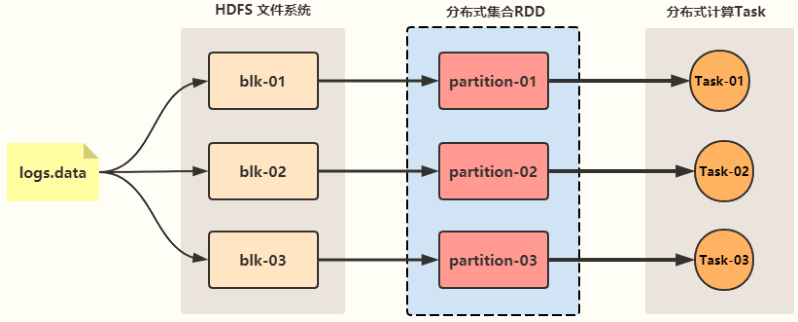
- step1:读取数据
- 根据分片的规则,将数据源进行分片,每个分片作为一个数据分区
- 整个数据的所有分区从逻辑上合并为一个整体,SparkCore中称之为RDD
- 一个RDD就代表读取到的数据,这个数据由多个分区组成,每个分区数据存储在不同的机器的内存中
- RDD可以理解为一个分布式的列表集合
- |
- 读取到的数据会放入一个RDD中,实际读取的数据会划分成多个分区,每个分区的数据在不同节点上
- 操作RDD代表操作这个文件数据,RDD就是文件数据的集合,类似于一个列表
- RDD是一个逻辑上的概念,只是代表一份数据,这份数据在物理上被分成了多个分区,存储在不同的节点上
- step2:处理数据
- 对RDD调用函数进行处理,Spark底层就会启动多个Task【线程】对这个RDD的每个分区来进行并行处理
- 处理流程由代码中的函数决定,可以有多个Map和多个Reduce阶段
- 如果不经过Shuffle,上一步处理后的结果可以存储在内存中,直接供下一步进行计算
- step3:保存结果
- 将每个Task计算的结果进行输出保存
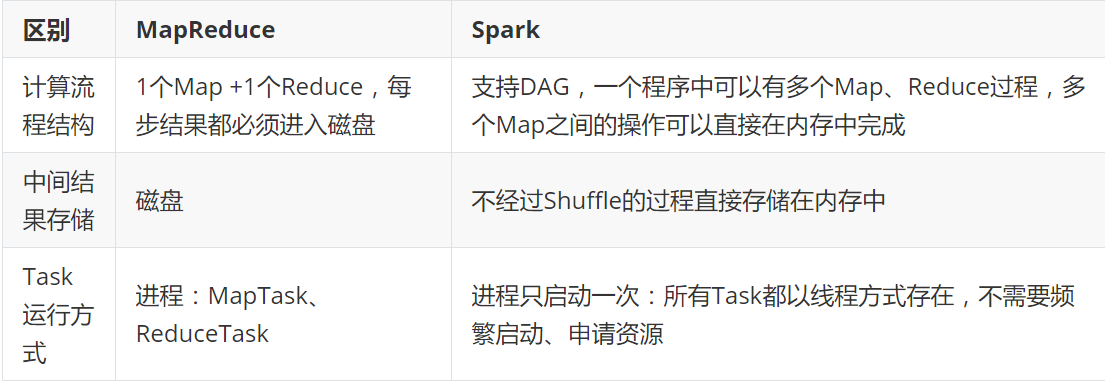
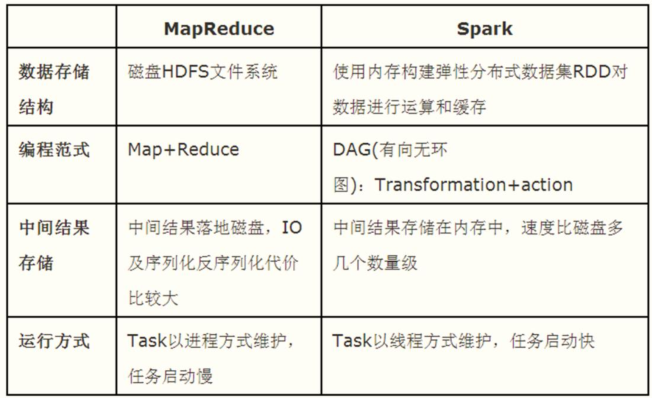
为什么Spark比MR要快?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号