索一美---第一次个人编程作业
作业介绍
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/ |
|---|---|
| 作业要求 | 第一次编程作业 |
| 作业目标 | 1.采集电视剧《在一起》的全部评论信息 2.数据处理3.数据分析,将采集到的评论信息做成词云图 |
| 作业源代码 | first-personal_work |
| 学号 | 211606618 |
时间分布
| 步骤 | 具体做法 | 时间 |
|---|---|---|
| 数据采集 | 采集腾讯视频里电视剧《在一起》的全部评论信息 | 1.5h |
| 数据处理 | 把所有数据下载到本地保存到json文件里面comments.json, 页面用js读取文件 | nh |
| 数据分析 | 将采集到的评论信息做成词云图 | nh |
| 上传代码到Github | 上传到Github | nh |
前言
看到这次作业我是慌乱的,看完作业要求无从下手,很多内容都是新知识,尤其是爬虫,之前没有接触过,上学期听大数据的同学常常讨论爬虫啊,反爬虫啊,异步加载之类的。开始之前我先学习了与爬虫相关的基础知识,接着下载了pycharm进行数据采集。在学习过程中查资料和询问同学对我的帮助很大。让我对爬虫,词云图有了初步了解。
具体步骤
一、采集影评数据
1.打开腾讯视频电视剧《在一起》的全部影评
2.按下Fn+F12,点击加载更多评论,按下Fn+F5刷新界面,可以看到会有多个以“v2?”开头的文件
3.多次点击加载更多评论,出现新的响应,获取到请求后,我们对这两的requesturl进行仔细分析,发现第二个url里的cursor值,是第一个url的preview里last的值,然后第一个url的最后1位数字+1,就是第二个url,即找到规律



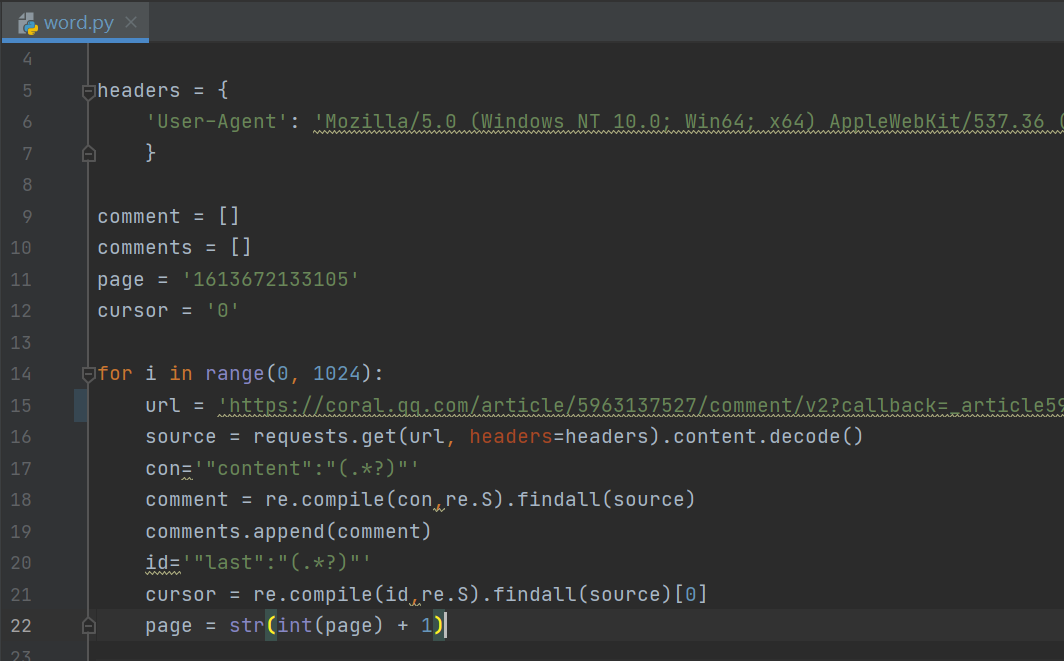
4.找到规律后,开始爬取数据,主要的思路是:抓取url地址-→遍历所有url-→正则提取评论-→保存结果为.json
主要代码:
二、数据处理
这里用的是jieba分词器分词,统计评论中的高频词及数量。jieba下载花费较长的时间,代码这块问题也比较大,问了问同学,参考她们的代码费劲的开始数据处理,这些知识对于我可以说是全新的,出现各种各样的问题,运行的时候库不存在,才知道自己没有导入库。在PyCharm里我觉得有一个好处就是,可以在settings设置添加库。准备工作做好以后,开始分词。
主要代码:
三、数据分析
结合js插件echarts.js和echarts-wordcloud.min.js完成index.html

四、上传代码到Github
详细步骤:
1.在文件夹右键,点击 Git Bash Here。
2.git init,进行初始化。
3.git remote add origin 仓库地址,连接仓库。
4.cd first-personal-work,进入文件夹。
5.git checkout -b crawl,切换分支。
6.git add 文件名,将文件添加到暂存区。
7.git commit -m "注释",提交到版本库。
注释的时候是中文命令出错,无法在运行,Ctrl+C才退出去,继续运行。
8.git push -u origin crawl,推送到远程仓库。
9.按上述步骤依次将文件提交到远程仓库。
10.git checkout main,切换分支。
11.git merge crawl 和 git merge chart,合并分支。
合并分支出现问题,只把chart合并到main,crawl无法合并,反复做了几次都不对,每次都显示已合并,错误太多无法挽救。
总结
这次作业对我来说是个很大的挑战,许多新知识需要去学习去摸索,虽然过程很艰难,脑子不断输入各种知识点,但是在完成后心情还是蛮不错的哈哈哈哈哈。再啰嗦几句,这次作业可能做的不是很完善,存在许多的瑕疵,这也是给我敲了一个警钟,知道自己很多的不足之处,还需要下功夫,不然与别人差距会越来越大。我希望自己可以通过这次作业,在以后的学习中,再遇到困难,能够克服一切,更加努力更加认真的去学习。
参考文献
“jieba”中文分词:Python 中文分词组件
echarts相关知识
Echarts中词云图的构造
Git官网


 浙公网安备 33010602011771号
浙公网安备 33010602011771号