
kube-batch 解析
kube-batch
https://github.com/kubernetes-sigs/kube-batch
一. 做什么的?
官方介绍:
A batch scheduler of kubernetes for high performance workload, e.g. AI/ML, BigData, HPC
二. 使用方式
apiVersion: batch/v1
kind: Job
metadata:
name: qj-1
spec:
backoffLimit: 6 #最大失败重试次数
completions: 6 #需要成功运行pod的次数
parallelism: 6 #并行运行pod的个数
template:
metadata:
annotations:
scheduling.k8s.io/group-name: qj-1
spec:
containers:
- image: busybox
imagePullPolicy: IfNotPresent
name: busybox
resources:
requests:
cpu: "1"
restartPolicy: Never
schedulerName: kube-batch # 指定调度器是 kube-batch
---
apiVersion: scheduling.incubator.k8s.io/v1alpha1
kind: PodGroup
metadata:
name: qj-1
spec:
minMember: 6 # 最小可用数量,达到这个数量才将任务调度到节点上去
三. 调度的单位
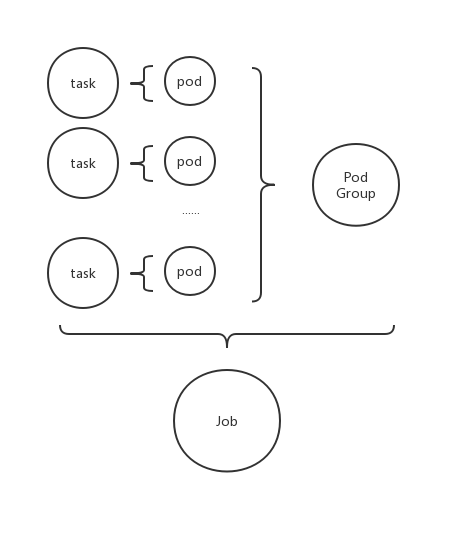
- 一个task对应一个pod
- 一个job对应一个或多个task
- Pod Group 记录该job内的pod的状态
- 一个job对应一个pod group
如果Job未声明一个对应的pod group ,
kube-batch将会给一个默认的
Pod Group 定义:
{
"metav1.TypeMeta":{},
"metav1.ObjectMeta":{},
"Spec":{
//用来做gang schedule
"MinMember":1,//default 1
"Queue":"",
"PriorityClassName":""
},
"Status":{
"Phase":"",//Pending, Running,Unknown
"Conditions":[],//optional
"Running":0,//正在运行的pod的数量
"Succeeded":0,//已经成功结束的pod的数量
"Failed":0,//失败的pod的数量
}
}
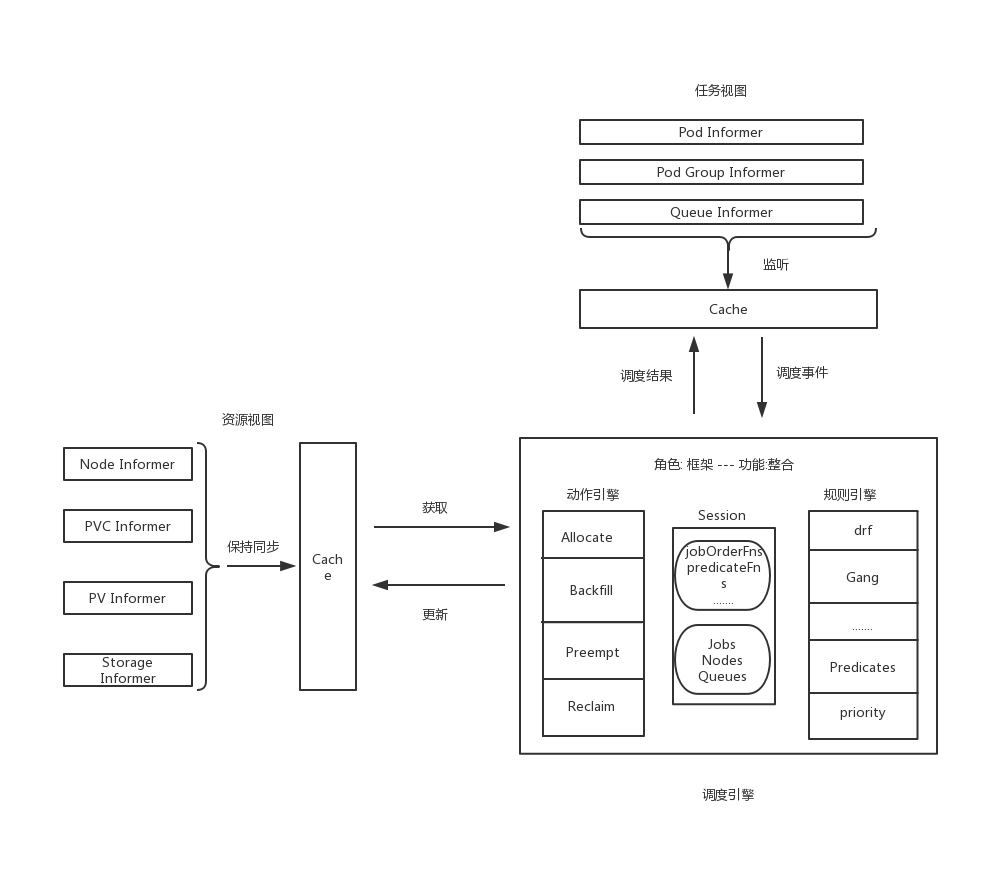
四. 整体结构
从数据流的角度给出项目框架结构:
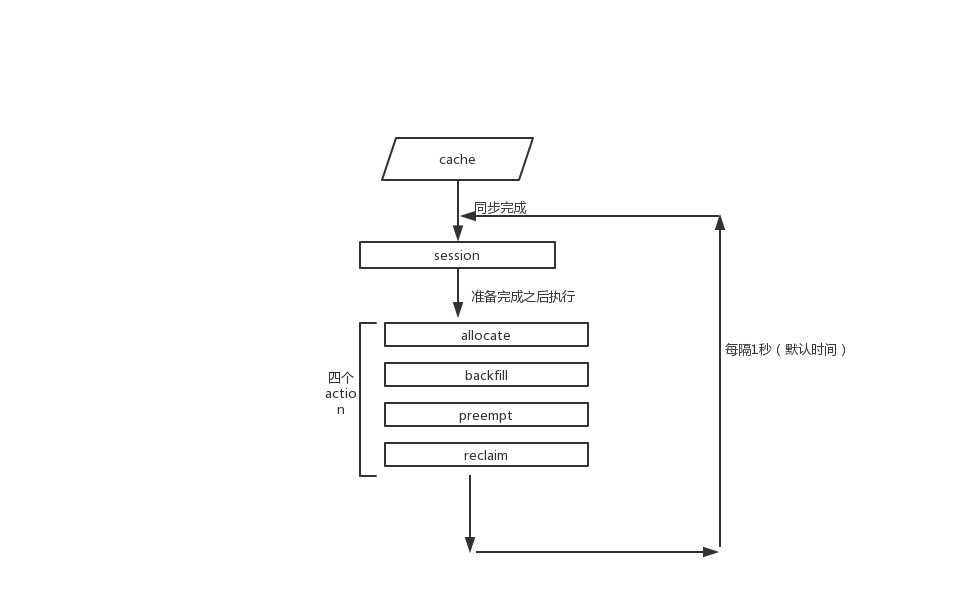
主调度流程:
五. 几个plugin
5.1 DRF (Dominant Resource Fairness)
主要资源(cpu,memory,gpu)的均衡使用算法。
目的: 尽量避免集群内某一类资源 使用比例偏高,而其他类型资源使用比例却很低的不良状态
方式: 在调度时,让具有最低资源占用比例的任务具有高优先级
细节:
DRF计算了每个job的一个share值,share值的计算公式为:
share = Max(someKindOfResource.allocated / totalResourceInTheCluster)
share = 最大的某类资源申请比例
func (drf *drfPlugin) calculateShare(allocated, totalResource *api.Resource) float64 {
res := float64(0)
for _, rn := range totalResource.ResourceNames() {
share := helpers.Share(allocated.Get(rn), totalResource.Get(rn))
if share > res {
res = share
}
}
return res
}
DRF 定义两个Function ,分别是preemptableFn 和 jobOrderFn:
jobOrderFn 是job的排序函数,会让share值越小的job排在最前面,即拥有最高的优先级,这个是实现DRF算法的关键。
preemptableFn 返回可抢占的job列表,job的筛选规则是 :如果待选job的share值大于将被调度的job的share值,则选中该待选job。
5.2 Gang
Gang策略要实现的功能: 只有当指定的某几个pod都分配到资源后,才正在地将pod调度到节点上.
定义的几个plugin function
preemptableFn为避免Gang的策略被preempt和reclaim干扰,定义了preemptableFn,排除那些还未准备就绪的job,避免被抢占。
虽然实际上这些job未真正调度到node上去,但是确实从逻辑上把资源分配给它了
-
jobOrderFn为让已经就绪的job尽快被调度到节点,定义了jobOrderFn,让已经就绪的job拥有更高的优先级 -
jobReadyFn用来判断一个job是否已经就绪。
解析Kube-Batch 实现gang的方式:
无论是k8s默认的scheduler, 还是kube-batch ,再进行调度时都是先从逻辑上分配资源给pod,等满足某一条件之后,才真正将pod 调度到某一个节点上。
kube-batch/pkg/scheduler/framework/session.go Line 281
if ssn.JobReady(job) {
for _, task := range job.TaskStatusIndex[api.Allocated] {
if err := ssn.dispatch(task); err != nil {
glog.Errorf("Failed to dispatch task <%v/%v>: %v",task.Namespace, task.Name, err)
return err
}
}
}
dispatch内包bind job到node 等实际的调度动作.
jobReady会调用所有注册了的 plugin的 Ready 判定函数,只有都判定为 ready ,才返回true。
而gang plugin里面定义的ready判定函数实际上是调用 job 自带的ready函数,定义在
kube-batch/pkg/scheduler/api/job_info.go#L415
// ReadyTaskNum returns the number of tasks that are ready.
func (ji *JobInfo) ReadyTaskNum() int32 {
occupid := 0
for status, tasks := range ji.TaskStatusIndex {
if AllocatedStatus(status) ||
status == Succeeded {
occupid = occupid + len(tasks)
}
}
return int32(occupid)
}
// Ready returns whether job is ready for run
func (ji *JobInfo) Ready() bool {
occupied := ji.ReadyTaskNum()
return occupied >= ji.MinAvailable
}
5.3 Proportion
Proportion 实现了队列.
type queueAttr struct {
queueID api.QueueID // 队列的id
name string //队列的名字
weight int32 // 队列的权重,决定分配到的资源的多少
share float64 //参考 drf处的share
deserved *api.Resource //声明的资源总量
allocated *api.Resource //实际分配到的资源总量
request *api.Resource //该队列中所有job声明的要分配的资源总量
}
Proportion 根据各个队列声明的权重和全局的资源总量 初始化deserved的值,根据全局的job 初始化
allocated 和 request的值。并监听全局的资源释放 和 申请事件 更新队列的状态。
定义的几个plugin function:
- QueueOrderFn
QueueOrderFn 会决定哪一个队列里的job在调度时会被优先考虑,这里沿用了DRF处jobOrderFn的逻辑,
即share值最小的queue 会最优先被考虑.
- OverusedFn
判断queue的资源使用是否已经超出限制了,即
allocated > deserved == true
- ReclaimableFn
判断一个task是否可以被召回,如果召回之后使得已经分配到的资源小于等于deserved 就不应该被召回。
5.4 其他几个plugin
略
六. 四个Action
kube-batch 默认只开启了
Allocate和Backfill
6.1 Allocate
功能 : 将pod(task)分配到某个节点
6.2 Backfill
功能 : 调度未设置资源使用量的pod到节点(资源使用量 = 工作容器和初始化容器的各维度资源的最大值)
6.3 Reclaim
功能 : 召回满足条件的pod
6.4 Preempt
功能: 抢占已经调度了的满足条件的pod,并将目标pod调度上去

 浙公网安备 33010602011771号
浙公网安备 33010602011771号