
1.大数据概述
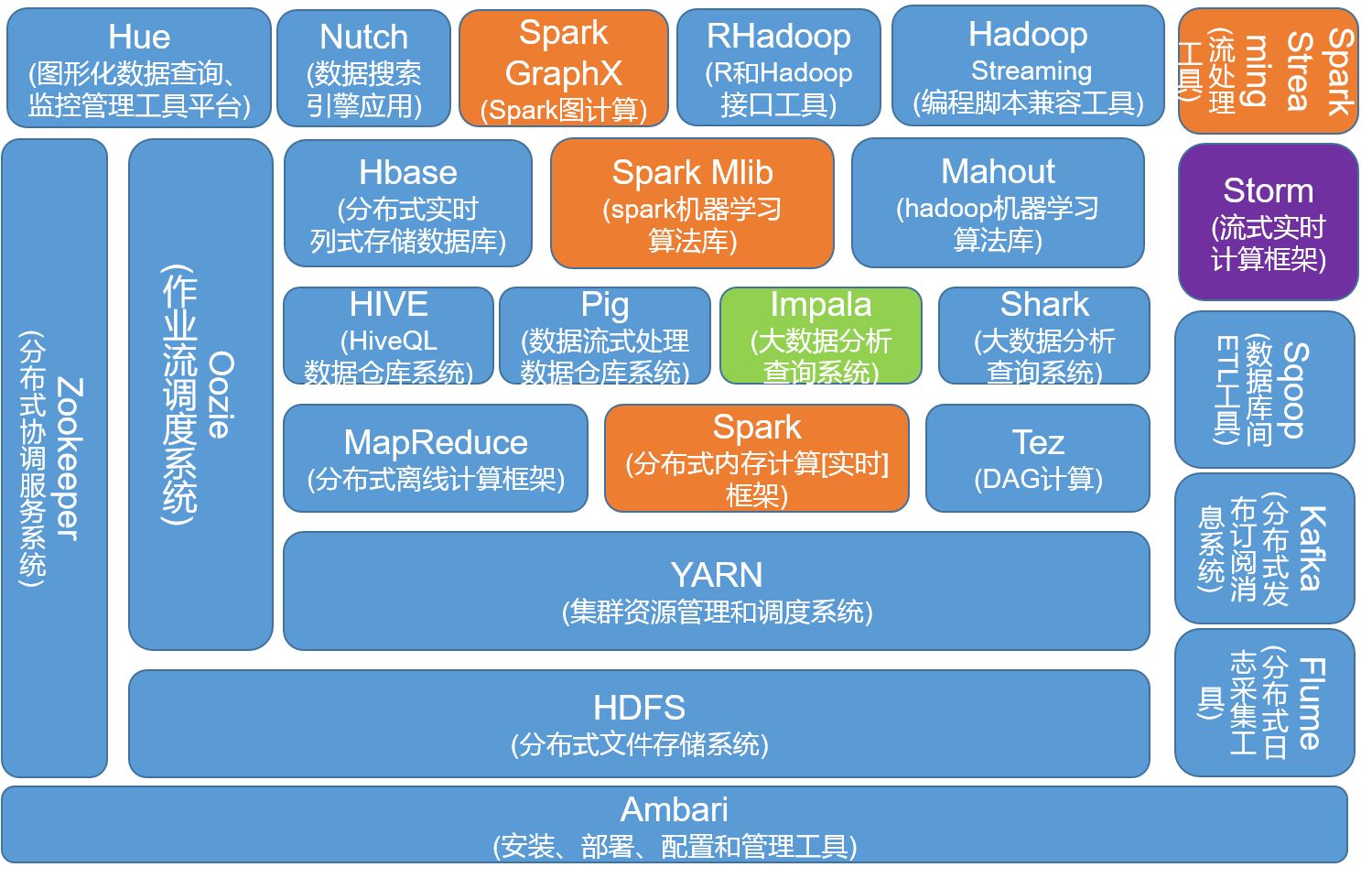
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
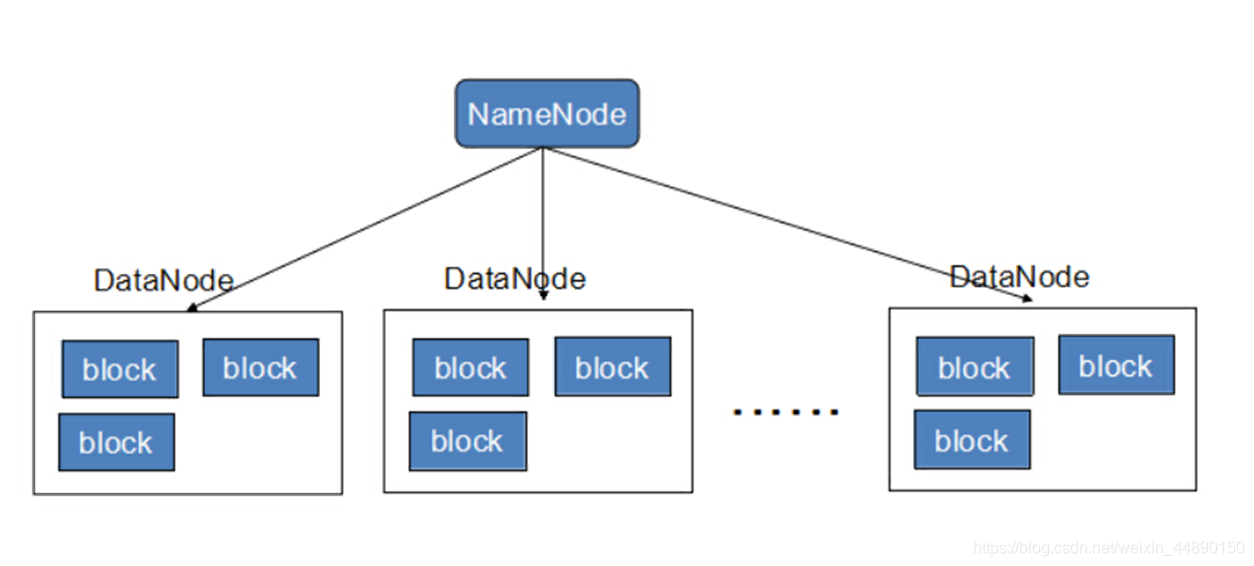
HDFS(hadoop分布式文件系统)
HDFS是hadoop中数据存储管理的基础,现在已经成为大数据的存储标准。它适合存储一次写入,多次读出的数据。同事它也是一个高容错的系统,能检测和应对相应的硬件故障。HDFS由DataNode和NameNode组成。前者负责存储数据,后者负责管理数据,NameNode记录着每个DataNode存储的数据内容,并暴露给上层的系统调用,同时也会根据上层的指令对DataNode进行增加、删除及负责。
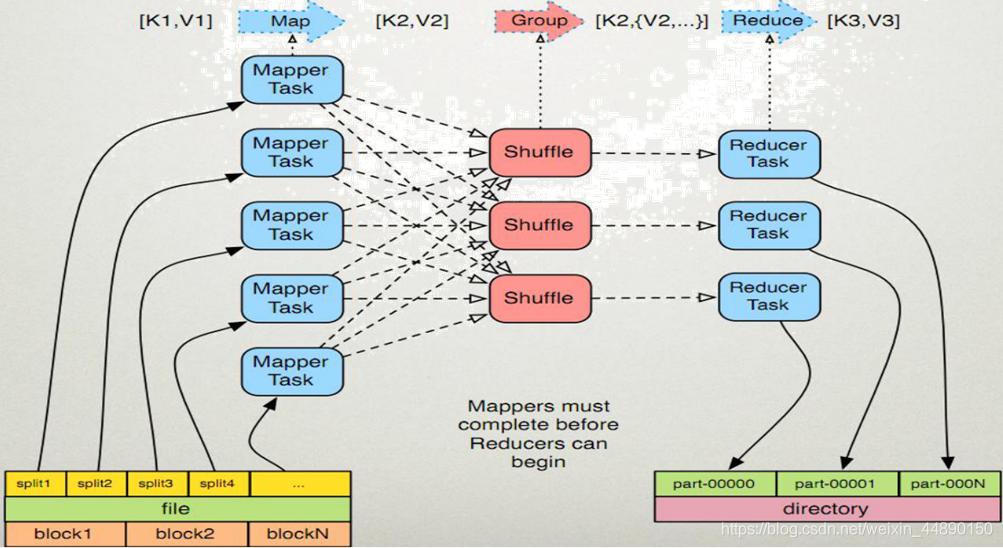
MapReduce(分布式计算框架)
MapReduce是一种计算模型,用于处理大数据量的计算。它将计算任务(Map task)分配给数据就近的处理节点(Rdece task),进行完运算后再合并导入结果,这样处理可以较好的去进行大量数据的调取,但也有不足的地方,就是是延时比较高,在处理实时流数据的情况下不适用。
Hive(基于hadoop的数据仓库)
Hive定义了一种类似sql的查询语言(hql),本质就是将hadoop包装成为使用起来简单的软件,用户可以使用sql语句进行常规查询。
Yarn(资源管理框架)
Yarn是负责集群资源跳读管理的组件。它的目标就是实现“一个集群多个框架”,即在一个集群之上部署一个统一的资源调度的管理框架Yarn。在Yarn上可以部署其他各类型的计算框架,例如Storm、OpenMPI等。
Hbase(分布式列存数据库)
Hbase是一个针对结构化数据的可伸缩,高可靠,高性能,分布式和面向列的动态模式数据库,主要用来存储非结构化和半结构化的松散数据。和传统关系类型数据库不同,Hbase采用了bigtable的数据模型及增强了稀疏排序映射表(key/value)。
Zookeeper(分布式协作服务)
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等
Sqoop(数据同步工具)
sqoop是sql-to-hadoop的缩写,主要用于传统数据库和hadoop之间传输数据。
数据的导入和导出本质上是mapreduce程序,充分利用了MR的并行化和容错性。
pig(基于hadoop的数据流系统)
Pig定义了一种数据流语言-pig latin,它将脚本转换为mapreduce任务在hadoop上执行。
通常用于离线分析。
flume(日志收集工具)
cloudera开源的日志收集系统,具有分布式,高可靠,高容错,易于定制和扩展的特点。他将数据从产生,传输,处理并写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在flume中定制数据发送方,从而支持收集各种不同协议数据。
2.对比Hadoop与Spark的优缺点。
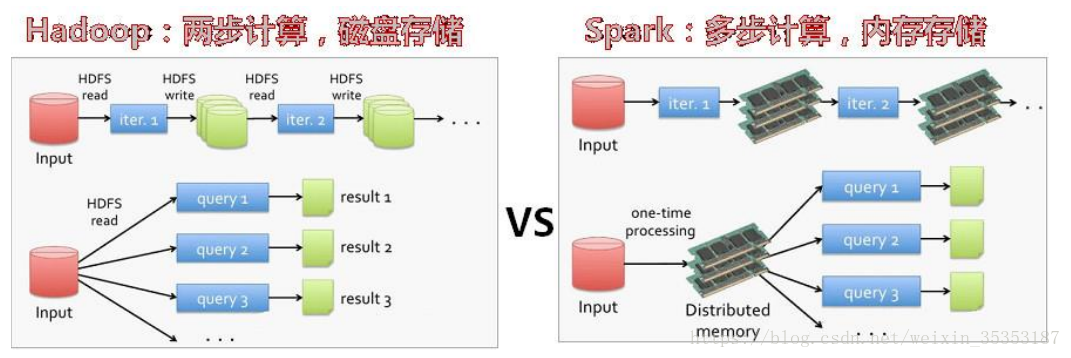
首先能与Spark比较的是Hadoop中的MapReduce,它们都是计算模式。
MapReduce的处理工程:读 – 处理 - 写磁盘 -- 读 - 处理 - 写
Spark的处理过程: 读 - 处理 - 处理 --(需要的时候)写磁盘 - 写
Spark是在借鉴了 MapReduce 后发展而来的,它继承了MapReduce分布式并行计算的各个优点并且改进了 MapReduce里 明显的缺陷。
Spark速递更快,它把运算的中间数据存放在内存,迭代计算效率更高;而MapReduce的中间结果需要保存到磁盘, 这样就会有磁盘io操作,影响其性能。
Spark容错性更高,它通过弹性分布式数据集RDD来实现高效容错,RDD是一组分布式的存储在节点内存中的只读性质的数据集,这些集合是弹性的,某一部分丢失或者出错,可以通过整个数据集的计算流程的血缘关系来实现重建,而MapReduce的容错就只能重新计算,相对来说成本较高。
总结:Spark是MapReduce的替代方案,并且兼容HDFS、Hive,且可以融入Hadoop的生态系统,以弥补MapReduce的不足。
3.如何实现Hadoop与Spark的统一部署?
由于Spark无法Hadoop生态中一些组件的功能,所以它还无法代替Hadoop。两者统一部署可以在Yarn上进行部署,并且有HDFS进行文件管理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号