
2023ACMMM_Mutual Information-driven Triple Interaction Network for Efficient Image Dehazing
一. Motivation
之前网络存在的缺点:
1. 使用了有限的频域信息
2. 不充足的信息交互 :
(1) 第一阶段的输出直接作为第二阶段的输入,忽略了中间特征从早期到后期的传播
(2) 在编码器解码器结构同尺度之间进行特征融合,忽略了阶段内和跨阶段的跨尺度信息交换
3. 严重的特征冗余:中间阶段的输出缺少约束(感觉有点牵强)
二. Contribution
1. 设计了两个阶段:S1 幅值增强阶段,雾集中在幅值上,在幅值上进行雾的移除;S2 相位增强阶段:在相位进行结构细化
2. 设计了Adaptive Triple Interaction Module(ATIM):跨域(空域频域)、跨尺度(尺度不同)、跨阶段(S1和S2阶段),融合的特征进一步用于生成内容自适应动态过滤器,增强全局上下文表示
3. 对两个阶段的输出施加信息最小化约束。
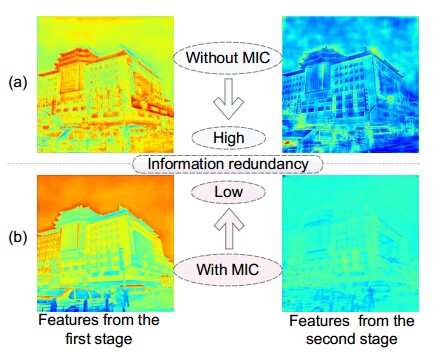
注: MIC(mutual information constraint),有无使用MIC的约束比较,(a)没有使用MIC,像素值高,像素冗余
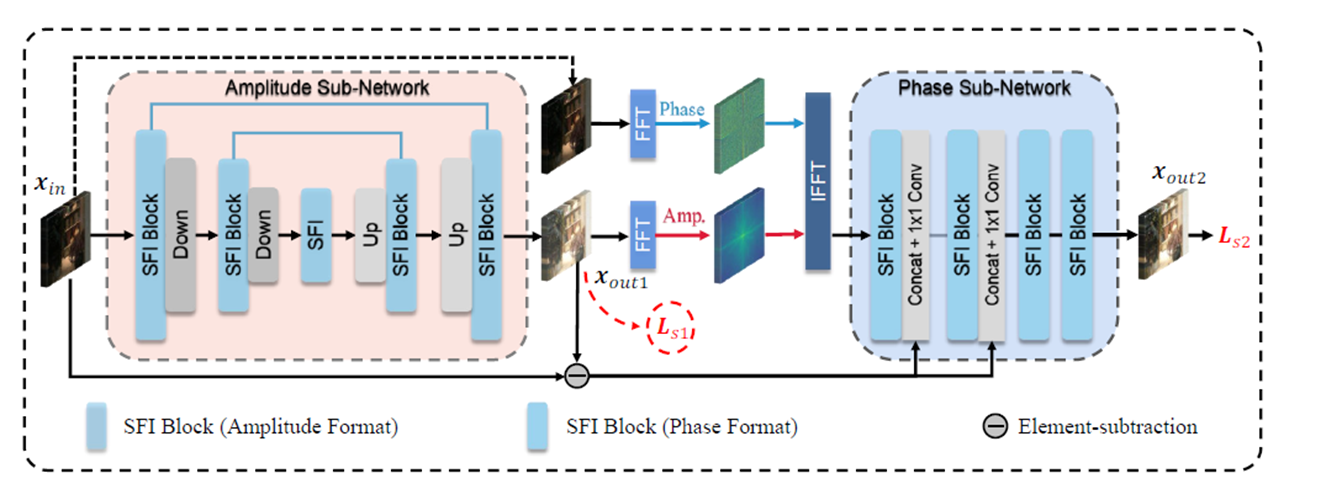
三. Network
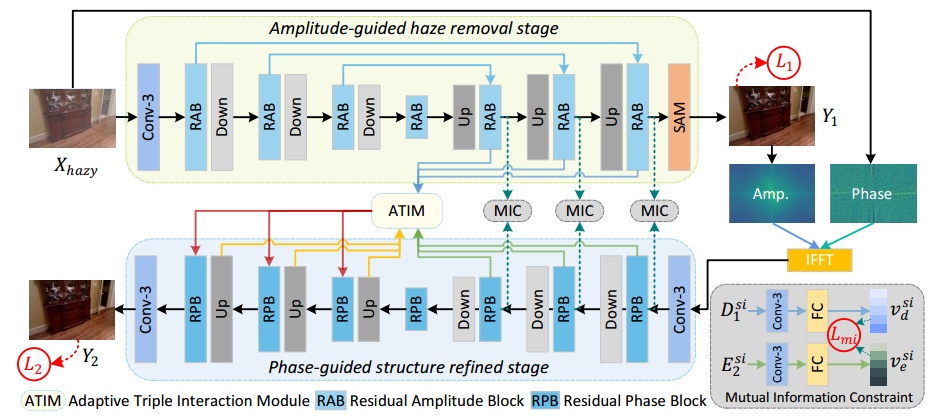
1. 网络分为两个阶段: S1:Amplitude-guided haze removal stage , S2:Phase-guided structure refined stage
2. S1阶段
输入:有雾图像![]() ,输出 Y1,
,输出 Y1,
损失: L1:
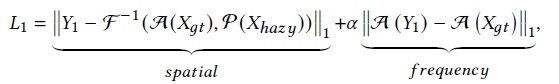
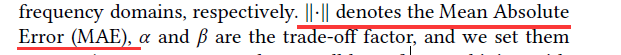
3. S2阶段:
输入: 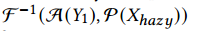 输出: Y2
输出: Y2
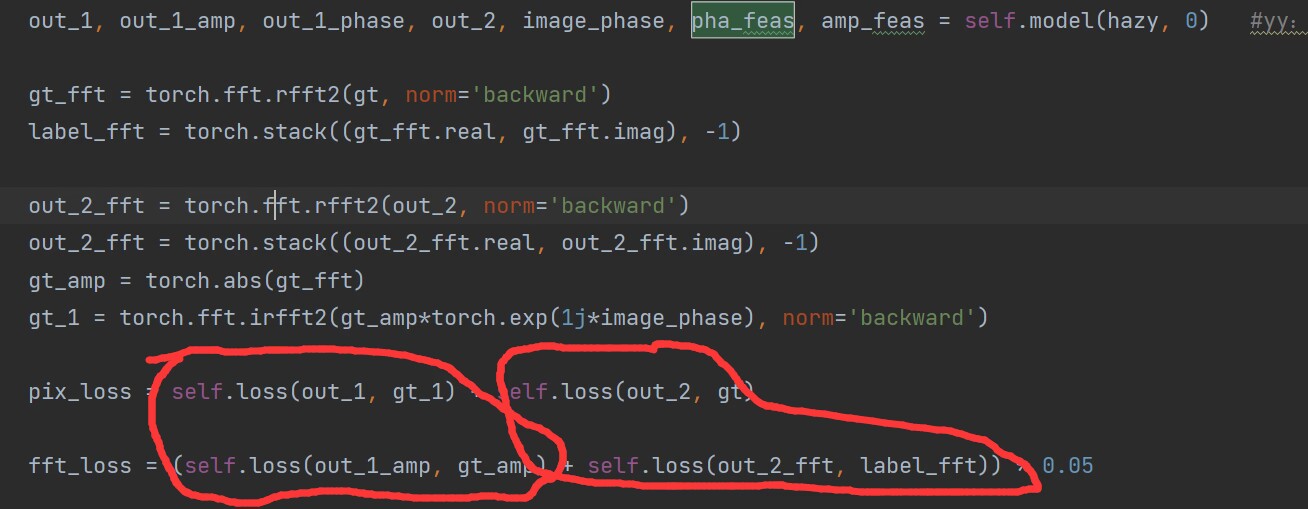
损失:L2:
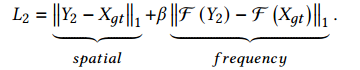
损失代码
四、网络中的各组件
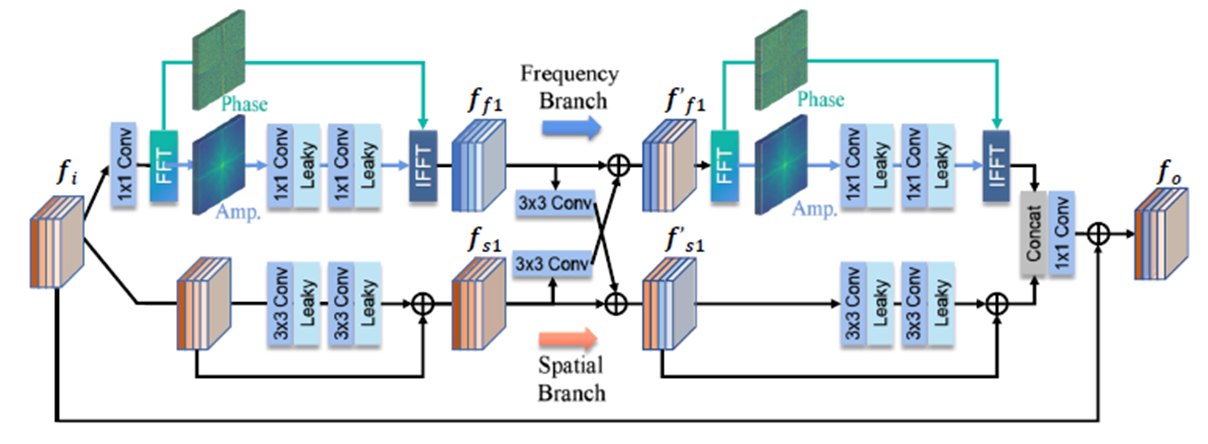
1. Residual Amplitude/Phase Block
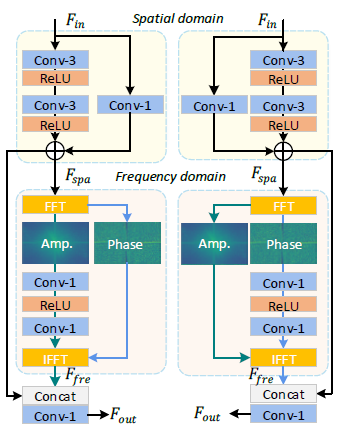


1 class FFTConvBlock(nn.Module): 2 def __init__(self, in_size, out_size, downsample, relu_slope, use_csff=False, use_FFT_PHASE=False, use_FFT_AMP=False): 3 super(FFTConvBlock, self).__init__() 4 self.downsample = downsample 5 self.identity = nn.Conv2d(in_size, out_size, 1, 1, 0) 6 self.use_csff = use_csff 7 self.use_FFT_PHASE = use_FFT_PHASE 8 self.use_FFT_AMP = use_FFT_AMP 9 10 self.resConv = nn.Sequential(*[ 11 nn.Conv2d(in_size, out_size, kernel_size=3, padding=1, bias=True), 12 nn.LeakyReLU(relu_slope, inplace=False), 13 nn.Conv2d(out_size, out_size, kernel_size=3, padding=1, bias=True), 14 nn.LeakyReLU(relu_slope, inplace=False) 15 ]) 16 17 self.identity = nn.Conv2d(in_size, out_size, 1, 1, 0) 18 self.fftConv2 = nn.Sequential(*[ 19 nn.Conv2d(out_size, out_size, 1, 1, 0), 20 nn.LeakyReLU(relu_slope, inplace=False), 21 nn.Conv2d(out_size, out_size, 1, 1, 0) 22 ]) 23 24 self.fusion = nn.Conv2d(out_size*2, out_size, 1, 1, 0) 25 26 if downsample and use_csff: 27 self.csff_enc = nn.Conv2d(out_size, out_size, 3, 1, 1) 28 self.csff_dec = nn.Conv2d(out_size, out_size, 3, 1, 1) 29 30 if downsample: 31 self.downsample = conv_down(out_size, out_size, bias=False) 32 33 def forward(self, x, enc=None, dec=None): 34 # yy: Spatial domain 35 res_out = self.resConv(x) 36 identity = self.identity(x) 37 out = res_out + identity 38 39 if self.use_FFT_PHASE and self.use_FFT_AMP == False: 40 # x_fft =torch.fft.fft2(x_res, dim=(-2, -1)) 41 x_fft = torch.fft.rfft2(out, norm='backward') 42 x_amp = torch.abs(x_fft) 43 x_phase = torch.angle(x_fft) 44 45 x_phase = self.fftConv2(x_phase) 46 x_fft_out = torch.fft.irfft2(x_amp*torch.exp(1j*x_phase), norm='backward') 47 out = self.fusion(torch.cat([out, x_fft_out], dim=1)) 48 elif self.use_FFT_AMP and self.use_FFT_PHASE == False: 49 x_fft = torch.fft.rfft2(out, norm='backward') 50 x_amp = torch.abs(x_fft) 51 x_phase = torch.angle(x_fft) 52 53 x_amp = self.fftConv2(x_amp) 54 x_fft_out = torch.fft.irfft2(x_amp*torch.exp(1j*x_phase), norm='backward') 55 out = self.fusion(torch.cat([out, x_fft_out], dim=1)) 56 else: 57 out = out + self.identity(x) 58 59 if enc is not None and dec is not None: 60 assert self.use_csff 61 out = out + self.csff_enc(enc) + self.csff_dec(dec) 62 if self.downsample: 63 out_down = self.downsample(out) 64 return out_down, out 65 else: 66 return out
(网络结构和FECNet Deep Fourier-based Exposure Correction Network with Spatial-Frequency InteractionECCV’22 有点相似)
SFI Block:
2. Adaptive Triple Interaction Module
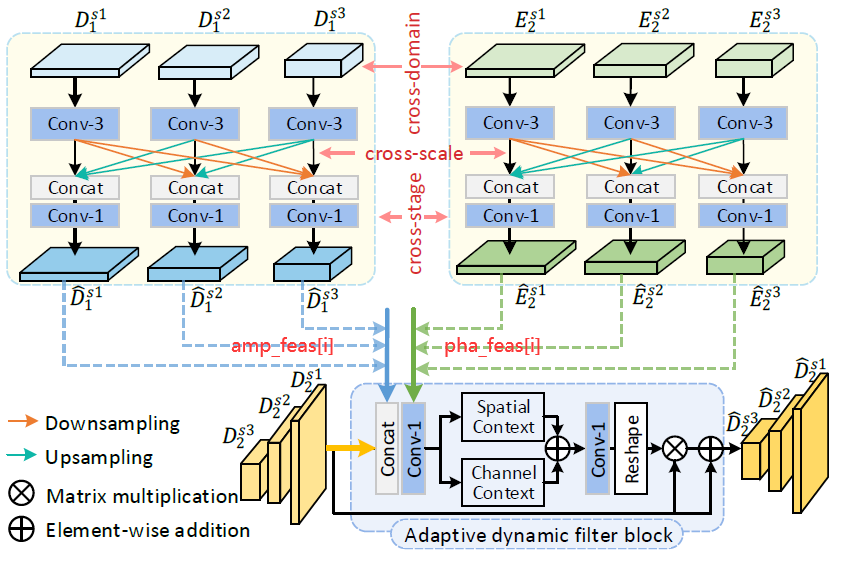
# Triple Interaction class FCI(nn.Module): def __init__(self, wf=24, depth=4): super(FCI, self).__init__() self.depth = depth self.wf = wf self.conv_amp = nn.ModuleList() self.conv_pha = nn.ModuleList() for i in range(depth - 1): self.conv_pha.append(nn.Conv2d((2**i)*wf, (2**i)*wf, 3, 1, 1)) self.conv_amp.append(nn.Conv2d((2**i)*wf, (2**i)*wf, 3, 1, 1)) # for phase self.resize_pha = nn.ModuleList() self.resize_amp = nn.ModuleList() self.fusion_pha = nn.ModuleList() self.fusion_amp = nn.ModuleList() for i in range(self.depth - 1): self.resize_pha.append(nn.ModuleList()) self.resize_amp.append(nn.ModuleList()) for i in range(self.depth - 1): self.resize_pha[i] = nn.ModuleList() self.resize_amp[i] = nn.ModuleList() for j in range(self.depth - 1): if i < j: self.resize_pha[i].append(DownSample(in_channels=(2**i)*wf, scale_factor=2**(j-i), chan_factor=2, kernel_size=3)) self.resize_amp[i].append(DownSample(in_channels=(2**i)*wf, scale_factor=2**(j-i), chan_factor=2, kernel_size=3)) elif i == j: self.resize_pha[i].append(None) self.resize_amp[i].append(None) else: self.resize_pha[i].append(UpSample(in_channels=(2**i)*wf, scale_factor=2**(i-j), chan_factor=2, kernel_size=3)) self.resize_amp[i].append(UpSample(in_channels=(2**i)*wf, scale_factor=2**(i-j), chan_factor=2, kernel_size=3)) self.fusion_pha.append(nn.Conv2d((2**i)*wf*(depth-1), (2**i)*wf, 1, 1, 0)) self.fusion_amp.append(nn.Conv2d((2**i)*wf*(depth-1), (2**i)*wf, 1, 1, 0)) def forward(self, phas, amps): pha_feas = [] amp_feas = [] for i in range(self.depth - 1): pha_feas.append(self.conv_pha[i](phas[i])) amp_feas.append(self.conv_amp[i](amps[i])) for i in range(self.depth - 1): for j in range(self.depth - 1): if i != j: x = torch.cat([pha_feas[i], self.resize_pha[j][i](pha_feas[j])], dim=1) pha_feas[i] = x y = torch.cat([amp_feas[i], self.resize_amp[j][i](amp_feas[j])], dim=1) amp_feas[i] = y pha_feas[i] = self.fusion_pha[i](pha_feas[i]) amp_feas[i] = self.fusion_amp[i](amp_feas[i]) return pha_feas, amp_feas
# Adaptive Dynamic Filter Block class AFG(nn.Module): def __init__(self, in_channels=24, kernel_size=3): super(AFG, self).__init__() self.kernel_size = kernel_size self.sekg = Context(in_channels, kernel_size) self.fusion = nn.Conv2d(in_channels*3, in_channels, 1, 1, 0) self.kernel = nn.Conv2d(in_channels, in_channels*kernel_size*kernel_size, 1, 1, 0) self.unfold = nn.Unfold(kernel_size=3, dilation=1, padding=1, stride=1) def forward(self, x, pha, amp): fusion = self.fusion(torch.cat([x, pha, amp], dim=1)) b, c, h, w = x.size() att = self.sekg(fusion) kers = self.kernel(att) filter_x = kers.reshape([b, c, self.kernel_size*self.kernel_size, h, w]) unfold_x = self.unfold(x).reshape(b, c, -1, h, w) out = (unfold_x * filter_x).sum(2) return out + x
class Context(nn.Module): def __init__(self, in_channels=24, kernel_size=3): super().__init__() self.conv_sa = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=1, padding=1, dilation=1, groups=in_channels) self.avg_pool = nn.AdaptiveAvgPool2d(1) self.conv_ca = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2) def forward(self, input_x): b, c, h, w = input_x.size() sa_x = self.conv_sa(input_x) y = self.avg_pool(input_x) ca_x = self.conv_ca(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1) out = sa_x + ca_x return out
3. Mutual Information Constraint
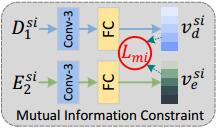
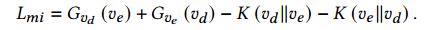
将两部分交叉熵合并再减去KL散度得到的损失
4. 总损失
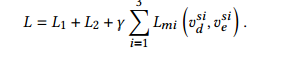
import torch import torch.nn as nn from torch.distributions import Normal, Independent, kl from torch.autograd import Variable CE = torch.nn.BCELoss(reduction='sum') class Mutual_info_reg(nn.Module): def __init__(self, input_channels, channels, latent_size = 4): super(Mutual_info_reg, self).__init__() self.contracting_path = nn.ModuleList() self.input_channels = input_channels self.relu = nn.ReLU(inplace=True) self.layer1 = nn.Conv2d(input_channels, channels, kernel_size=4, stride=2, padding=1) # self.bn1 = nn.BatchNorm2d(channels) self.layer2 = nn.Conv2d(input_channels, channels, kernel_size=4, stride=2, padding=1) # self.bn2 = nn.BatchNorm2d(channels) self.layer3 = nn.Conv2d(channels, channels, kernel_size=4, stride=2, padding=1) self.layer4 = nn.Conv2d(channels, channels, kernel_size=4, stride=2, padding=1) self.channel = channels self.fc1_rgb1 = nn.Linear(channels * 1 * 64 * 64, latent_size) self.fc2_rgb1 = nn.Linear(channels * 1 * 64 * 64, latent_size) self.fc1_depth1 = nn.Linear(channels * 1 * 64 * 64, latent_size) self.fc2_depth1 = nn.Linear(channels * 1 * 64 * 64, latent_size) self.fc1_rgb2 = nn.Linear(channels * 1 * 32 * 32, latent_size) self.fc2_rgb2 = nn.Linear(channels * 1 * 32 * 32, latent_size) self.fc1_depth2 = nn.Linear(channels * 1 * 32 * 32, latent_size) self.fc2_depth2 = nn.Linear(channels * 1 * 32 * 32, latent_size) self.fc1_rgb3 = nn.Linear(channels * 1 * 16 * 16, latent_size) self.fc2_rgb3 = nn.Linear(channels * 1 * 16 * 16, latent_size) self.fc1_depth3 = nn.Linear(channels * 1 * 16 * 16, latent_size) self.fc2_depth3 = nn.Linear(channels * 1 * 16 * 16, latent_size) self.leakyrelu = nn.LeakyReLU() self.tanh = torch.nn.Tanh() # yy:用于计算两个分布之间的KL散度:KL散度用于衡量两个分布之间的差异 def kl_divergence(self, posterior_latent_space, prior_latent_space): kl_div = kl.kl_divergence(posterior_latent_space, prior_latent_space) return kl_div # yy: 重参数化技巧:通常用于从概率分布中采样潜在变量,特别是在生成模型(如变分自编码器)中常见 def reparametrize(self, mu, logvar): # yy:logvar 是潜在变量的对数方差,它通常用于表示潜在变量的分布的离散程度。 # std 计算了标准差,是通过将 logvar 取指数运算(exp)来获得,再乘以 0.5 得到的。 std = logvar.mul(0.5).exp_() # yy: torch.cuda.FloatTensor(std.size()).normal_() 生成一个大小与 std 相同的随机噪声向量,其中元素是从标准正态分布(均值为0,标准差为1)中随机采样的。 eps = torch.cuda.FloatTensor(std.size()).normal_() # eps 是生成的随机噪声向量,Variable是对Tensor的一个封装。 eps = Variable(eps) return eps.mul(std).add_(mu) def forward(self, rgb_feat, depth_feat): rgb_feat = self.layer3(self.leakyrelu(self.layer1(rgb_feat))) depth_feat = self.layer4(self.leakyrelu(self.layer2(depth_feat))) if rgb_feat.size(2) == 64: rgb_feat = rgb_feat.view(-1, self.channel * 1 * 64 * 64) depth_feat = depth_feat.view(-1, self.channel * 1 * 64 * 64) mu_rgb = self.fc1_rgb1(rgb_feat) logvar_rgb = self.fc2_rgb1(rgb_feat) mu_depth = self.fc1_depth1(depth_feat) logvar_depth = self.fc2_depth1(depth_feat) elif rgb_feat.size(2) == 32: rgb_feat = rgb_feat.view(-1, self.channel * 1 * 32 * 32) depth_feat = depth_feat.view(-1, self.channel * 1 * 32 * 32) mu_rgb = self.fc1_rgb2(rgb_feat) logvar_rgb = self.fc2_rgb2(rgb_feat) mu_depth = self.fc1_depth2(depth_feat) logvar_depth = self.fc2_depth2(depth_feat) elif rgb_feat.size(2) == 16: rgb_feat = rgb_feat.view(-1, self.channel * 1 * 16 * 16) depth_feat = depth_feat.view(-1, self.channel * 1 * 16 * 16) mu_rgb = self.fc1_rgb3(rgb_feat) logvar_rgb = self.fc2_rgb3(rgb_feat) mu_depth = self.fc1_depth3(depth_feat) logvar_depth = self.fc2_depth3(depth_feat) mu_depth = self.tanh(mu_depth) mu_rgb = self.tanh(mu_rgb) logvar_depth = self.tanh(logvar_depth) logvar_rgb = self.tanh(logvar_rgb) # yy:利用 torch.distributions 模块创建独立分布,其中 Normal 表示正态分布,Independent 表示独立分布。这一步是为了计算KL散度。 z_rgb = self.reparametrize(mu_rgb, logvar_rgb) dist_rgb = Independent(Normal(loc=mu_rgb, scale=torch.exp(logvar_rgb)), 1) z_depth = self.reparametrize(mu_depth, logvar_depth) dist_depth = Independent(Normal(loc=mu_depth, scale=torch.exp(logvar_depth)), 1) # yy:计算dist_rgb, dist_depth两部分的KL散度 bi_di_kld = torch.mean(self.kl_divergence(dist_rgb, dist_depth)) + torch.mean(self.kl_divergence(dist_depth, dist_rgb)) # yy:计算 z_rgb 和 z_depth 的二进制交叉熵(BCELoss)以衡量它们之间的相似性。这一步是为了使两者的潜在表示更相似。 z_rgb_norm = torch.sigmoid(z_rgb) z_depth_norm = torch.sigmoid(z_depth) ce_rgb_depth = CE(z_rgb_norm,z_depth_norm.detach()) ce_depth_rgb = CE(z_depth_norm, z_rgb_norm.detach()) # yy:是将两部分的交叉熵合并并减去KL散度得到的损失.latent_loss 的最小化有助于模型学习独立和有意义的表示 latent_loss = ce_rgb_depth+ce_depth_rgb-bi_di_kld # print(ce_rgb_depth.item(), ce_depth_rgb.item(), bi_di_kld.item()) # latent_loss = torch.abs(cos_sim(z_rgb,z_depth)).sum() return latent_loss
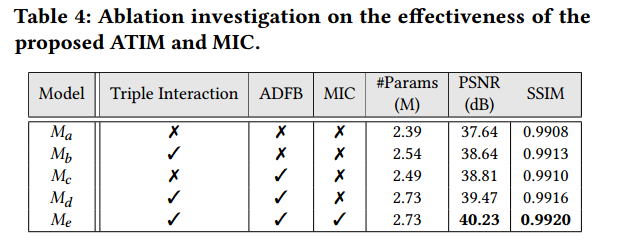
5. 各组件消融
四. 学习的地方
1.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号