k8s调度器介绍(调度框架版本)
从一个pod的创建开始
- 由kubectl解析创建pod的yaml,发送创建pod请求到APIServer。
- APIServer首先做权限认证,然后检查信息并把数据存储到ETCD里,创建deployment资源初始化。
- kube-controller通过list-watch机制,检查发现新的deployment,将资源加入到内部工作队列,检查到资源没有关联pod和replicaset,然后创建rs资源,rs controller监听到rs创建事件后再创建pod资源。
- scheduler 监听到pod创建事件,执行调度算法,将pod绑定到合适节点,然后告知APIServer更新pod的
spec.nodeName - kubelet 每隔一段时间通过其所在节点的NodeName向APIServer拉取绑定到它的pod清单,并更新本地缓存。
- kubelet发现新的pod属于自己,调用容器API来创建容器,并向APIService上报pod状态。
- Kub-proxy为新创建的pod注册动态DNS到CoreOS。为Service添加iptables/ipvs规则,用于服务发现和负载均衡。
- deploy controller对比pod的当前状态和期望来修正状态。
调度器介绍
从上述流程中,我们能大概清楚kube-scheduler的主要工作,负责整个k8s中pod选择和绑定node的工作,这个选择的过程就是应用调度策略,包括NodeAffinity、PodAffinity、节点资源筛选、调度优先级、公平调度等等,而绑定便就是将pod资源定义里的nodeName进行更新。
设计
kube-scheduler的设计有两个历史阶段版本:
- 基于谓词(predicate)和优先级(priority)的筛选。
- 基于调度框架的调度器,新版本已经把所有的旧的设计都改造成扩展点插件形式(1.19+)。
所谓的谓词和优先级都是对调度算法的分类,在scheduler里,谓词调度算法是来选择出一组能够绑定pod的node,而优先级算法则是在这群node中进行打分,得出一个最高分的node。
而调度框架的设计相比之前则更复杂一点,但确更加灵活和便于扩展,关于调度框架的设计细节可以查看官方文档——624-scheduling-framework,当然我也有一遍文章对其做了翻译还加了一些便于理解的补充——KEP: 624-scheduling-framework。总结来说调度框架的出现是为了解决以前webhooks扩展器的局限性,一个是扩展点只有:筛选、打分、抢占、绑定,而调度框架则在这之上又细分了11个扩展点;另一个则是通过http调用扩展进程的方式其实效率不高,调度框架的设计用的是静态编译的方式将扩展的程序代码和scheduler源码一起编译成新的scheduler,然后通过scheduler配置文件启用需要的插件,在进程内就能通过函数调用的方式执行插件。
调度流程
现在网上大部分的kube-scheduler调度流程文章都不是基于新的调度框架所写的,还是谓词和优先级的流程。基于调度框架实现的调度流程总的来说就是执行一个个插件的过程,如下图:
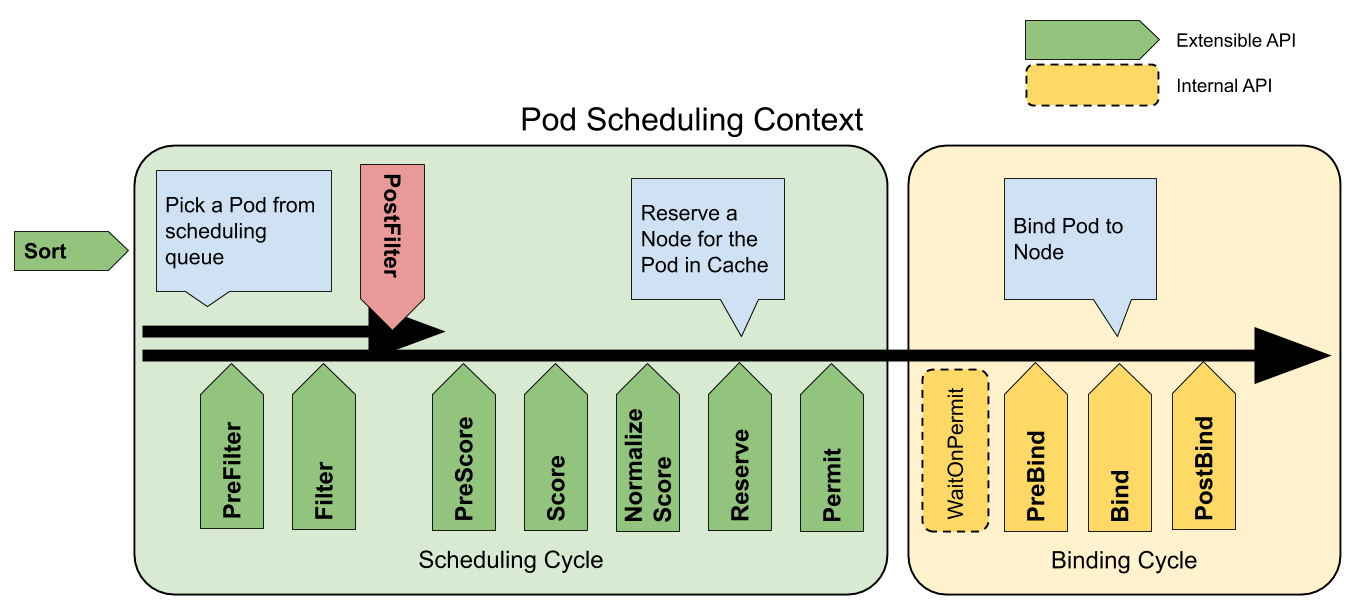
整个过程可以分为两个周期:调度周期(scheduling cycle)、绑定周期(Binding Cycle),这两个周期的区别不仅仅是包含插件,还有每个周期的上下文(Cycle Context),这个上下文将贯穿各自的周期使周期内的每个插件之间能够进行数据的交流。Sort插件是不属于两个周期任何一个,它的职责就是对调度队列中的Pod进行排序。
一个pod的调度过程在调度插件里是线性执行下去的,但是绑定周期的执行是异步的,也就是说scheduler在执行A Pod的绑定周期时,其实也同时开始了B Pod的调度周期。这也是比较合理的,毕竟Bind插件是需要和APIServer进行通信来更新调度pod的nodeName,这个网络IO过程存在着不可确定性。
调度周期:
Filter插件的功能类似之前的谓词调度,这个过程就是根据调度策略函数(在调度框架里就是多个Filter插件函数)进行node筛选,筛选的原理就是将被筛选的node和待调度的pod以及周期上下文等作为参数一并传入这些函数,最后收集通过了所有筛选函数的node进入下一阶段,在这个阶段将会以node为单位进行并发处理。
PostFilter插件虽说是发生在Filter之后,但是确只能在Filter插件没有返回合适的node才执行。在scheduler里默认的PostFilter插件只有一个功能,进行抢占调度。抢占调度的原理:首先会将node上低于待调度pod的优先级的Pod全部剔除,当然这个只是模拟过程并不是真正将Pod从干掉,然后再次执行Filter插件,如果失败了那就是抢占调度失败,成功了则将前面剔除的pod一个一个加回来,每一次都执行Filter插件从而找出调度该Pod所需要剔除的最少的低优先级Pod。
Score插件的功能类比以前的优先级调度,这个过程是对前一阶段得出的node列表进行再筛选,得出最终要调度的node。NormalizeScore再调度框架里也不能算是一个单独扩展点,它往往是配合着score插件一起出现,为了将统一插件打分的分数。在调度框架里是作为Score插件可选的实现接口,同样的Score插件的也是会并发的在每个node上执行。
Reserve 插件有两种函数,reserve函数在绑定前为Pod做准备动作,Unreserve函数则在绑定周期间发生错误的时候做恢复。默认的Reserve插件使用情况是处理pod关联里pvc与pv的绑定和解绑。
绑定周期:
整个绑定周期都是在一个异步的协程中,在执行进入绑定周期前会执行Pod的assume(假定)过程,这个过程做的主要是假设Pod已经绑定到目标node上,所以会更新scheduler的node缓存信息,这样当调度下一个pod到前一个pod真正在node上创建的过程中,能够用真正的node信息进行调度。
Scheduler的启动流程
现在我们了解了scheduler是如何执行调度算法、pod绑定过程的,但是对于什么时候执行调度和调度的pod怎么获得其实还并不清楚,所以我们需要深入到scheduler的代码来了解这一切。
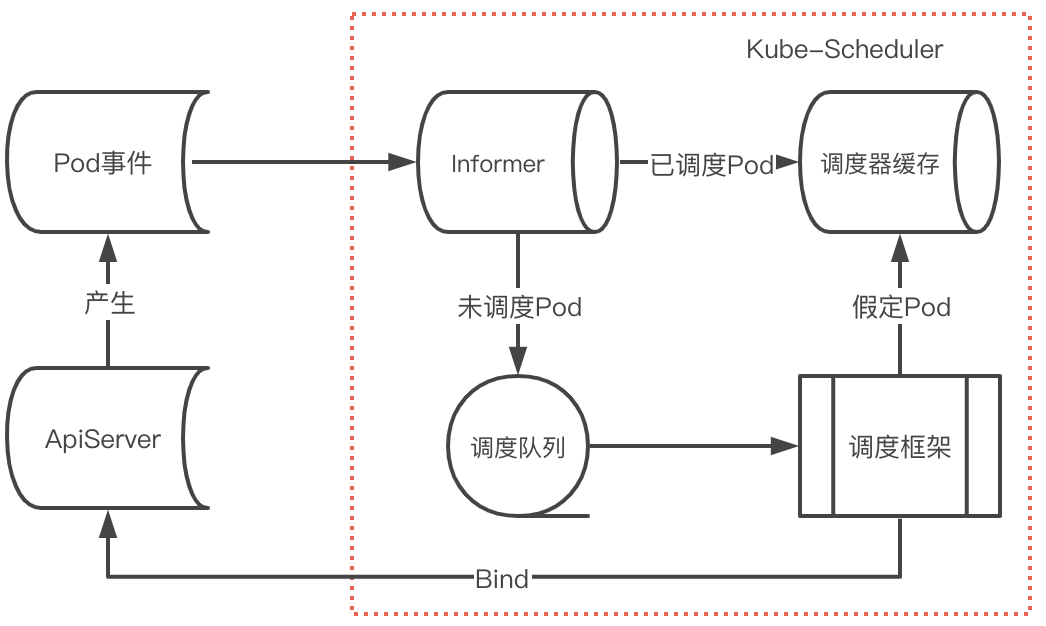
上面是一个简略版的调度器处理pod流程:
首先scheduler会启动一个client-go的Informer来监听Pod事件(不只Pod其实还有Node等资源变更事件),这时候注册的Informer回调事件会区分Pod是否已经被调度(spec.nodeName),已经调度过的Pod则只是更新调度器缓存,而未被调度的Pod会加入到调度队列,然后经过调度框架执行注册的插件,在绑定周期前会进行Pod的假定动作,从而更新调度器缓存中该Pod状态,最后在绑定周期执行完向ApiServer发起BindAPI,从而完成了一次调度过程。
先找到在/cmd/kube-scheduler/scheduler.go的入口函数
func main() {
command := app.NewSchedulerCommand()
code := cli.Run(command)
os.Exit(code)
}
k8中组件通用的启动模版,我们需要找到这个command定义的
func NewSchedulerCommand(registryOptions ...Option) *cobra.Command {
...
cmd := &cobra.Command{ // 定义了一个cobra的Comand结构体, cmd.Execute(),会执行定义的Run函数。
Run: func(cmd *cobra.Command, args []string) {
if err := runCommand(cmd, opts, registryOptions...); err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
}
...
}
}
查看runCommand定义
func runCommand(cmd *cobra.Command, opts *options.Options, registryOptions ...Option) error {
...
cc, sched, err := Setup(ctx, opts, registryOptions...) // 初始化配置、Scheduler
...
return Run(ctx, cc, sched)
}
查看Run定义
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
// To help debugging, immediately log version
klog.V(1).Infof("Starting Kubernetes Scheduler version %+v", version.Get())
// 全局配置
if cz, err := configz.New("componentconfig"); err == nil {
cz.Set(cc.ComponentConfig)
} else {
return fmt.Errorf("unable to register configz: %s", err)
}
// 事件管理器
cc.EventBroadcaster.StartRecordingToSink(ctx.Done())
// 选举检查
var checks []healthz.HealthChecker
if cc.ComponentConfig.LeaderElection.LeaderElect {
checks = append(checks, cc.LeaderElection.WatchDog)
}
// http和metric服务
if cc.InsecureServing != nil {
...
}
if cc.InsecureMetricsServing != nil {
...
}
// https服务
if cc.SecureServing != nil {
...
}
// 启动所有Informer
cc.InformerFactory.Start(ctx.Done())
// 等待informer缓存完毕
cc.InformerFactory.WaitForCacheSync(ctx.Done())
// 选举机制启动
if cc.LeaderElection != nil {
...
}
// 非选举机制启动过, 无论是选举和非选举启动都会调用最后处理逻辑都会到sched.Run()
sched.Run(ctx)
return fmt.Errorf("finished without leader elect")
}
sched.Run在/pkg/scheduler/scheduler.go里
func (sched *Scheduler) Run(ctx context.Context) {
...
sched.SchedulingQueue.Run()
wait.UntilWithContext(ctx, sched.scheduleOne, 0)
sched.SchedulingQueue.Close()
}
其中wait.UntilWithContext将会不间断的调用sched.scheduleOne函数,这么看schedulerOne就是处理Pod调度的工作函数了,到这里我们得回到上面New出sched的地方cc, sched, err := Setup(...)。
func Setup(ctx context.Context, opts *options.Options, outOfTreeRegistryOptions ...Option) (*schedulerserverconfig.CompletedConfig, *scheduler.Scheduler, error) {
c, err := opts.Config() // 从Options(命令行收集)初始化schedler的配置
cc := c.Complete() // 补充配置
// Create the scheduler.
sched, err := scheduler.New(...), // 初始化Scheduler
)
return &cc, sched, nil
}
查看New方法
func New(...) (*Scheduler, error) {
options := defaultSchedulerOptions // 设置默认配置项
...
configurator := &Configurator{ // 创建配置器
...
}
sched, err := configurator.create() // 通过配置起器创建scheduler
if err != nil {
return nil, fmt.Errorf("couldn't create scheduler: %v", err)
}
// 为informer设置监听事件,包括pod(已调度(字段NodeName)-添加到SchedulerCache, 为调度则添加到SchedulingQueue队列中。
// Node、PV、PVC、SC、CSINode、Service
addAllEventHandlers(sched, informerFactory, podInformer)
return sched, nil
}
查看配置起Configurator的create
func (c *Configurator) create() (*Scheduler, error) {
// 创建提名队列,用于存储发生抢占的Pod
nominator := internalqueue.NewPodNominator(c.informerFactory.Core().V1().Pods().Lister())
profiles, err := profile.NewMap(...) // 调度框架配置
podQueue := internalqueue.NewSchedulingQueue() // 创建调度框架
algo := NewGenericScheduler() // 创建调度算法,这里面主要是执行筛选和打分插件
return &Scheduler{
SchedulerCache: c.schedulerCache, // 调度缓存
Algorithm: algo, // 调度算法
Extenders: extenders, // webhook扩展
Profiles: profiles, // 调度框架配置
NextPod: internalqueue.MakeNextPodFunc(podQueue), // 获取调度Pod
Error: MakeDefaultErrorFunc(), // 调度失败处理
StopEverything: c.StopEverything, // 停止器
SchedulingQueue: podQueue, // 调度队列
}, nil
}
这里我们发现了SchedulingQueue是 由NewSchedulingQueue声明的一个对象。
/pkg/scheduler/internal/queue/scheduling_queue.go
func NewPriorityQueue(
lessFn framework.LessFunc,
opts ...Option,
) *PriorityQueue {
...
pq := &PriorityQueue{ // 定义了3种队列,activeQ、unschedulableQ、podBackoffQ
PodNominator: options.podNominator,
clock: options.clock,
stop: make(chan struct{}),
podInitialBackoffDuration: options.podInitialBackoffDuration,
podMaxBackoffDuration: options.podMaxBackoffDuration,
activeQ: heap.NewWithRecorder(),
unschedulableQ: newUnschedulablePodsMap(),
moveRequestCycle: -1,
}
pq.podBackoffQ = heap.NewWithRecorder()
return pq
}
SchedulingQueue的结构
type SchedulingQueue interface {
...
Pop() (*framework.QueuedPodInfo, error)
Update(oldPod, newPod *v1.Pod) error
Delete(pod *v1.Pod) error
MoveAllToActiveOrBackoffQueue(event string)
}
找到了sched的属性SchedulingQueue实际上是一个PriorityQueue对象,我们找到它的Run方法。
func (p *PriorityQueue) Run() {
// 每一秒从podBackoffQ拿出最近的pod检查是否可以加入到activeQ
go wait.Until(p.flushBackoffQCompleted, 1.0*time.Second, p.stop)
// 没30秒从无法调度pod的队列拿出pod检查是否可以加入到activeQ
go wait.Until(p.flushUnschedulableQLeftover, 30*time.Second, p.stop)
}
现在我们找到了整个sched的启动和调度队列管理的功能,接下来查看具体调度一个pod的详细经过。
从sched.Run中我们找打了scheduleOne方法:/pkg/scheduler/scheduler.go
func (sched *Scheduler) scheduleOne(ctx context.Context) {
podInfo := sched.NextPod() // 获取activeQ的下一个pod
fwk, err := sched.frameworkForPod(pod) // 从Pod里获取设置调度框架,默认`default-schdeler`
...
scheduleResult, err := sched.Algorithm.Schedule() // 执行调度算法:Filter和Score等插件
...
err = sched.assume() // 假定pod
...
go func() { // 异步执行bind
...
err := sched.bind()
...
}
}
这个函数正是处理pod调度的主函数,而获取需要调度的pod是执行sched.NextPod(),然后就是执行调度框架里的各个注册插件,至此这就是所有的scheduler的工作代码了,如果要看详细的流程,可以查看我写的思维导图。
github思维导图地址:https://github.com/goofy-z/k8s-learning/blob/master/K8s源码学习/kube-scheduler/scheduler.xmind
在线思维导图:https://www.processon.com/view/link/6167925d5653bb1336dca0ca

 浙公网安备 33010602011771号
浙公网安备 33010602011771号