


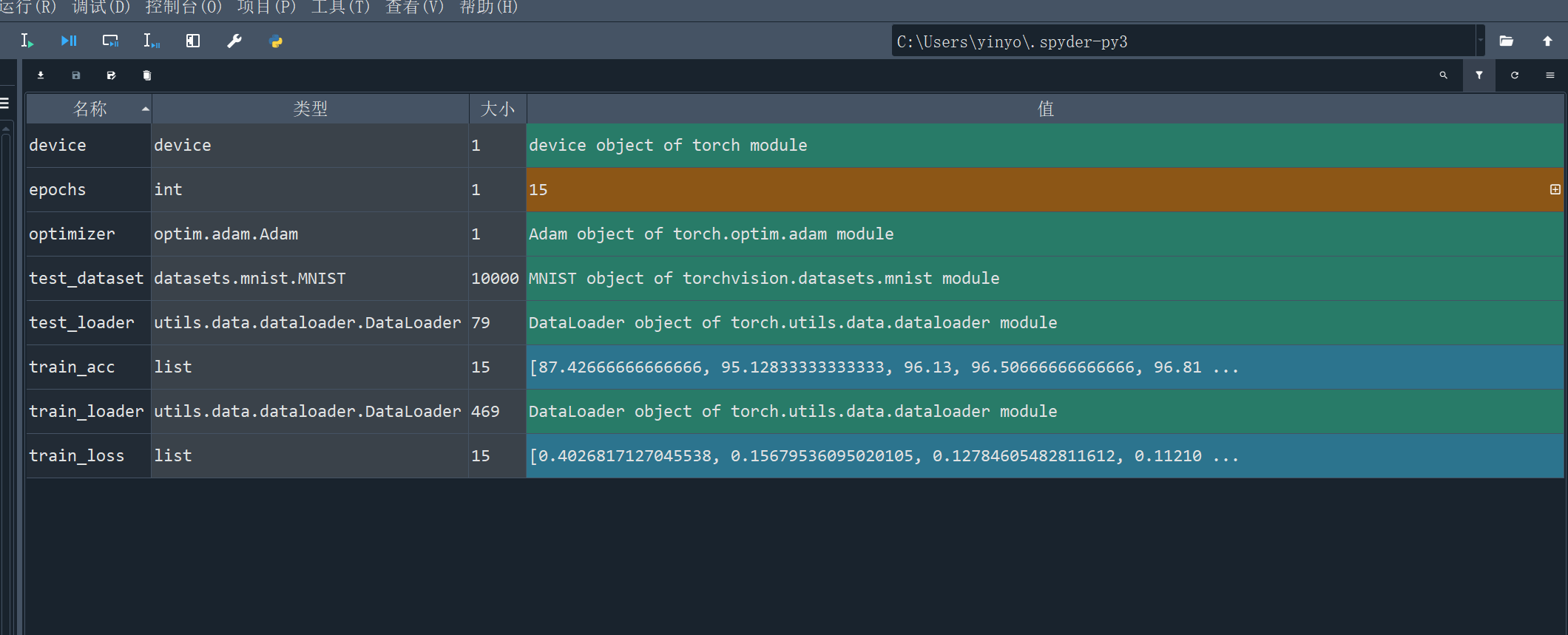
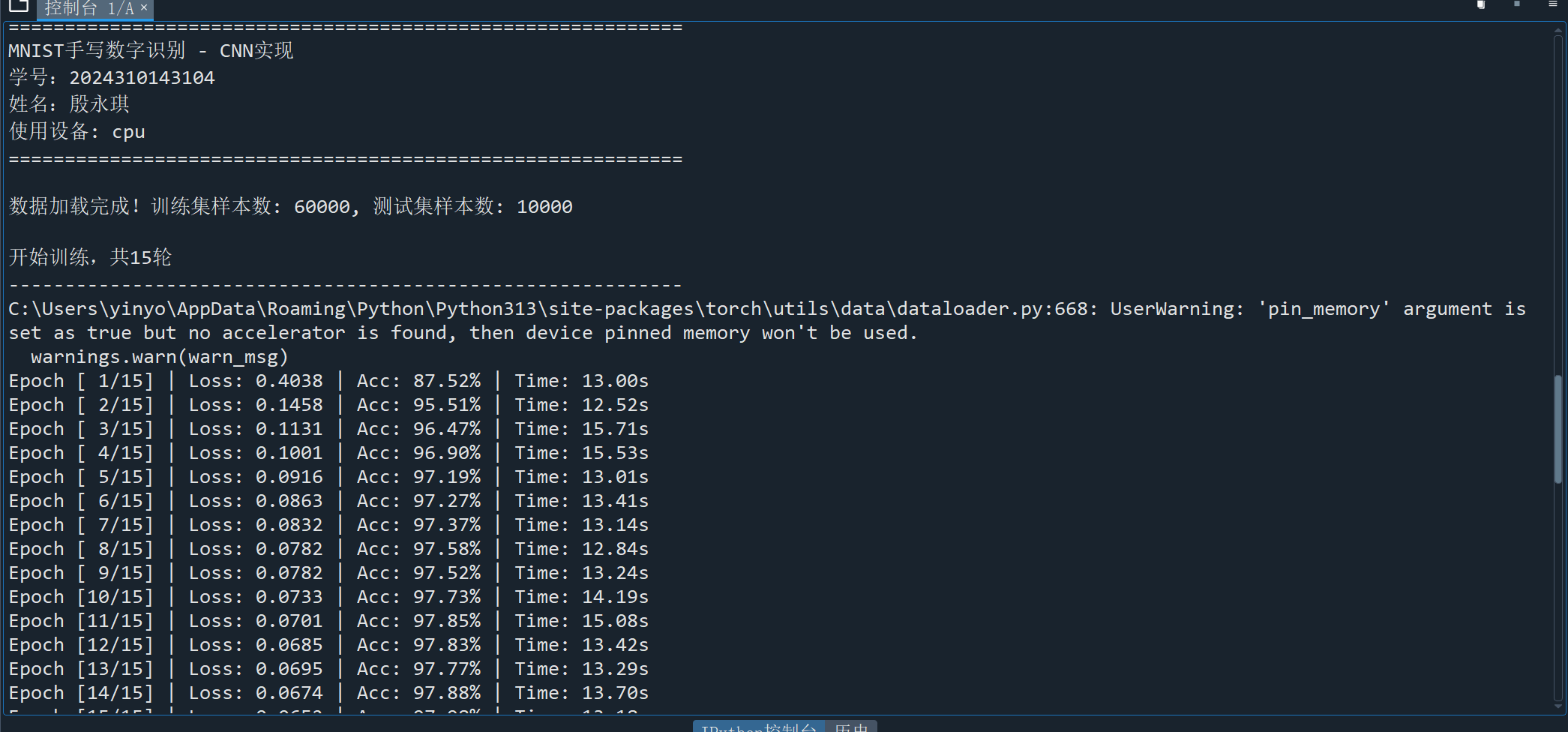
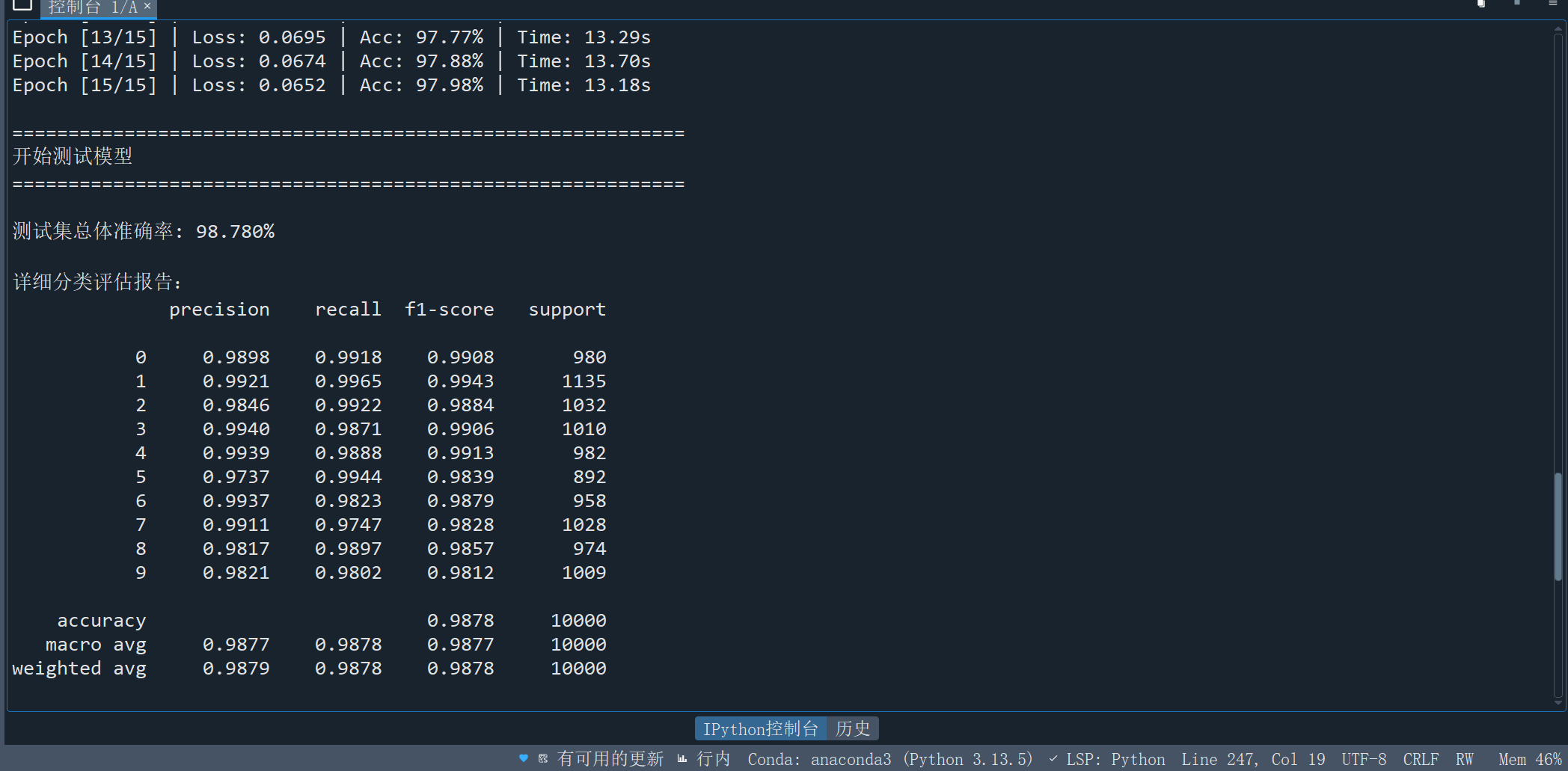
# 导入必要的库(去重、排序) import os import time import numpy as np import matplotlib.pyplot as plt from PIL import Image from sklearn.metrics import classification_report import torch import torch.nn as nn import torch.nn.functional as F from torch import optim from torch.autograd import Variable from torchvision import datasets, transforms from torch.utils.data import DataLoader, Dataset # 设置设备(CPU/GPU) device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # -------------------------- 数据预处理与加载 -------------------------- def get_data_transform(): """获取数据预处理管道""" return transforms.Compose([ transforms.ToTensor(), # 转换为Tensor transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差 ]) def load_mnist_data(batch_size=128): """ 加载MNIST数据集 返回:训练数据加载器、测试数据加载器、测试数据集 """ transform = get_data_transform() # 训练数据集 train_dataset = datasets.MNIST( root='./data', train=True, transform=transform, download=True # 若本地无数据则自动下载 ) # 测试数据集 test_dataset = datasets.MNIST( root='./data', train=False, transform=transform, download=True ) # 数据加载器 train_loader = DataLoader( train_dataset, batch_size=batch_size, shuffle=True, # 训练集打乱 num_workers=2, # 多线程加载(加速) pin_memory=True # 内存固定(GPU训练加速) ) test_loader = DataLoader( test_dataset, batch_size=batch_size, shuffle=False, # 测试集不打乱 num_workers=2, pin_memory=True ) return train_loader, test_loader, test_dataset # -------------------------- CNN模型定义 -------------------------- class MNIST_CNN(nn.Module): """ 用于MNIST分类的简单CNN模型 结构:Conv2d -> ReLU -> MaxPool2d -> Conv2d -> ReLU -> MaxPool2d -> Dropout -> Linear """ def __init__(self): super(MNIST_CNN, self).__init__() # 第一层卷积:输入1通道(灰度图),输出16通道,3x3卷积核,1像素填充 self.conv1 = nn.Conv2d(1, 16, kernel_size=3, padding=1) self.pool1 = nn.MaxPool2d(2, 2) # 2x2最大池化,步长2 # 第二层卷积:输入16通道,输出16通道,3x3卷积核,1像素填充 self.conv2 = nn.Conv2d(16, 16, kernel_size=3, padding=1) self.pool2 = nn.MaxPool2d(2, 2) # 全连接层:输入维度16*7*7(2次池化后28->14->7),输出10类(0-9) self.fc = nn.Linear(16 * 7 * 7, 10) self.dropout = nn.Dropout(0.5) # Dropout防止过拟合 def forward(self, x): """前向传播""" # 第一层卷积+激活+池化 x = self.pool1(F.relu(self.conv1(x))) # 第二层卷积+激活+池化 x = self.pool2(F.relu(self.conv2(x))) # 展平特征图(batch_size, -1) x_flat = x.view(x.size(0), -1) # Dropout + 全连接层 x_flat = self.dropout(x_flat) output = self.fc(x_flat) return output, x_flat # 返回预测结果和展平后的特征 # -------------------------- 训练函数 -------------------------- def train_model(model, train_loader, optimizer, criterion, epochs=15): """ 训练模型 参数: model: 待训练的模型 train_loader: 训练数据加载器 optimizer: 优化器 criterion: 损失函数 epochs: 训练轮数 返回: train_loss: 每轮训练损失 train_acc: 每轮训练准确率 """ model.train() # 设为训练模式(启用Dropout等) train_loss_history = [] train_acc_history = [] print(f"\n开始训练,共{epochs}轮") print("-" * 60) for epoch in range(epochs): start_time = time.time() running_loss = 0.0 # 累计损失 correct = 0 # 正确预测数 total = 0 # 总样本数 for images, labels in train_loader: # 数据移到设备上 images, labels = images.to(device), labels.to(device) # 梯度清零 optimizer.zero_grad() # 前向传播(只取预测结果) outputs, _ = model(images) # 计算损失 loss = criterion(outputs, labels) # 反向传播+参数更新 loss.backward() optimizer.step() # 累计损失 running_loss += loss.item() # 计算准确率 _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() # 计算本轮平均损失和准确率 epoch_loss = running_loss / len(train_loader) epoch_acc = 100 * correct / total # 保存历史记录 train_loss_history.append(epoch_loss) train_acc_history.append(epoch_acc) # 打印训练信息 end_time = time.time() print(f"Epoch [{epoch+1:2d}/{epochs}] | Loss: {epoch_loss:.4f} | Acc: {epoch_acc:.2f}% | Time: {end_time-start_time:.2f}s") return train_loss_history, train_acc_history # -------------------------- 测试函数 -------------------------- def evaluate_model(model, test_loader): """ 评估模型性能 参数: model: 训练好的模型 test_loader: 测试数据加载器 """ model.eval() # 设为评估模式(禁用Dropout等) all_preds = [] all_labels = [] print("\n" + "="*60) print("开始测试模型") print("="*60) with torch.no_grad(): # 禁用梯度计算(加速+省内存) for images, labels in test_loader: images, labels = images.to(device), labels.to(device) # 前向传播 outputs, _ = model(images) _, predicted = torch.max(outputs.data, 1) # 收集预测结果和真实标签 all_preds.extend(predicted.cpu().numpy()) all_labels.extend(labels.cpu().numpy()) # 转换为numpy数组 all_preds = np.array(all_preds) all_labels = np.array(all_labels) # 计算总体准确率 accuracy = (all_preds == all_labels).mean() * 100 print(f"\n测试集总体准确率: {accuracy:.3f}%") # 输出详细分类报告(精确率、召回率、F1分数) print("\n详细分类评估报告:") target_names = [str(i) for i in range(10)] # 类别名称(0-9) report = classification_report( all_labels, all_preds, target_names=target_names, digits=4 # 保留4位小数 ) print(report) # -------------------------- 结果可视化函数 -------------------------- def plot_training_results(train_loss, train_acc, epochs): """ 绘制训练损失和准确率曲线 """ plt.rcParams['font.sans-serif'] = ['SimHei'] # 支持中文显示 plt.figure(figsize=(12, 5)) # 绘制损失曲线 plt.subplot(1, 2, 1) plt.plot(range(1, epochs+1), train_loss, 'b-', linewidth=2, label='训练损失') plt.xlabel('训练轮数 (Epoch)', fontsize=12) plt.ylabel('损失值 (Loss)', fontsize=12) plt.title('训练损失变化曲线', fontsize=14, fontweight='bold') plt.grid(True, alpha=0.3) plt.legend() # 绘制准确率曲线 plt.subplot(1, 2, 2) plt.plot(range(1, epochs+1), train_acc, 'r-', linewidth=2, label='训练准确率') plt.xlabel('训练轮数 (Epoch)', fontsize=12) plt.ylabel('准确率 (%)', fontsize=12) plt.title('训练准确率变化曲线', fontsize=14, fontweight='bold') plt.grid(True, alpha=0.3) plt.legend() plt.tight_layout() # 自动调整子图间距 plt.show() # -------------------------- 主函数 -------------------------- if __name__ == '__main__': # 打印个人信息和设备信息 print("="*60) print("MNIST手写数字识别 - CNN实现") print("学号:2024310143104") print("姓名:殷永琪") print(f"使用设备: {device}") print("="*60) # 1. 加载数据 train_loader, test_loader, test_dataset = load_mnist_data(batch_size=128) print(f"\n数据加载完成!训练集样本数: {len(train_loader.dataset)}, 测试集样本数: {len(test_loader.dataset)}") # 2. 初始化模型、优化器和损失函数 model = MNIST_CNN().to(device) optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器 criterion = nn.CrossEntropyLoss() # 交叉熵损失(适用于分类任务) # 3. 训练模型 epochs = 15 train_loss, train_acc = train_model(model, train_loader, optimizer, criterion, epochs) # 4. 评估模型 evaluate_model(model, test_loader) # 5. 可视化训练结果 plot_training_results(train_loss, train_acc, epochs)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号