
爬取网页数据
爬取必应网站数据
import requests from lxml import etree url='https://cn.bing.com/' headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3823.400 QQBrowser/10.7.4307.400' } req = requests.get(url=url, headers=headers) req.encoding = 'utf-8' a=req.text b=req.content print(req.text) print(req.status_code) print(len(str(a))) print(len(str(b))) for i in range(20): req = requests.get(url=url, headers=headers) print(req.status_code)
爬取中国大学排行网站数据
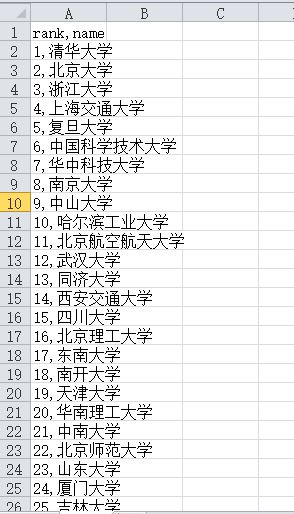
import requests from lxml import etree import csv url='https://www.shanghairanking.cn/rankings/bcur/201911' headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3823.400 QQBrowser/10.7.4307.400' } req=requests.get(url=url,headers=headers) req.encoding='utf-8' # print(req.text) html=etree.HTML(req.text) rank=html.xpath("//td[@class='align-left']/a/text()") r=1 with open(r'C:\Users\dell 7000\Desktop\text.xls', 'w', newline='')as f: csv_write = csv.writer(f, dialect='excel') csv_write.writerow(['rank','name']) for i in rank: item=[] item.append(r) item.append(i) r = r + 1 print(item) csv_write.writerow(item)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号