分布式系统知识点十三:缓存过期策略(转载)
本系列为网上收集转载分布式相关知识点系列文章,并非原创。如果侵权,请联系我删除!!!
对于redis 中设置的数据而言
过期策略通常有以下三种:
- 定时过期
每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除。
优点:该策略可以立即清除过期的数据,对内存很友好;
缺点:但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
- 惰性过期
只有当访问一个key时,才会判断该key是否已过期,过期则清除。
优点:该策略可以最大化地节省CPU资源,
缺点:对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
- 定期过期
每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key。
该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
来源:https://blog.csdn.net/cr_lzy/java/article/details/93983541
对于自己实现的内存缓存而言
FIFO:First In First Out,先进先出
LRU:Least Recently Used,最近最少使用
LFU:Least Frequently Used,最不经常使用
以上三者都是缓存过期策略。
原理和实现:
一、FIFO按照“先进先出(First In,First Out)”的原理淘汰数据,正好符合队列的特性,数据结构上使用队列Queue来实现。
如下图:


1. 新访问的数据插入FIFO队列尾部,数据在FIFO队列中顺序移动;
2. 淘汰FIFO队列头部的数据;
二、LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:
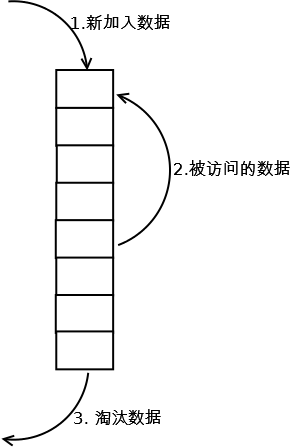

1. 新数据插入到链表头部;
2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3. 当链表满的时候,将链表尾部的数据丢弃。
三、LFU(Least Frequently Used)算法根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
LFU的每个数据块都有一个引用计数,所有数据块按照引用计数排序,具有相同引用计数的数据块则按照时间排序。
具体实现如下:
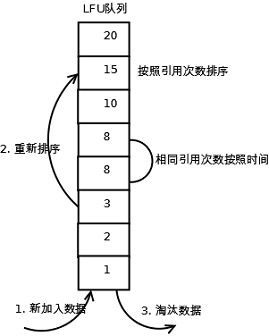
1. 新加入数据插入到队列尾部(因为引用计数为1);
2. 队列中的数据被访问后,引用计数增加,队列重新排序;
3. 当需要淘汰数据时,将已经排序的列表最后的数据块删除。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号