
第一次个人编程作业
https://github.com/yyq3/031902629
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 10 | 20 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 300 | 330 |
| · Design Spec | · 生成设计文档 | 5 | 30 |
| · Design Review | · 设计复审 | 0 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 10 |
| · Design | · 具体设计 | 150 | 150 |
| · Coding | · 具体编码 | 300 | 360 |
| · Code Review | · 代码复审 | 0 | 0 |
| · Test | · 测试(自我测试,修改代码,提交修改 | 60 | 200 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 30 | 90 |
| · Size Measurement | · 计算工作量 | 5 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 60 |
| · 合计 | 900 | 1270 |
二、计算模块接口
(3.1)计算模块接口的设计与实现过程。
整个程序定义了敏感词类、文本类、答案类,使用自定义的read函数、search函数、print函数。主要思想是使用read函数将words.txt和org.txt的信息读入(包括长度,内容等),并存放至敏感词类数组和文本类数组,然后通过search函数遍历,将得到的答案的有关信息(例如答案的范围、对应哪行、对应哪个敏感词等)存放至答案组,再将答案组的答案按照行的前后来排序,最后通过print函数输出答案。由于新学的ac自动机还未完全掌握,用ac自动机写的程序根本就跑不起来,于是就采用了暴力遍历,以至于只能用于检测最基本的标准汉字(汉字中插入字符、数字)、标准字母(字母中插入数字、符号),拼音、部首拆分、繁体字、缩写等敏感词检测都未能实现。至于本算法的关键,就是暴力,独到之处,嗯,我也编不来。
(3.2)计算模块接口部分的性能改进。
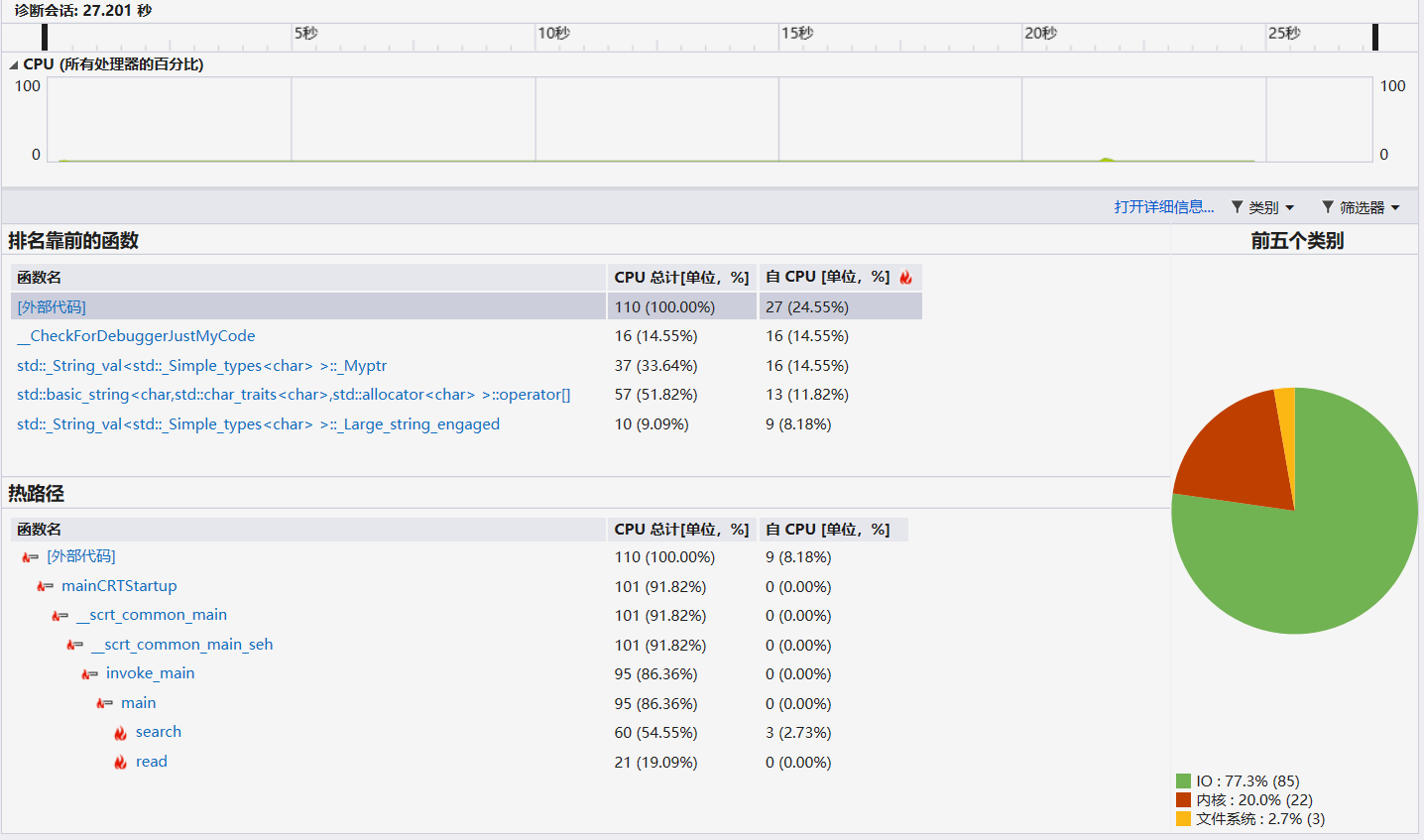
从上图可以看出,search函数消耗最大,毕竟是暴力算法,消耗最多的肯定是暴力部分,用了三重的for循环,复杂度为敏感词数文本行数最长行的字符数。
对于暴力算法来说,还没有任何改进的思路。
(3.3)计算模块部分单元测试展示。
由于所写程序中全局变量应用较多,进行整个程序的测试。思路是设置汉字敏感词、汉字中插入字符的敏感词、英文敏感词、英文中插入字符的敏感词,同时需要防止将非敏感词的部分判定为敏感词。

对于测试组给出的数据来说……还是只能怪自己

(3.4)计算模块部分异常处理说明。

使用string::substr函数,在检测汉字,确定文本内容头、尾字符,截取相关内容时会使得截取的内容后多一个汉字(字符),后来改用for循环输出截取内容解决。
三、心得
好家伙,原来我感觉自己是个菜鸟,现在我发现原来我连菜鸟都算不上,甚至离大家所说的菜鸟一定的差距。这次作业对我来说确实是一个很大的挑战,开始看作业,我就一脸懵,从头到尾我感觉我没一个地方会,舍友们看了我的作业后在幸灾乐祸的同时给了我一些方向,之后我忍着悲伤开始学习,那是真滴折磨。通过这次作业,我确实学到了一些东西,比如文件的读入等,也尝试着用新的算法写程序(然而最终没成功),同时程序变量命名的习惯也好了挺多,不再是之前从a开始,轮到哪个是哪个,但是在做作业的过程中,单元测试还没有学会,还有一些算法没有弄懂,还需要花更多的时间进行学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号