梳理caffe代码net(四)
net定义网络, 整个网络中含有很多layers, net.cpp负责计算整个网络在训练中的forward, backward过程, 即计算forward/backward 时各layer的gradient。
看一下官网的英文描述:
The forward and backward passes are the essential computations of a Net.
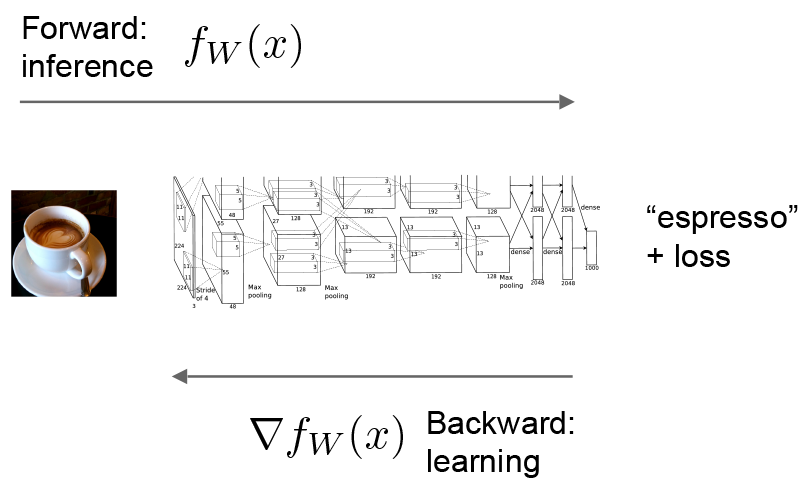
Let’s consider a simple logistic regression classifier.
The forward pass computes the output given the input for inference.In forward Caffe composes the computation of each layer to compute the “function” represented by the model.This pass goes from bottom to top.
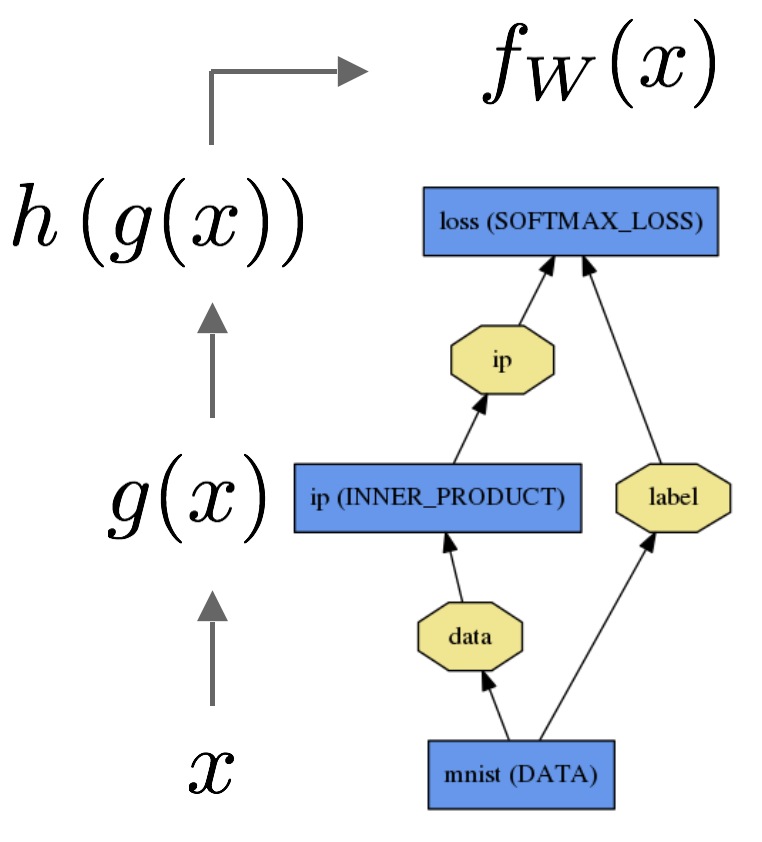
The data x is passed through an inner product layer for g(x) then through a softmax for h(g(x)) and softmax loss to give fW(x).
The backward pass computes the gradient given the loss for learning.In backward Caffe reverse-composes the gradient of each layer to compute the gradient of the whole model by automatic differentiation.This is back-propagation.This pass goes from top to bottom.
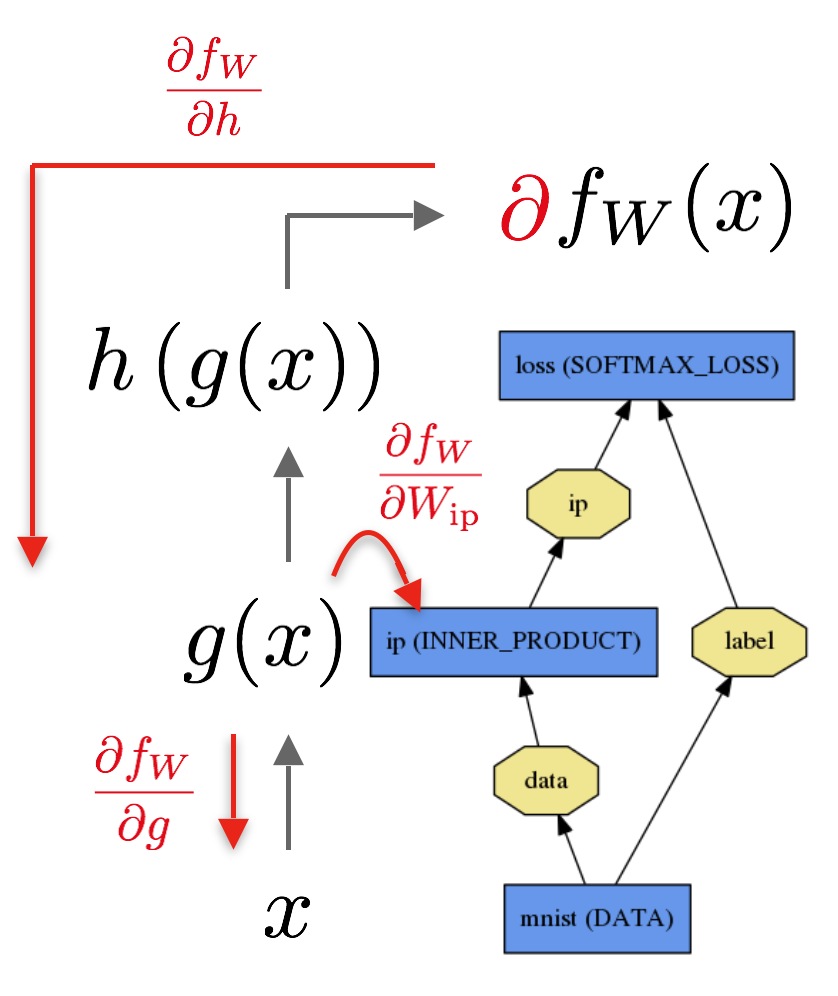
The backward pass begins with the loss and computes the gradient with respect to the output∂fW∂h. The gradient with respect to the rest of the model is computed layer-by-layer through the chain rule. Layers with parameters, like theINNER_PRODUCT layer, compute the gradient with respect to their parameters∂fW∂Wip during the backward step.
These computations follow immediately from defining the model: Caffe plans and carries out the forward and backward passes for you.
- The
Net::Forward()andNet::Backward()methods carry out the respective passes whileLayer::Forward()andLayer::Backward()compute each step. - Every layer type has
forward_{cpu,gpu}()andbackward_{cpu,gpu}()methods to compute its steps according to the mode of computation. A layer may only implement CPU or GPU mode due to constraints or convenience.
The Solver optimizes a model by first calling forward to yield the output and loss, then calling backward to generate the gradient of the model, and then incorporating the gradient into a weight update that attempts to minimize the loss. Division of labor between the Solver, Net, and Layer keep Caffe modular and open to development.
net的实现:
- #include <algorithm>
- #include <map>
- #include <set>
- #include <string>
- #include <utility>
- #include <vector>
- #include "caffe/common.hpp"
- #include "caffe/layer.hpp"
- #include "caffe/net.hpp"
- #include "caffe/proto/caffe.pb.h"
- #include "caffe/util/insert_splits.hpp"
- #include "caffe/util/io.hpp"
- #include "caffe/util/math_functions.hpp"
- #include "caffe/util/upgrade_proto.hpp"
- #include "caffe/util/channel.hpp"
- #include "caffe/util/mpi_functions.hpp"
- #include "caffe/test/test_caffe_main.hpp"
- #include "caffe/vision_layers.hpp"
- namespace caffe {
- /*
- 功能:调用Init函数初始化网络
- 输入:NetParameter& param
- 输出:无
- */
- template <typename Dtype>
- Net<Dtype>::Net(const NetParameter& param) {
- Init(param);
- }
- /*
- 功能:调用Init函数初始化网络
- 输入:string& param_file
- 输出:无
- */
- template <typename Dtype>
- Net<Dtype>::Net(const string& param_file, Phase phase) {
- NetParameter param;
- ReadNetParamsFromTextFileOrDie(param_file, ¶m);
- param.mutable_state()->set_phase(phase);
- Init(param);
- }
- /*
- 功能:初始化网络
- 输入:NetParameter& in_param
- 输出:无
- 步骤:
- <1> 调用InsertSplits()函数从in_param读入新网络到param
- <2> 定义name_,blob_name_to_idx,available_blobs,num_layers
- <3> param.input_size()返回输入层blob的个数;
- param.input(i)表示第i个blob的名字;
- param.layers_size()返回网络的层数。
- <4> 对每一个输入层的blob:
- 产生一块和当前blob一样大的空间 e.g. imput_dim=[12 55 66 39 20 24 48 64]表示第一个blob的四个维数为 12 55 66 39,第二个为 20 24 48 64 接着blob_pointer指向这块空间
- blob_pointer压到blobs_中 vector<shared_ptr<Blob<Dtype>>> blobs_
- blob_name压到blob_names_中 vector<string> blob_names_
- param.force_backward()压到blob_need_backward_中vector<bool> blob_need_backward_
- i 压到 net_input_blob_indices_中 net_input_blob_indices_ -> vector
- blob_pointer.get() 压到 net_input_blobs_中
- 注意与blobs_的区别
- vector<shared_ptr<Blob<Dtype>>> blobs_
- vector<Blob<Dtype>*> net_input_blobs_
- shared_ptr类型的参数调用.get()则得到Blob*类型
- map<string, int> blob_name_to_idx
- 初始化为输入层的每个blob的名字 set<string> available_blobs
- 计算所需内存 memory_used += blob_pointer->count()
- <5> 存每一层的输入blob指针 vector<vector<Blob<Dtype>*> > bottom_vecs_
- 存每一层输入(bottom)的id vector<vector<int> > bottom_id_vecs_
- 存每一层输出(top)的blob vector<vector<Blob<Dtype>*> > top_vecs_
- 用网络的层数param.layers_size()去初始化上面四个变量
- vector<vector<int> > top_id_vecs_
- <6> 对第i层(很大的一个for循环):
- param.layers(i)返回的是关于第当前层的参数:
- layer_param = param.layers(i)
- 把当前层的参数转换为shared_ptr<Layer<Dtype>>,并压入到layers_中
- 把当前层的名字压入到layer_names_:vector<string> layer_names_
- 判断当前层是否需要反馈 need_backward = param.force_backward()
- 下面开始产生当前层:分为处理bottom的blob和top的blob两个步骤
- 对第j个bottom的blob:
- layer_param.bottom_size()存的是当前层的输入blob数量
- layer_param.bottom(j)存的是第j个输入blob的名字
- 读取当前blob的id,其中blob_name_to_idx在输入层初始化过了
- blob_name_to_idx[blob_name] = i
- 输出当前blob的名字
- 存入第j个输入blob的指针bottom_vecs_[i].push_back(blobs_[blob_id].get())
- 存入第j个输入blob的id bottom_id_vecs_[i].push_back(blob_id)
- 更新need_backward
- 从available_blobs中删除第j个blob的名字
- 对第j个top的blob:
- layer_param.top_size()存的是当前层的输出blob数量
- layer_param.top(j)存的是第j个输出blob的名字
- 判断是否进行同址计算
- 输出当前blob的名字
- 定义一块新的blob空间,用blob_pointer指向这块空间
- 把这个指针存入到blobs_中
- 把blob_name、force_backward、idx存入对应的容器中
- 向available_blobs插入当前blob的名字
- top_vecs_[i]对于第i层,插入当前blob的指针
- top_id_vecs_[i]对于第i层,插入当前blob的id
- 输出当前层位于top的blob的信息
- 计算所需内存
- 判断当前层i是否需要backward
- <7> 所有名字在available_blobs中的blob为当前层的输出blob,存入net_output_blobs_中
- <8> 建立每个blob的name和index的对应关系map:blob_names_index_
- <9> 建立每个层的name和index的对应关系map:layer_names_index_
- <10> 调用GetLearningRateAndWeightDecay函数
- */
- template <typename Dtype>
- void Net<Dtype>::Init(const NetParameter& in_param) {
- // Set phase from the state.
- phase_ = in_param.state().phase();
- // Filter layers based on their include/exclude rules and
- // the current NetState.
- NetParameter filtered_param;
- FilterNet(in_param, &filtered_param);
- LOG(INFO) << "Initializing net from parameters: " << std::endl
- << filtered_param.DebugString();
- // Create a copy of filtered_param with splits added where necessary.
- NetParameter param;
- InsertSplits(filtered_param, ¶m);
- // Basically, build all the layers and set up their connections.
- name_ = param.name();
- map<string, int> blob_name_to_idx;//blob_name_to_idx是一个map,其关键字是不重复的
- set<string> available_blobs;//available_blobs是一个set,其关键字是不重复的
- CHECK(param.input_dim_size() == 0 || param.input_shape_size() == 0)
- << "Must specify either input_shape OR deprecated input_dim, not both.";
- if (param.input_dim_size() > 0) {
- // Deprecated 4D dimensions.
- CHECK_EQ(param.input_size() * 4, param.input_dim_size())
- << "Incorrect input blob dimension specifications.";
- } else {
- CHECK_EQ(param.input_size(), param.input_shape_size())
- << "Exactly one input_shape must be specified per input.";
- }
- memory_used_ = 0;
- // set the input blobs
- for (int input_id = 0; input_id < param.input_size(); ++input_id) {
- const int layer_id = -1; // inputs have fake layer ID -1
- AppendTop(param, layer_id, input_id, &available_blobs, &blob_name_to_idx);
- }
- DLOG(INFO) << "Memory required for data: " << memory_used_ * sizeof(Dtype);
- // For each layer, set up its input and output
- bottom_vecs_.resize(param.layer_size());
- top_vecs_.resize(param.layer_size());
- bottom_id_vecs_.resize(param.layer_size());
- param_id_vecs_.resize(param.layer_size());
- top_id_vecs_.resize(param.layer_size());
- bottom_need_backward_.resize(param.layer_size());
- for (int layer_id = 0; layer_id < param.layer_size(); ++layer_id) {
- // Inherit phase from net if unset.
- if (!param.layer(layer_id).has_phase()) {
- param.mutable_layer(layer_id)->set_phase(phase_);//实参phase_是网络的phase,为模板类layer设置shape_属性
- }
- // Setup BN params implicitly.
- if (param.layer(layer_id).type() == "BN") {
- LayerParameter* layer_param = param.mutable_layer(layer_id);
- if (layer_param->param_size() > 2) {
- LOG(FATAL) << "Layer " << layer_param->name()
- << " must have no more than two specified params";
- }
- while (layer_param->param_size() < 4) {
- ParamSpec* param = layer_param->add_param();
- if (layer_param->param_size() <= 2) {
- param->set_lr_mult(1);
- param->set_decay_mult(0);
- } else {
- param->set_lr_mult(0);
- param->set_decay_mult(0);
- }
- }
- }
- // Setup layer.
- const LayerParameter& layer_param = param.layer(layer_id);
- //检查LayerParameter类型propagate_down成员的个数师傅达标
- if (layer_param.propagate_down_size() > 0) {
- CHECK_EQ(layer_param.propagate_down_size(),
- layer_param.bottom_size())
- << "propagate_down param must be specified "
- << "either 0 or bottom_size times ";
- }
- layers_.push_back(LayerRegistry<Dtype>::CreateLayer(layer_param));
- layer_names_.push_back(layer_param.name());
- LOG(INFO) << "Creating Layer " << layer_param.name();
- bool need_backward = false;
- // Figure out this layer's input and output
- #ifdef USE_MPI
- vector<bool> source_layer_need_sync;
- for (int bottom_id = 0; bottom_id < layer_param.bottom_size();
- ++bottom_id) {
- const int blob_id = AppendBottom(param, layer_id, bottom_id,
- &available_blobs, &blob_name_to_idx);
- int src_layer_id = top_layer_indices_[blob_id].first;
- if (src_layer_id>=0) source_layer_need_sync.push_back(layers_[src_layer_id]->need_sync());
- if (source_layer_need_sync.size()>0){
- CHECK_EQ(source_layer_need_sync.back(), source_layer_need_sync[0])
- <<" blob "<<layer_param.bottom(0)
- <<" and blob "<< layer_param.bottom(bottom_id)
- <<" are from layers with different paralle mode. This is not supported.";
- }
- // If a blob needs backward, this layer should provide it.
- /*blob_need_backward_,整个网络中,所有非参数blob,是否需要backward。注意,这里所说的所有非参数blob其实指的是AppendTop函数中遍历的所有top blob,并不是每一层的top+bottom,因为这一层的top就是下一层的bottom,网络是一层一层堆起来的。
- */
- need_backward |= blob_need_backward_[blob_id];
- }
- if (layers_[layer_id]->is_gathering()){
- layers_[layer_id]->set_need_sync(false);
- } else {
- if(layers_[layer_id]->is_scattering()){
- layers_[layer_id]->set_need_sync(true);
- } else {
- if ((source_layer_need_sync.size() > 0)) {
- layers_[layer_id]->set_need_sync(source_layer_need_sync[0]);
- LOG(INFO) << "This layer is inheriting previous layer's sync mode: " << source_layer_need_sync[0];
- }
- }
- }
- #else
- for (int bottom_id = 0; bottom_id < layer_param.bottom_size();
- ++bottom_id) {
- const int blob_id = AppendBottom(param, layer_id, bottom_id,
- &available_blobs, &blob_name_to_idx);
- // If a blob needs backward, this layer should provide it.
- need_backward |= blob_need_backward_[blob_id];
- }
- #endif
- int num_top = layer_param.top_size();
- for (int top_id = 0; top_id < num_top; ++top_id) {
- AppendTop(param, layer_id, top_id, &available_blobs, &blob_name_to_idx);
- }
- // If the layer specifies that AutoTopBlobs() -> true and the LayerParameter
- // specified fewer than the required number (as specified by
- // ExactNumTopBlobs() or MinTopBlobs()), allocate them here.
- Layer<Dtype>* layer = layers_[layer_id].get();
- if (layer->AutoTopBlobs()) {
- const int needed_num_top =
- std::max(layer->MinTopBlobs(), layer->ExactNumTopBlobs());
- for (; num_top < needed_num_top; ++num_top) {
- // Add "anonymous" top blobs -- do not modify available_blobs or
- // blob_name_to_idx as we don't want these blobs to be usable as input
- // to other layers.
- AppendTop(param, layer_id, num_top, NULL, NULL);
- }
- }
- // After this layer is connected, set it up.
- LOG(INFO) << "Setting up " << layer_names_[layer_id];
- //每次循环,都会更新向量blob_loss_weights
- layers_[layer_id]->SetUp(bottom_vecs_[layer_id], top_vecs_[layer_id]);
- for (int top_id = 0; top_id < top_vecs_[layer_id].size(); ++top_id) {
- //blob_loss_weights_,每次遍历一个layer的时候,都会resize blob_loss_weights_, 然后调用模板类layer的loss函数返回loss_weight
- if (blob_loss_weights_.size() <= top_id_vecs_[layer_id][top_id]) {
- blob_loss_weights_.resize(top_id_vecs_[layer_id][top_id] + 1, Dtype(0));
- }
- //top_id_vecs_中存储的最基本元素是blob_id ——> 每一个新的blob都会赋予其一个blob_id,但是这个blob_id可能是会有重复的
- blob_loss_weights_[top_id_vecs_[layer_id][top_id]] = layer->loss(top_id);
- //loss函数返回loss_weight ——> 在模板类的SetUp方法中会调用SetLossWeights来设置其私有数据成员loss_,里面存储的其实是loss_weight
- LOG(INFO) << "Top shape: " << top_vecs_[layer_id][top_id]->shape_string();
- if (layer->loss(top_id)) {
- LOG(INFO) << " with loss weight " << layer->loss(top_id);
- }
- memory_used_ += top_vecs_[layer_id][top_id]->count();
- }
- DLOG(INFO) << "Memory required for data: " << memory_used_ * sizeof(Dtype);
- const int param_size = layer_param.param_size();
- const int num_param_blobs = layers_[layer_id]->blobs().size();
- //param_size是Layermeter类型对象layer_param中ParamSpec param成员的个数, num_param_blobs是一
- //个Layer中learnable parameter blob的个数,param_size <= num_param_blobs
- CHECK_LE(param_size, num_param_blobs)
- << "Too many params specified for layer " << layer_param.name();
- ParamSpec default_param_spec;
- for (int param_id = 0; param_id < num_param_blobs; ++param_id) {
- const ParamSpec* param_spec = (param_id < param_size) ?
- &layer_param.param(param_id) : &default_param_spec;
- const bool param_need_backward = param_spec->lr_mult() > 0;//need backward 则为真。
- need_backward |= param_need_backward;
- //由param_need_backward来决定need_backward是否为真,并且,只要有一次遍历使得need_backward为真,则这个for循环结束后,need_backward也为真
- layers_[layer_id]->set_param_propagate_down(param_id,
- param_need_backward);
- //设定一个Layer的parameter blob 是否需要计算diff backward--->set_param_propagate_down是模板类Layer的方法。
- }
- for (int param_id = 0; param_id < num_param_blobs; ++param_id) {
- //添加parameter blob,如果当前layer没有parameter blob(num_param_blobs==0),比如RELU,那么就不进入循环,不添加parameter blob
- //AppendParam只是执行为当前layer添加parameter blob的相关工作,并不会修改与backward的相关属性
- AppendParam(param, layer_id, param_id);
- }
- // Finally, set the backward flag
- layer_need_backward_.push_back(need_backward);
- //在上述的AppendTop函数中,在遍历当前层的每一个top blob的时候都会将一个false(默认值)压入向量blob_need_backward_。在下面的代码中,如果这个layer need backward,则会更新blob_need_backward_
- if (need_backward) {
- for (int top_id = 0; top_id < top_id_vecs_[layer_id].size(); ++top_id) {
- blob_need_backward_[top_id_vecs_[layer_id][top_id]] = true;
- //special treatment for "Gather" layer
- //This layer should be transparent to bp inferring.
- if (strcmp(layers_[layer_id]->type(), "Gather")==0){
- blob_need_backward_[top_id_vecs_[layer_id][top_id]]
- = blob_need_backward_[bottom_id_vecs_[layer_id][top_id]];
- }
- }
- }
- }
- // Go through the net backwards to determine which blobs contribute to the
- // loss. We can skip backward computation for blobs that don't contribute
- // to the loss.
- // Also checks if all bottom blobs don't need backward computation (possible
- // because the skip_propagate_down param) and so we can skip backward
- // computation for the entire layer
- // 需要注意的是,上述代码中关于backward设置的部分,是按照前向的顺序设置的,而下面的代码是按后向顺序修正前向设置的结果。
- // 一个layer是否需要backward computation,主要依据两个方面:(1)该layer的top blob 是否参与loss的计算;(2):该layer的bottom blob 是否需要backward computation,比如Data层一般就不需要backward computation
- set<string> blobs_under_loss;
- set<string> blobs_skip_backp;
- for (int layer_id = layers_.size() - 1; layer_id >= 0; --layer_id) {
- bool layer_contributes_loss = false;
- bool layer_skip_propagate_down = true;
- //为true,则表示当前layer的bottom blob不需要backward computation,即该层不需要backward computation。
- //这个局部变量所表示的意义与caffe.proto里message Layerparameter的propagate_down的定义恰好相反。
- for (int top_id = 0; top_id < top_vecs_[layer_id].size(); ++top_id) {
- //blob_names_整个网络中,所有非参数blob的name
- const string& blob_name = blob_names_[top_id_vecs_[layer_id][top_id]];
- if (layers_[layer_id]->loss(top_id) ||
- (blobs_under_loss.find(blob_name) != blobs_under_loss.end())) {
- layer_contributes_loss = true;
- }
- if (blobs_skip_backp.find(blob_name) == blobs_skip_backp.end()) {
- layer_skip_propagate_down = false;
- }
- if (layer_contributes_loss && !layer_skip_propagate_down)
- break;//只是跳出当前if语句
- }
- // If this layer can skip backward computation, also all his bottom blobs
- // don't need backpropagation
- if (layer_need_backward_[layer_id] && layer_skip_propagate_down) {
- layer_need_backward_[layer_id] = false;
- for (int bottom_id = 0; bottom_id < bottom_vecs_[layer_id].size();
- ++bottom_id) {
- //bottom_need_backward_,整个网络所有网络层的bottom blob是否需要backward
- bottom_need_backward_[layer_id][bottom_id] = false;
- }
- }
- if (!layer_contributes_loss) { layer_need_backward_[layer_id] = false; }
- if (layer_need_backward_[layer_id]) {
- LOG(INFO) << layer_names_[layer_id] << " needs backward computation.";
- } else {
- LOG(INFO) << layer_names_[layer_id]
- << " does not need backward computation.";
- }
- for (int bottom_id = 0; bottom_id < bottom_vecs_[layer_id].size();//修正前向设置的结果
- ++bottom_id) {
- if (layer_contributes_loss) {
- const string& blob_name =
- blob_names_[bottom_id_vecs_[layer_id][bottom_id]];
- blobs_under_loss.insert(blob_name);//为blobs_under_loss添加新元素
- } else {
- bottom_need_backward_[layer_id][bottom_id] = false;
- }
- if (!bottom_need_backward_[layer_id][bottom_id]) {
- const string& blob_name =
- blob_names_[bottom_id_vecs_[layer_id][bottom_id]];
- blobs_skip_backp.insert(blob_name);//为blobs_skip_backp添加新元素
- }
- }
- }
- //Handle force_backward if needed.Netparameter类型的force_backward方法
- if (param.force_backward()) {
- for (int layer_id = 0; layer_id < layers_.size(); ++layer_id) {
- layer_need_backward_[layer_id] = true;
- for (int bottom_id = 0;
- bottom_id < bottom_need_backward_[layer_id].size(); ++bottom_id) {
- bottom_need_backward_[layer_id][bottom_id] =
- bottom_need_backward_[layer_id][bottom_id] ||
- layers_[layer_id]->AllowForceBackward(bottom_id);
- blob_need_backward_[bottom_id_vecs_[layer_id][bottom_id]] =
- blob_need_backward_[bottom_id_vecs_[layer_id][bottom_id]] ||
- bottom_need_backward_[layer_id][bottom_id];
- }
- for (int param_id = 0; param_id < layers_[layer_id]->blobs().size();
- ++param_id) {
- layers_[layer_id]->set_param_propagate_down(param_id, true);
- }
- }
- }
- // In the end, all remaining blobs are considered output blobs.
- for (set<string>::iterator it = available_blobs.begin();
- it != available_blobs.end(); ++it) {
- LOG(INFO) << "This network produces output " << *it;
- net_output_blobs_.push_back(blobs_[blob_name_to_idx[*it]].get());
- net_output_blob_indices_.push_back(blob_name_to_idx[*it]);
- }
- for (size_t blob_id = 0; blob_id < blob_names_.size(); ++blob_id) {
- blob_names_index_[blob_names_[blob_id]] = blob_id;
- //第一次使用向量blob_names_index_,逐一添加元素,是一个map
- }
- for (size_t layer_id = 0; layer_id < layer_names_.size(); ++layer_id) {
- layer_names_index_[layer_names_[layer_id]] = layer_id;
- //第一次使用向量layer_names_index_,逐一添加元素,是一个map
- }
- GetLearningRateAndWeightDecay();
- debug_info_ = param.debug_info();
- LOG(INFO) << "Network initialization done.";
- LOG(INFO) << "Memory required for data: " << memory_used_ * sizeof(Dtype);
- }
- //FilterNet()给定当前phase/level/stage,移除指定层
- template <typename Dtype>
- void Net<Dtype>::FilterNet(const NetParameter& param,
- NetParameter* param_filtered) {
- NetState net_state(param.state());
- param_filtered->CopyFrom(param);
- param_filtered->clear_layer();
- for (int i = 0; i < param.layer_size(); ++i) {
- const LayerParameter& layer_param = param.layer(i);
- const string& layer_name = layer_param.name();
- CHECK(layer_param.include_size() == 0 || layer_param.exclude_size() == 0)
- << "Specify either include rules or exclude rules; not both.";
- // If no include rules are specified, the layer is included by default and
- // only excluded if it meets one of the exclude rules.
- bool layer_included = (layer_param.include_size() == 0);
- for (int j = 0; layer_included && j < layer_param.exclude_size(); ++j) {
- if (StateMeetsRule(net_state, layer_param.exclude(j), layer_name)) {
- layer_included = false;//如果不包含include,只要meet一个include_size(idx)即可
- }
- }
- for (int j = 0; !layer_included && j < layer_param.include_size(); ++j) {
- if (StateMeetsRule(net_state, layer_param.include(j), layer_name)) {
- layer_included = true;//如果包含include,只要符合一个include_size(idx)即可
- }
- }
- if (layer_included) {
- param_filtered->add_layer()->CopyFrom(layer_param);
- }
- }
- }
- //StateMeetsRule()中net的state是否满足NetStaterule
- template <typename Dtype>
- bool Net<Dtype>::StateMeetsRule(const NetState& state,
- const NetStateRule& rule, const string& layer_name) {
- // Check whether the rule is broken due to phase.
- if (rule.has_phase()) {
- if (rule.phase() != state.phase()) {
- LOG(INFO) << "The NetState phase (" << state.phase()
- << ") differed from the phase (" << rule.phase()
- << ") specified by a rule in layer " << layer_name;
- return false;
- }
- }
- // Check whether the rule is broken due to min level.
- if (rule.has_min_level()) {
- if (state.level() < rule.min_level()) {
- LOG(INFO) << "The NetState level (" << state.level()
- << ") is above the min_level (" << rule.min_level()
- << ") specified by a rule in layer " << layer_name;
- return false;
- }
- }
- // Check whether the rule is broken due to max level.
- if (rule.has_max_level()) {
- if (state.level() > rule.max_level()) {
- LOG(INFO) << "The NetState level (" << state.level()
- << ") is above the max_level (" << rule.max_level()
- << ") specified by a rule in layer " << layer_name;
- return false;
- }
- }
- // Check whether the rule is broken due to stage. The NetState must
- // contain ALL of the rule's stages to meet it.
- for (int i = 0; i < rule.stage_size(); ++i) {
- // Check that the NetState contains the rule's ith stage.
- bool has_stage = false;
- for (int j = 0; !has_stage && j < state.stage_size(); ++j) {
- if (rule.stage(i) == state.stage(j)) { has_stage = true; }
- }
- if (!has_stage) {
- LOG(INFO) << "The NetState did not contain stage '" << rule.stage(i)
- << "' specified by a rule in layer " << layer_name;
- return false;
- }
- }
- // Check whether the rule is broken due to not_stage. The NetState must
- // contain NONE of the rule's not_stages to meet it.
- for (int i = 0; i < rule.not_stage_size(); ++i) {
- // Check that the NetState contains the rule's ith not_stage.
- bool has_stage = false;
- for (int j = 0; !has_stage && j < state.stage_size(); ++j) {
- if (rule.not_stage(i) == state.stage(j)) { has_stage = true; }
- }
- if (has_stage) {
- LOG(INFO) << "The NetState contained a not_stage '" << rule.not_stage(i)
- << "' specified by a rule in layer " << layer_name;
- return false;
- }
- }
- return true;
- }
- // Helper for Net::Init: add a new input or top blob to the net. (Inputs have
- // layer_id == -1, tops have layer_id >= 0.)
- template <typename Dtype>
- void Net<Dtype>::AppendTop(const NetParameter& param, const int layer_id,
- const int top_id, set<string>* available_blobs,
- map<string, int>* blob_name_to_idx) {
- shared_ptr<LayerParameter> layer_param((layer_id >= 0) ?
- (new LayerParameter(param.layer(layer_id))) : NULL);
- const string& blob_name = layer_param ?
- (layer_param->top_size() > top_id ?
- layer_param->top(top_id) : "(automatic)") : param.input(top_id);
- // Check if we are doing in-place computation
- if (blob_name_to_idx && layer_param && layer_param->bottom_size() > top_id &&
- blob_name == layer_param->bottom(top_id)) {
- // In-place computation
- LOG(INFO) << layer_param->name() << " -> " << blob_name << " (in-place)";
- top_vecs_[layer_id].push_back(blobs_[(*blob_name_to_idx)[blob_name]].get());
- top_id_vecs_[layer_id].push_back((*blob_name_to_idx)[blob_name]);
- } else if (blob_name_to_idx &&
- blob_name_to_idx->find(blob_name) != blob_name_to_idx->end()) {
- // If we are not doing in-place computation but have duplicated blobs,
- // raise an error.
- LOG(FATAL) << "Duplicate blobs produced by multiple sources.";
- } else {
- // Normal output.
- if (layer_param) {
- LOG(INFO) << layer_param->name() << " -> " << blob_name;
- } else {
- LOG(INFO) << "Input " << top_id << " -> " << blob_name;
- }
- shared_ptr<Blob<Dtype> > blob_pointer(new Blob<Dtype>());
- //blobs只是存储中间结果;每次遍历到一个top blob都会更新blob_id
- const int blob_id = blobs_.size();
- blobs_.push_back(blob_pointer);
- blob_names_.push_back(blob_name);
- blob_need_backward_.push_back(false);
- top_layer_indices_.push_back(make_pair(layer_id, blob_id));
- /*
- blob_name_to_idx是一个局部变量,其实它是在当前layer的top blob 和下一层的bottom blob间起着一个桥梁作用。
- blob_name_to_idx中元素的pair是从网络最开始一层一层搭建的过程中压入map的,其中的name和id都是不重复的。name是关键字——不重复是map数据结构的必然要求,id也是不重复的——0,1,2...
- blob_name_to_idx和blobs_一样,在"Normal output"的情形下,每次遍历到一个top blob的时候都会更新
- */
- //添加新元素-->map可以通过下标访问符为(关联)容器添加新元素
- if (blob_name_to_idx) { (*blob_name_to_idx)[blob_name] = blob_id; }
- if (layer_id == -1) {
- // Set the (explicitly specified) dimensions of the input blob.
- if (param.input_dim_size() > 0) {
- blob_pointer->Reshape(param.input_dim(top_id * 4),
- param.input_dim(top_id * 4 + 1),
- param.input_dim(top_id * 4 + 2),
- param.input_dim(top_id * 4 + 3));
- } else {
- blob_pointer->Reshape(param.input_shape(top_id));
- }
- net_input_blob_indices_.push_back(blob_id);
- //当layer_id==-1时,即当前层为输入层的时候,会向net_input_blob_indices_里添加新元素,即add new input blob
- net_input_blobs_.push_back(blob_pointer.get());
- } else {
- top_id_vecs_[layer_id].push_back(blob_id);
- //当layer_id !=-1时,即当前层不是输入层的时候,会向net_input_blob_indices_里添加新元素,即add new top blob
- top_vecs_[layer_id].push_back(blob_pointer.get());
- }
- }
- if (available_blobs) { available_blobs->insert(blob_name); }
- }
- // Helper for Net::Init: add a new bottom blob to the net.
- template <typename Dtype>
- int Net<Dtype>::AppendBottom(const NetParameter& param, const int layer_id,
- const int bottom_id, set<string>* available_blobs,
- map<string, int>* blob_name_to_idx) {
- const LayerParameter& layer_param = param.layer(layer_id);
- const string& blob_name = layer_param.bottom(bottom_id);
- if (available_blobs->find(blob_name) == available_blobs->end()) {
- LOG(FATAL) << "Unknown blob input " << blob_name
- << " (at index " << bottom_id << ") to layer " << layer_id;
- }
- //blob_name_to_idx是一个map,其关键字是不重复的。blob_name_to_idx在输入层初始化
- //过了-->*blob_name_to_idx)[blob_name] = blob_id
- const int blob_id = (*blob_name_to_idx)[blob_name];
- LOG(INFO) << layer_names_[layer_id] << " <- " << blob_name;
- //存储整个网络所有网络层的bottom blob指针,实际上存储的是前一层的top,因为网络是一层一层堆起来的
- bottom_vecs_[layer_id].push_back(blobs_[blob_id].get());//调用shared_ptr类的get()方法提取存储在blobs_中的中间变量
- bottom_id_vecs_[layer_id].push_back(blob_id);
- available_blobs->erase(blob_name);
- bool propagate_down = true;
- // Check if the backpropagation on bottom_id should be skipped
- if (layer_param.propagate_down_size() > 0)
- propagate_down = layer_param.propagate_down(bottom_id);
- const bool need_backward = blob_need_backward_[blob_id] &&
- propagate_down;//propagate_down为true,则表示参与BP;否则,skip bp
- bottom_need_backward_[layer_id].push_back(need_backward);
- return blob_id;
- }
- template <typename Dtype>
- void Net<Dtype>::AppendParam(const NetParameter& param, const int layer_id,
- const int param_id) {
- //模板类Layer的layer_param方法,返回Layerparameter类型成员
- const LayerParameter& layer_param = layers_[layer_id]->layer_param();
- const int param_size = layer_param.param_size();
- string param_name =
- (param_size > param_id) ? layer_param.param(param_id).name() : "";
- if (param_name.size()) {
- //vector<string> param_display_names_ 这里param_name获取的是PaParamSpec类型中的name成员,如果有name且非空,就把name压入该向量,否则就压入param_id
- param_display_names_.push_back(param_name);
- } else {
- ostringstream param_display_name;
- param_display_name << param_id;
- param_display_names_.push_back(param_display_name.str());
- }
- //params_,整个网络的参数blob。 不管这个参数有没有non-emty name,是否参与share!!!
- const int net_param_id = params_.size(); //Append 参数blob 每一次循环,net_param_id和param_id_vecs_都会更新
- params_.push_back(layers_[layer_id]->blobs()[param_id]);
- //param_id_vecs_,存储的基本元素是net_param_id,每遍历一个参数blob,net_param_id和param_id_vecs_都会更新
- param_id_vecs_[layer_id].push_back(net_param_id);
- //param_layer_indices_其元素为当layer_id 与当前param_id 组成的pair.vector<pair<int, int> > param_layer_indices_
- param_layer_indices_.push_back(make_pair(layer_id, param_id));
- if (!param_size || !param_name.size() || (param_name.size() &&
- param_names_index_.find(param_name) == param_names_index_.end())) {
- // This layer "owns" this parameter blob -- it is either anonymous
- // (i.e., not given a param_name) or explicitly given a name that we
- // haven't already seen.
- /*param_owners_ 是一个存储parameter "onwer"的一个向量 ——> -1 表示当前Layer就是该parameter的"owner" ,
- 如果param_name不为空,而且能够在param_names_index_中找到,说明这个parameter已经存在于之前的某个或者某
- 些网络层里,说明这个parameter是共享于多个layer。 在caffe.proto的message ParamSpec里关于name的
- 注释——>To share a parameter between two layers, give it a (non-empty) name, 可见,如果一个parameter是
- 共享与多个网络层,那么它会有一个非空的name。
- */
- param_owners_.push_back(-1);
- //添加param_name
- if (param_name.size()) {
- /*
- map<string, int> param_names_index_是整个网络的参数non-empty name与index的映射。 注意,这个name是ParamSpec 类
- 型中的name,而且,""To share a parameter between two layers, give it a (non-empty) name"",所以说这个map中存
- 储的pair是<会被share的parameter_name, 其对应index>
- */
- param_names_index_[param_name] = net_param_id;
- /*
- map<string, int> param_names_index_ 。虽然每一次循环,net_param_id都会更新,但
- 是net_param_id只有当param_name.size()>0时才会被压入向量param_names_index_
- */
- }
- } else {
- // Named param blob with name we've seen before: share params
- //因为"To share a parameter between two layers, give it a (non-empty) name",所以这句代码就是获取shared parameter的"owner" net_param_id
- const int owner_net_param_id = param_names_index_[param_name];
- param_owners_.push_back(owner_net_param_id);
- /只获取了那些shared的parameter,即具有non-empty name的parameter的pair<layer_id, param_id>
- const pair<int, int>& owner_index =
- param_layer_indices_[owner_net_param_id];
- const int owner_layer_id = owner_index.first;
- const int owner_param_id = owner_index.second;
- LOG(INFO) << "Sharing parameters '" << param_name << "' owned by "
- << "layer '" << layer_names_[owner_layer_id] << "', param "
- << "index " << owner_param_id;
- //获取当前层的当前参数Blob
- Blob<Dtype>* this_blob = layers_[layer_id]->blobs()[param_id].get();
- //获取owner layer的对应的参数blob
- Blob<Dtype>* owner_blob =
- layers_[owner_layer_id]->blobs()[owner_param_id].get();
- const int param_size = layer_param.param_size();
- if (param_size > param_id && (layer_param.param(param_id).share_mode() ==
- ParamSpec_DimCheckMode_PERMISSIVE)) {
- // Permissive dimension checking -- only check counts are the same.
- CHECK_EQ(this_blob->count(), owner_blob->count())
- << "Shared parameter blobs must have the same count.";
- } else {
- // Strict dimension checking -- all dims must be the same.
- CHECK(this_blob->shape() == owner_blob->shape());
- }
- layers_[layer_id]->blobs()[param_id]->ShareData(
- *layers_[owner_layer_id]->blobs()[owner_param_id]);
- }
- }
- /*
- 功能:收集学习速率和权重衰减,即更新params_、params_lr_和params_weight_decay_
- 输入:无
- 输出:无
- 步骤:对每一层
- 1. 把当前层的所有blob存入params_中
- params_// The parameters in the network
- 2. 如果有lr, 则把当前层的所有blob的lr存入params_lr_中; 否则, lr默认为1
- 3. 如果有 weight_decay,则把当前层的所有 blob 的 weight_decay存入 params_weight_decay_ 中
- 4. 否则,weight_decay 默认为1
- */
- template <typename Dtype>
- void Net<Dtype>::GetLearningRateAndWeightDecay() {
- LOG(INFO) << "Collecting Learning Rate and Weight Decay.";
- ParamSpec default_param_spec;
- for (int i = 0; i < layers_.size(); ++i) {
- vector<shared_ptr<Blob<Dtype> > >& layer_blobs = layers_[i]->blobs();
- for (int j = 0; j < layer_blobs.size(); ++j) {
- const ParamSpec* param_spec =
- (layers_[i]->layer_param().param_size() > j) ?
- &layers_[i]->layer_param().param(j) : &default_param_spec;
- params_lr_.push_back(param_spec->lr_mult());
- params_weight_decay_.push_back(param_spec->decay_mult());
- }
- }
- }
- template <typename Dtype>
- Dtype Net<Dtype>::ForwardFromTo(int start, int end) {
- CHECK_GE(start, 0);
- CHECK_LT(end, layers_.size());
- Dtype loss = 0;
- if (debug_info_) {
- for (int i = 0; i < net_input_blobs_.size(); ++i) {
- InputDebugInfo(i);
- }
- }
- for (int i = start; i <= end; ++i) {
- // LOG(ERROR) << "Forwarding " << layer_names_[i];
- Dtype layer_loss = layers_[i]->Forward(bottom_vecs_[i], top_vecs_[i]);
- loss += layer_loss;
- if (debug_info_) { ForwardDebugInfo(i); }
- }
- #ifdef USE_CUDNN
- if (Caffe::mode() == Caffe::GPU)
- CuDNNConvolutionLayer<Dtype>::RuntimeOptimize(1000);
- #endif
- return loss;
- }
- template <typename Dtype>
- Dtype Net<Dtype>::ForwardFrom(int start) {
- return ForwardFromTo(start, layers_.size() - 1);
- }
- template <typename Dtype>
- Dtype Net<Dtype>::ForwardTo(int end) {
- return ForwardFromTo(0, end);
- }
- /*
- 功能:前馈预先填满,即预先进行一次前馈
- 输入:Dtype* loss
- 输出:net_output_blobs_,前馈后的输出层blob:vector
- */
- template <typename Dtype>
- const vector<Blob<Dtype>*>& Net<Dtype>::ForwardPrefilled(Dtype* loss) {
- if (loss != NULL) {
- *loss = ForwardFromTo(0, layers_.size() - 1);
- } else {
- ForwardFromTo(0, layers_.size() - 1);
- }
- return net_output_blobs_;
- }
- /*
- 功能:把网络输入层的blob读到net_input_blobs_,然后进行前馈,计算出loss
- 输入:整个网络输入层的blob
- 输出:整个网络输出层的blob
- */
- template <typename Dtype>
- const vector<Blob<Dtype>*>& Net<Dtype>::Forward(
- const vector<Blob<Dtype>*> & bottom, Dtype* loss) {
- // Copy bottom to internal bottom
- for (int i = 0; i < bottom.size(); ++i) {
- net_input_blobs_[i]->CopyFrom(*bottom[i]);
- }
- return ForwardPrefilled(loss);
- }
- /*
- 功能:Forward的重载,只是输入层的blob以string的格式传入
- */
- template <typename Dtype>
- string Net<Dtype>::Forward(const string& input_blob_protos, Dtype* loss) {
- BlobProtoVector blob_proto_vec;
- if (net_input_blobs_.size()) {
- blob_proto_vec.ParseFromString(input_blob_protos);
- CHECK_EQ(blob_proto_vec.blobs_size(), net_input_blobs_.size())
- << "Incorrect input size.";
- for (int i = 0; i < blob_proto_vec.blobs_size(); ++i) {
- net_input_blobs_[i]->FromProto(blob_proto_vec.blobs(i));
- }
- }
- ForwardPrefilled(loss);
- blob_proto_vec.Clear();
- for (int i = 0; i < net_output_blobs_.size(); ++i) {
- net_output_blobs_[i]->ToProto(blob_proto_vec.add_blobs());
- }
- string output;
- blob_proto_vec.SerializeToString(&output);
- return output;
- }
- template <typename Dtype>
- void Net<Dtype>::BackwardFromTo(int start, int end) {
- CHECK_GE(end, 0);
- CHECK_LT(start, layers_.size());
- for (int i = start; i >= end; --i) {
- if (layer_need_backward_[i]) {
- layers_[i]->Backward(
- top_vecs_[i], bottom_need_backward_[i], bottom_vecs_[i]);
- if (debug_info_) { BackwardDebugInfo(i); }
- #ifdef USE_MPI
- if ((Caffe::parallel_mode() == Caffe::MPI) && (Caffe::remaining_sub_iter() == 0)) {
- for (int n = 0; n < param_layer_indices_.size(); ++n) {
- bool ready_for_sync = false;
- //decide whether we need to sync the gradient of this blob
- if ((param_layer_indices_[n].first == i)) {
- if (param_owners_[n] == -1) {
- ready_for_sync = true;
- } else {
- // this blob is a shared one, we need to make sure no more gradients will be
- // accumulated to it before transmission
- int owner_id = param_owners_[n];
- ready_for_sync = true;
- for (int m = n - 1; m >= 0; --m) {
- if ((param_owners_[m] == owner_id) && (param_layer_indices_[m].first >= end)) {
- // there are still layers holding this shared blob,
- // not secure the do the transmission
- ready_for_sync = false;
- break;
- }
- }
- }
- }
- //sync gradient
- if (ready_for_sync && layers_[i]->need_sync())
- caffe_iallreduce(
- this->params_[n]->mutable_cpu_diff(),
- this->params_[n]->count()
- );
- }
- }
- #endif //USE_MPI
- }
- }
- }
- template <typename Dtype>
- void Net<Dtype>::InputDebugInfo(const int input_id) {
- const Blob<Dtype>& blob = *net_input_blobs_[input_id];
- const string& blob_name = blob_names_[net_input_blob_indices_[input_id]];
- const Dtype data_abs_val_mean = blob.asum_data() / blob.count();
- LOG(INFO) << " [Forward] "
- << "Input " << blob_name << " data: " << data_abs_val_mean;
- }
- template <typename Dtype>
- void Net<Dtype>::ForwardDebugInfo(const int layer_id) {
- for (int top_id = 0; top_id < top_vecs_[layer_id].size(); ++top_id) {
- const Blob<Dtype>& blob = *top_vecs_[layer_id][top_id];
- const string& blob_name = blob_names_[top_id_vecs_[layer_id][top_id]];
- const Dtype data_abs_val_mean = blob.asum_data() / blob.count();
- LOG(INFO) << " [Forward] "
- << "Layer " << layer_names_[layer_id] << ", top blob " << blob_name
- << " data: " << data_abs_val_mean;
- }
- for (int param_id = 0; param_id < layers_[layer_id]->blobs().size();
- ++param_id) {
- const Blob<Dtype>& blob = *layers_[layer_id]->blobs()[param_id];
- const int net_param_id = param_id_vecs_[layer_id][param_id];
- const string& blob_name = param_display_names_[net_param_id];
- const Dtype data_abs_val_mean = blob.asum_data() / blob.count();
- LOG(INFO) << " [Forward] "
- << "Layer " << layer_names_[layer_id] << ", param blob " << blob_name
- << " data: " << data_abs_val_mean;
- }
- }
- template <typename Dtype>
- void Net<Dtype>::BackwardDebugInfo(const int layer_id) {
- const vector<Blob<Dtype>*>& bottom_vec = bottom_vecs_[layer_id];
- for (int bottom_id = 0; bottom_id < bottom_vec.size(); ++bottom_id) {
- if (!bottom_need_backward_[layer_id][bottom_id]) { continue; }
- const Blob<Dtype>& blob = *bottom_vec[bottom_id];
- const string& blob_name = blob_names_[bottom_id_vecs_[layer_id][bottom_id]];
- const Dtype diff_abs_val_mean = blob.asum_diff() / blob.count();
- LOG(INFO) << " [Backward] "
- << "Layer " << layer_names_[layer_id] << ", bottom blob " << blob_name
- << " diff: " << diff_abs_val_mean;
- }
- for (int param_id = 0; param_id < layers_[layer_id]->blobs().size();
- ++param_id) {
- if (!layers_[layer_id]->param_propagate_down(param_id)) { continue; }
- const Blob<Dtype>& blob = *layers_[layer_id]->blobs()[param_id];
- const Dtype diff_abs_val_mean = blob.asum_diff() / blob.count();
- LOG(INFO) << " [Backward] "
- << "Layer " << layer_names_[layer_id] << ", param blob " << param_id
- << " diff: " << diff_abs_val_mean;
- }
- }
- template <typename Dtype>
- void Net<Dtype>::UpdateDebugInfo(const int param_id) {
- const Blob<Dtype>& blob = *params_[param_id];
- const int param_owner = param_owners_[param_id];
- const string& layer_name = layer_names_[param_layer_indices_[param_id].first];
- const string& param_display_name = param_display_names_[param_id];
- const Dtype diff_abs_val_mean = blob.asum_diff() / blob.count();
- if (param_owner < 0) {
- const Dtype data_abs_val_mean = blob.asum_data() / blob.count();
- LOG(INFO) << " [Update] Layer " << layer_name
- << ", param " << param_display_name
- << " data: " << data_abs_val_mean << "; diff: " << diff_abs_val_mean;
- } else {
- const string& owner_layer_name =
- layer_names_[param_layer_indices_[param_owner].first];
- LOG(INFO) << " [Update] Layer " << layer_name
- << ", param blob " << param_display_name
- << " (owned by layer " << owner_layer_name << ", "
- << "param " << param_display_names_[param_owners_[param_id]] << ")"
- << " diff: " << diff_abs_val_mean;
- }
- }
- /*
- 功能:从Other网络复制某些层
- 步骤:对Other网络的第i层(源层):
- 1. 定义一个Layer的指针指向第i层
- 2. 读取第i层(源层)的名字
- 3. 找通过名字来找目标层如果没找到,即target_layer_id == layer_names_.size()则忽略Other的第i层,即Other的第i层不需要share给网络
- 4. 如果找到了,即other的第i层需要share给网络,则把目标层的所有blob读到target_blobs中
- 1判断目标层和源层的blob数量是否相等
- 2判断每个blob大小是否相等
- 3调用ShareData函数把源层的blob赋给目标层的blob
- */
- template <typename Dtype>
- void Net<Dtype>::ShareTrainedLayersWith(const Net* other) {
- int num_source_layers = other->layers().size();
- for (int i = 0; i < num_source_layers; ++i) {
- Layer<Dtype>* source_layer = other->layers()[i].get();
- const string& source_layer_name = other->layer_names()[i];
- int target_layer_id = 0;
- while (target_layer_id != layer_names_.size() &&
- layer_names_[target_layer_id] != source_layer_name) {
- ++target_layer_id;
- }
- if (target_layer_id == layer_names_.size()) {
- DLOG(INFO) << "Ignoring source layer " << source_layer_name;
- continue;
- }
- DLOG(INFO) << "Copying source layer " << source_layer_name;
- vector<shared_ptr<Blob<Dtype> > >& target_blobs =
- layers_[target_layer_id]->blobs();
- CHECK_EQ(target_blobs.size(), source_layer->blobs().size())
- << "Incompatible number of blobs for layer " << source_layer_name;
- for (int j = 0; j < target_blobs.size(); ++j) {
- Blob<Dtype>* source_blob = source_layer->blobs()[j].get();
- CHECK(target_blobs[j]->shape() == source_blob->shape());
- target_blobs[j]->ShareData(*source_blob);
- }
- }
- }
- template <typename Dtype>
- void Net<Dtype>::BackwardFrom(int start) {
- BackwardFromTo(start, 0);
- }
- template <typename Dtype>
- void Net<Dtype>::BackwardTo(int end) {
- BackwardFromTo(layers_.size() - 1, end);
- }
- /*
- 功能:对整个网络进行反向传播
- */
- template <typename Dtype>
- void Net<Dtype>::Backward() {
- BackwardFromTo(layers_.size() - 1, 0);
- if (debug_info_) {
- Dtype asum_data = 0, asum_diff = 0, sumsq_data = 0, sumsq_diff = 0;
- for (int i = 0; i < params_.size(); ++i) {
- if (param_owners_[i] >= 0) { continue; }
- asum_data += params_[i]->asum_data();
- asum_diff += params_[i]->asum_diff();
- sumsq_data += params_[i]->sumsq_data();
- sumsq_diff += params_[i]->sumsq_diff();
- }
- const Dtype l2norm_data = std::sqrt(sumsq_data);
- const Dtype l2norm_diff = std::sqrt(sumsq_diff);
- LOG(ERROR) << " [Backward] All net params (data, diff): "
- << "L1 norm = (" << asum_data << ", " << asum_diff << "); "
- << "L2 norm = (" << l2norm_data << ", " << l2norm_diff << ")";
- }
- }
- template <typename Dtype>
- void Net<Dtype>::Reshape() {
- for (int i = 0; i < layers_.size(); ++i) {
- layers_[i]->Reshape(bottom_vecs_[i], top_vecs_[i]);
- }
- #ifdef USE_CUDNN
- if (Caffe::mode() == Caffe::GPU)
- CuDNNConvolutionLayer<Dtype>::RuntimeOptimize(1000);
- #endif
- }
- /*
- 功能:和ShareTrainedLayersWith一样
- 步骤:不同的是调用FromProto函数把源层的blob赋给目标层的blob
- */
- template <typename Dtype>
- void Net<Dtype>::CopyTrainedLayersFrom(const NetParameter& param) {
- int num_source_layers = param.layer_size();
- for (int i = 0; i < num_source_layers; ++i) {
- const LayerParameter& source_layer = param.layer(i);
- const string& source_layer_name = source_layer.name();
- int target_layer_id = 0;
- while (target_layer_id != layer_names_.size() &&
- layer_names_[target_layer_id] != source_layer_name) {
- ++target_layer_id;
- }
- if (target_layer_id == layer_names_.size()) {
- DLOG(INFO) << "Ignoring source layer " << source_layer_name;
- continue;
- }
- DLOG(INFO) << "Copying source layer " << source_layer_name;
- vector<shared_ptr<Blob<Dtype> > >& target_blobs =
- layers_[target_layer_id]->blobs();
- CHECK_EQ(target_blobs.size(), source_layer.blobs_size())
- << "Incompatible number of blobs for layer " << source_layer_name;
- for (int j = 0; j < target_blobs.size(); ++j) {
- const bool kReshape = false;
- target_blobs[j]->FromProto(source_layer.blobs(j), kReshape);
- }
- }
- }
- /*
- 功能:从文件中读入NetParameter param,然后调用CopyTrainedLayersFrom()
- */
- template <typename Dtype>
- void Net<Dtype>::CopyTrainedLayersFrom(const string trained_filename) {
- NetParameter param;
- ReadNetParamsFromBinaryFileOrDie(trained_filename, ¶m);
- CopyTrainedLayersFrom(param);
- }
- /*
- 功能:把网络的参数存入prototxt中
- 步骤:
- 1. 设置网络的名字:param->set_name(name_)
- 2. 加入输入层blob的名字
- 3. 对于第i层:
- 1加入bottom的blob的名字
- 2加入top的blob的名字
- 3写到proto中
- */
- template <typename Dtype>
- void Net<Dtype>::ToProto(NetParameter* param, bool write_diff) const {
- param->Clear();
- param->set_name(name_);
- // Add bottom and top
- for (int i = 0; i < net_input_blob_indices_.size(); ++i) {
- param->add_input(blob_names_[net_input_blob_indices_[i]]);
- }
- DLOG(INFO) << "Serializing " << layers_.size() << " layers";
- for (int i = 0; i < layers_.size(); ++i) {
- LayerParameter* layer_param = param->add_layer();
- //bottom_id_vecs_存储整个网络所有网络层的bottom blob的ID
- for (int j = 0; j < bottom_id_vecs_[i].size(); ++j) {
- layer_param->add_bottom(blob_names_[bottom_id_vecs_[i][j]]);
- }
- for (int j = 0; j < top_id_vecs_[i].size(); ++j) {
- layer_param->add_top(blob_names_[top_id_vecs_[i][j]]);
- }
- layers_[i]->ToProto(layer_param, write_diff);
- }
- }
- /*
- 功能:更新params_中blob的值
- */
- template <typename Dtype>
- void Net<Dtype>::Update() {
- // First, accumulate the diffs of any shared parameters into their owner's
- // diff. (Assumes that the learning rate, weight decay, etc. have already been
- // accounted for in the current diff.)
- for (int i = 0; i < params_.size(); ++i) {
- if (param_owners_[i] < 0) { continue; }
- if (debug_info_) { UpdateDebugInfo(i); }
- const int count = params_[i]->count();
- const Dtype* this_diff;
- Dtype* owner_diff;
- switch (Caffe::mode()) {
- case Caffe::CPU:
- this_diff = params_[i]->cpu_diff();
- owner_diff = params_[param_owners_[i]]->mutable_cpu_diff();
- caffe_add(count, this_diff, owner_diff, owner_diff);
- break;
- case Caffe::GPU:
- #ifndef CPU_ONLY
- this_diff = params_[i]->gpu_diff();
- owner_diff = params_[param_owners_[i]]->mutable_gpu_diff();
- caffe_gpu_add(count, this_diff, owner_diff, owner_diff);
- #else
- NO_GPU;
- #endif
- break;
- default:
- LOG(FATAL) << "Unknown caffe mode: " << Caffe::mode();
- }
- }
- // Now, update the owned parameters.
- for (int i = 0; i < params_.size(); ++i) {
- if (param_owners_[i] >= 0) { continue; }
- if (debug_info_) { UpdateDebugInfo(i); }
- params_[i]->Update();
- }
- }
- /*
- 功能:判断是否存在名字为blob_name的blob
- */
- template <typename Dtype>
- bool Net<Dtype>::has_blob(const string& blob_name) const {
- return blob_names_index_.find(blob_name) != blob_names_index_.end();
- }
- /*
- 功能:给一个blob的名字,返回这个blob的指针
- */
- template <typename Dtype>
- const shared_ptr<Blob<Dtype> > Net<Dtype>::blob_by_name(
- const string& blob_name) const {
- shared_ptr<Blob<Dtype> > blob_ptr;
- if (has_blob(blob_name)) {
- blob_ptr = blobs_[blob_names_index_.find(blob_name)->second];
- } else {
- blob_ptr.reset((Blob<Dtype>*)(NULL));
- LOG(WARNING) << "Unknown blob name " << blob_name;
- }
- return blob_ptr;
- }
- /*
- 功能:判断是否存在名字为layer_name的layer
- */
- template <typename Dtype>
- bool Net<Dtype>::has_layer(const string& layer_name) const {
- return layer_names_index_.find(layer_name) != layer_names_index_.end();
- }
- /*
- 功能:给一个layer的名字,返回这个layer的指针
- */
- template <typename Dtype>
- const shared_ptr<Layer<Dtype> > Net<Dtype>::layer_by_name(
- const string& layer_name) const {
- shared_ptr<Layer<Dtype> > layer_ptr;
- if (has_layer(layer_name)) {
- layer_ptr = layers_[layer_names_index_.find(layer_name)->second];
- } else {
- layer_ptr.reset((Layer<Dtype>*)(NULL));
- LOG(WARNING) << "Unknown layer name " << layer_name;
- }
- return layer_ptr;
- }
- INSTANTIATE_CLASS(Net);
- } // namespace caffe


 浙公网安备 33010602011771号
浙公网安备 33010602011771号