个人项目:论文查重
| 这个作业属于哪个课程 | 计科国际班软工 |
|---|---|
| 这个作业要求在哪里 | |
| 这个作业的目标 | 编写论文查重程序 |
1.github仓库:https://github.com/yyya77/3119009472
2.PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 540 | 680 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 90 |
| · Design Spec | · 生成设计文档 | 30 | 60 |
| · Design Review | · 设计复审 | 30 | 40 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 60 | 80 |
| · Coding | · 具体编码 | 300 | 360 |
| · Code Review | · 代码复审 | 30 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 60 |
| Reporting | 报告 | 50 | 75 |
| · Test Repor | · 测试报告 | 20 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 30 |
| Sum up | 合计 | 600 | 765 |
3.计算模块接口的设计与实现过程:
算法分析:
基于Python jieba分词的汉明距离进行文本相似度分析
整体思想如下:
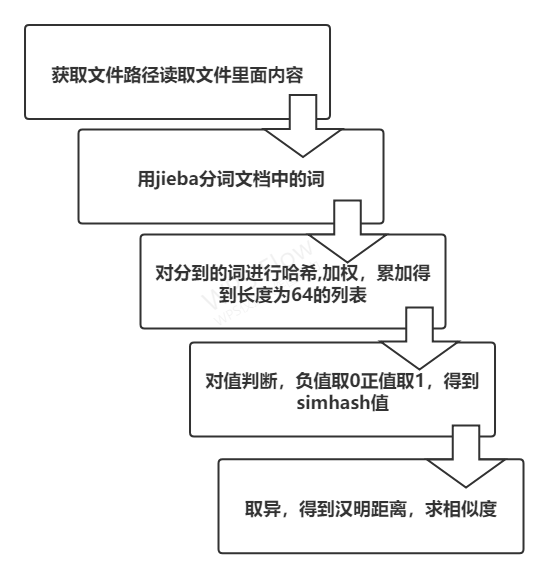
关于simhash可参照:浅谈simhash及其python实现
原理:
simhash是一种局部敏感hash。我们都知道什么是hash。那什么叫局部敏感呢,假定A、B具有一定的相似性,在hash之后,仍然能保持这种相似性,就称之为局部敏感hash。
在上文中,我们得到一个文档的关键词,取得一篇文章关键词集合,又会降低对比效率,我们可以通过hash的方法,把上述得到的关键词集合hash成一串二进制,这样我们直接对比二进制数,看其相似性就可以得到两篇文档的相似性,在查看相似性的时候我们采用海明距离,即在对比二进制的时候,我们看其有多少位不同,就称海明距离为多少。在这里,我是将文章simhash得到一串64位的二进制,一般取海明距离为3作为阈值,即在64位二进制中,只有三位不同,我们就认为两个文档是相似的。当然了,这里可以根据自己的需求来设置阈值。
就这样,我们把一篇文档用一个二进制代表了,也就是把一个文档hash之后得到一串二进制数的算法,称这个hash为simhash。
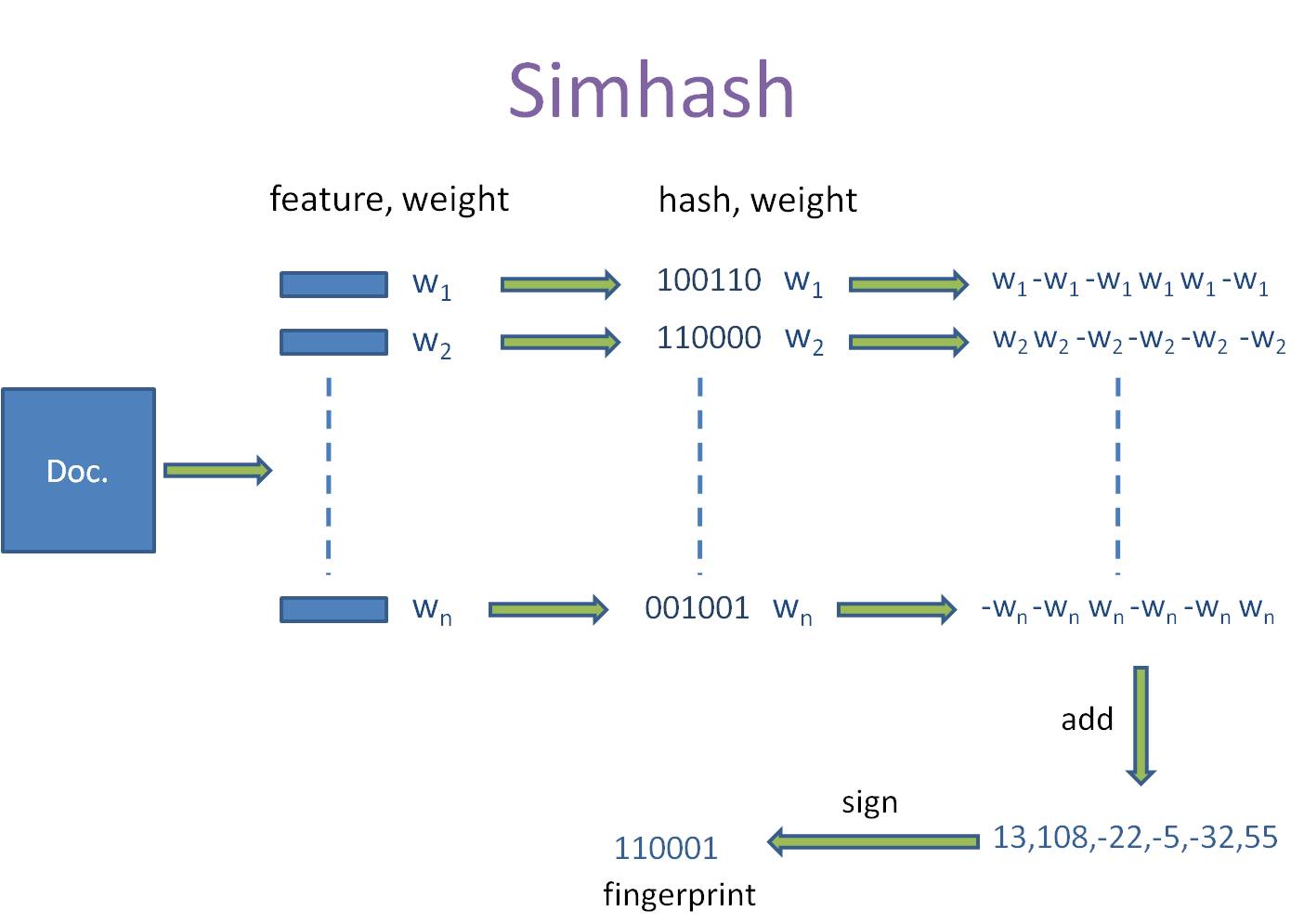
由此取权重最高的多个值求出两篇文章的simhash值再进行比较得到汉明距离,最后通过汉明距离求得两文件的相似度。
在程序中我定义了五个函数一个类以确保程序正常运行:
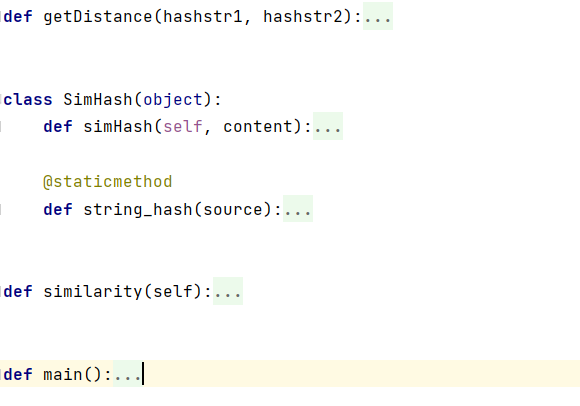
部分函数代码:
jieba分词:
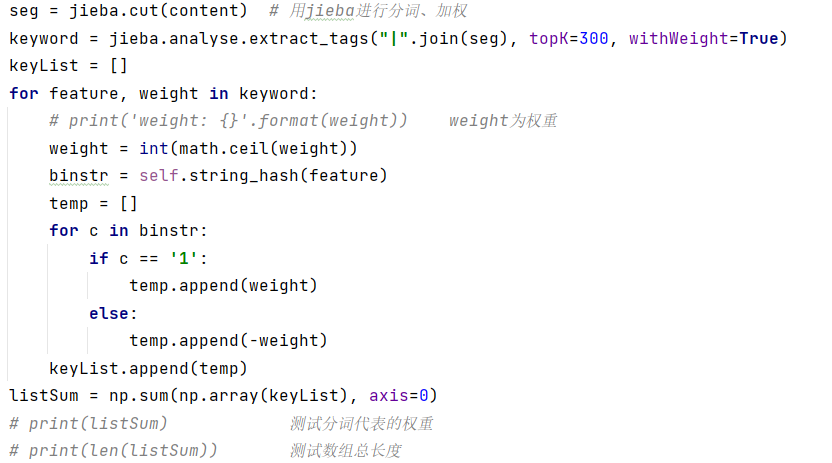
求汉明距离:

算相似率:

4.计算模块接口部分的性能改进:
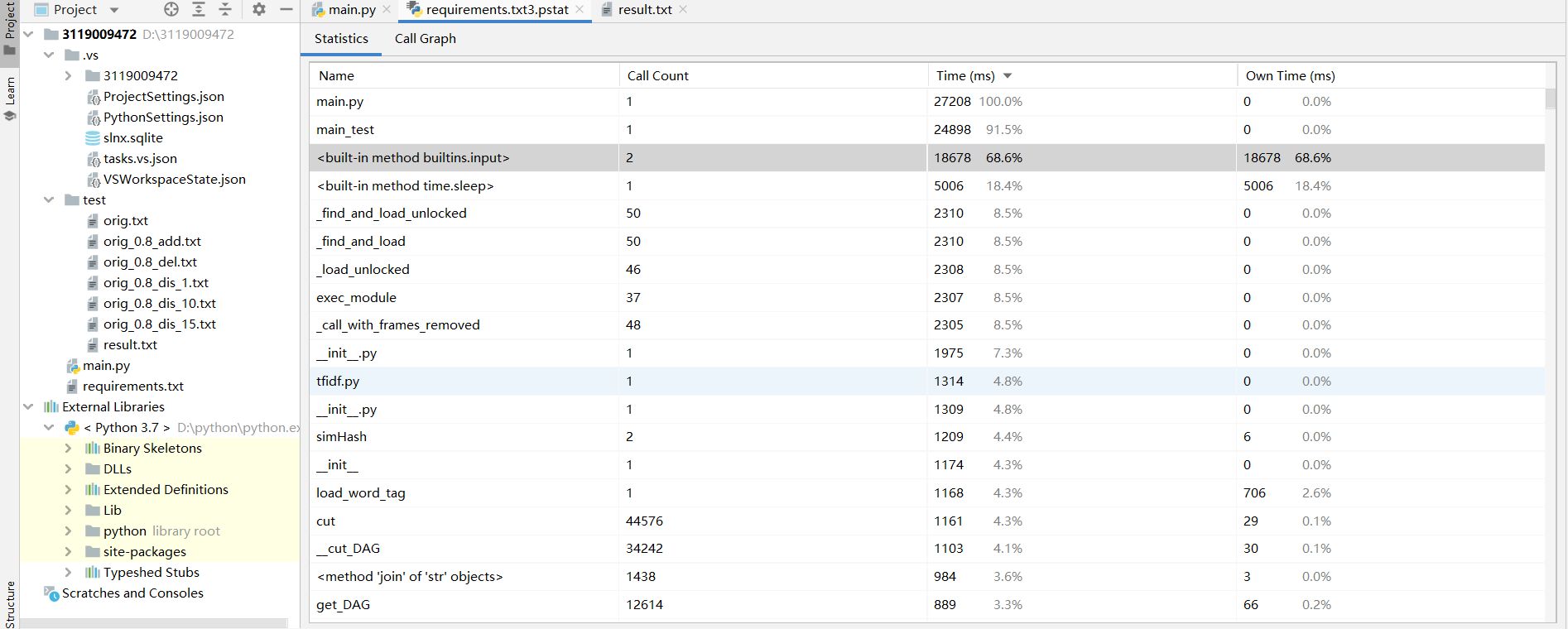
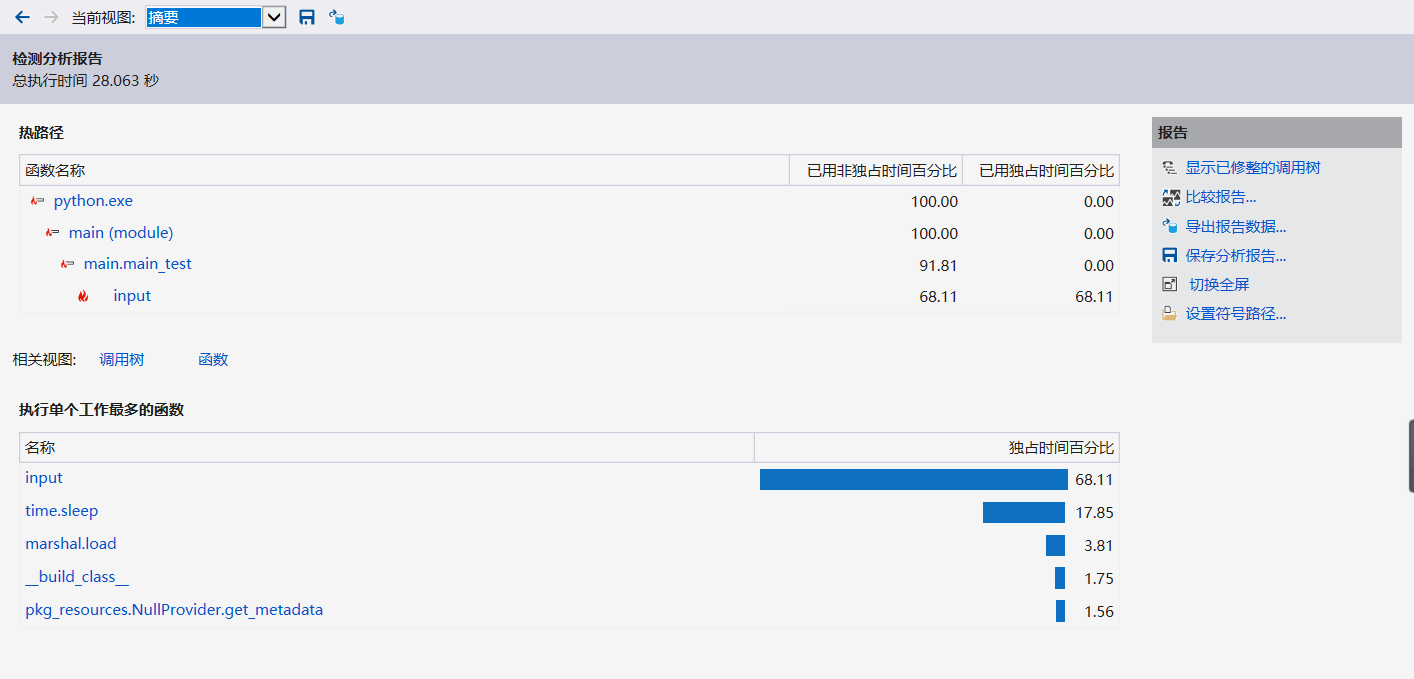
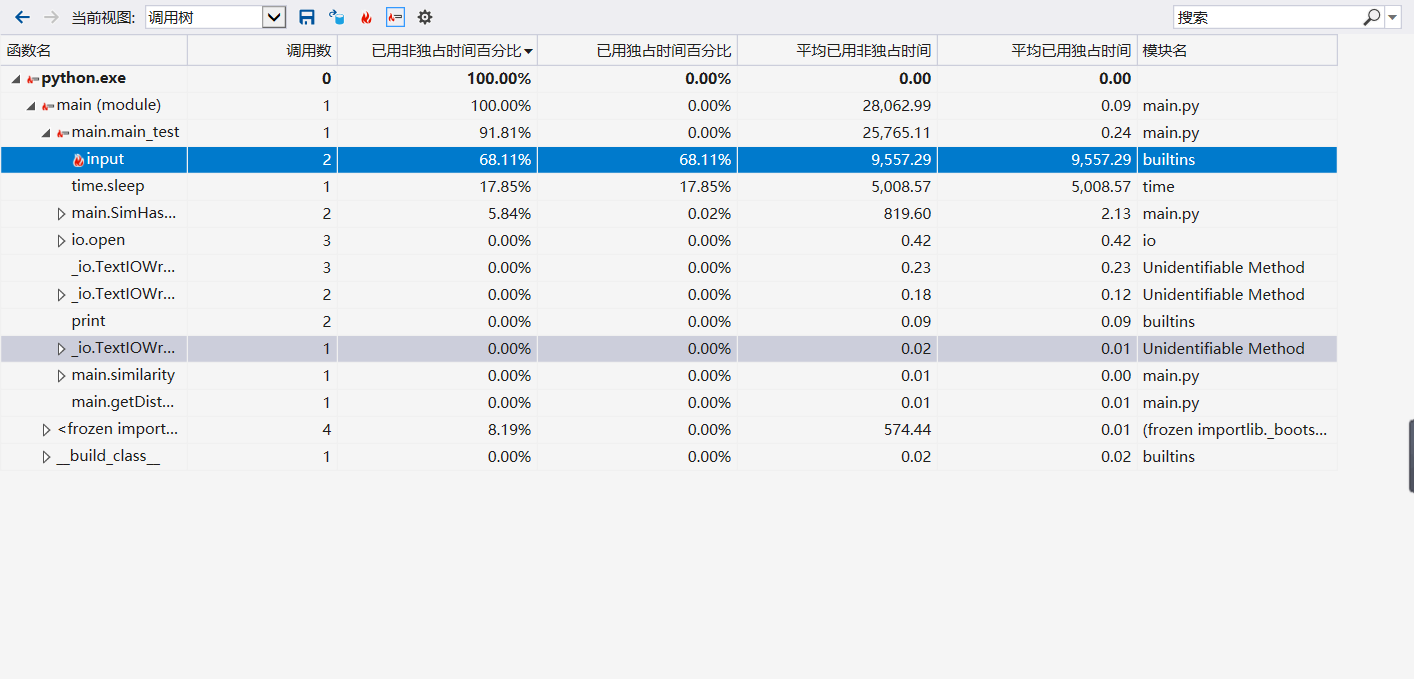
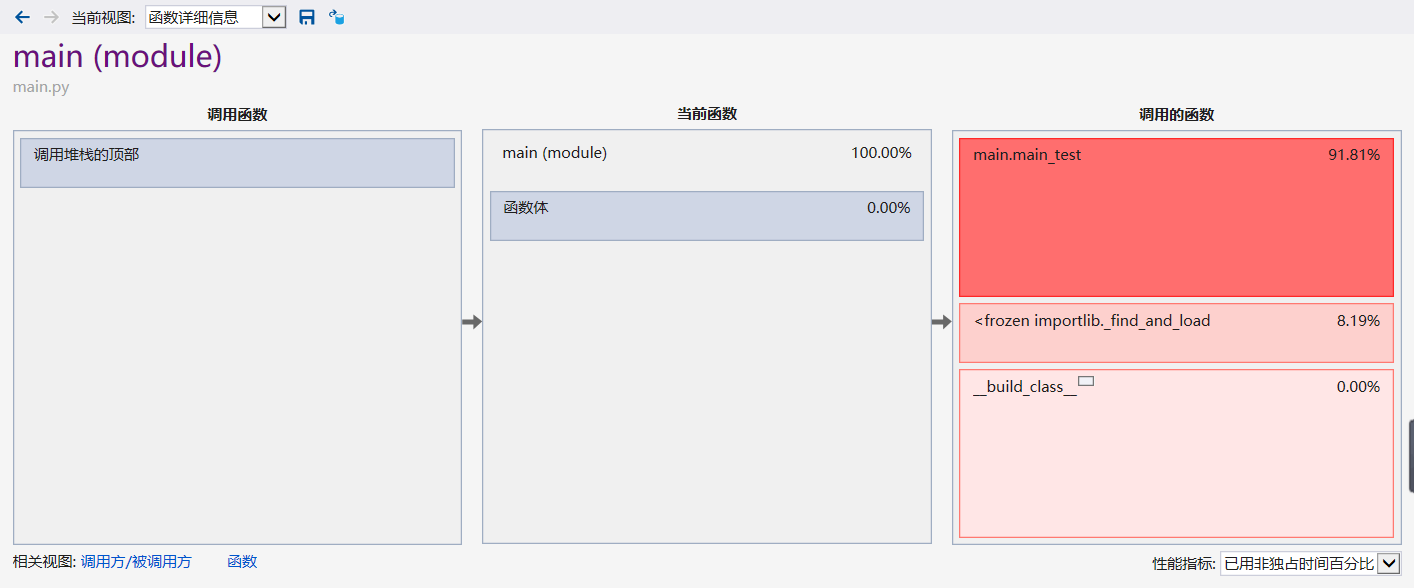
性能分析图:
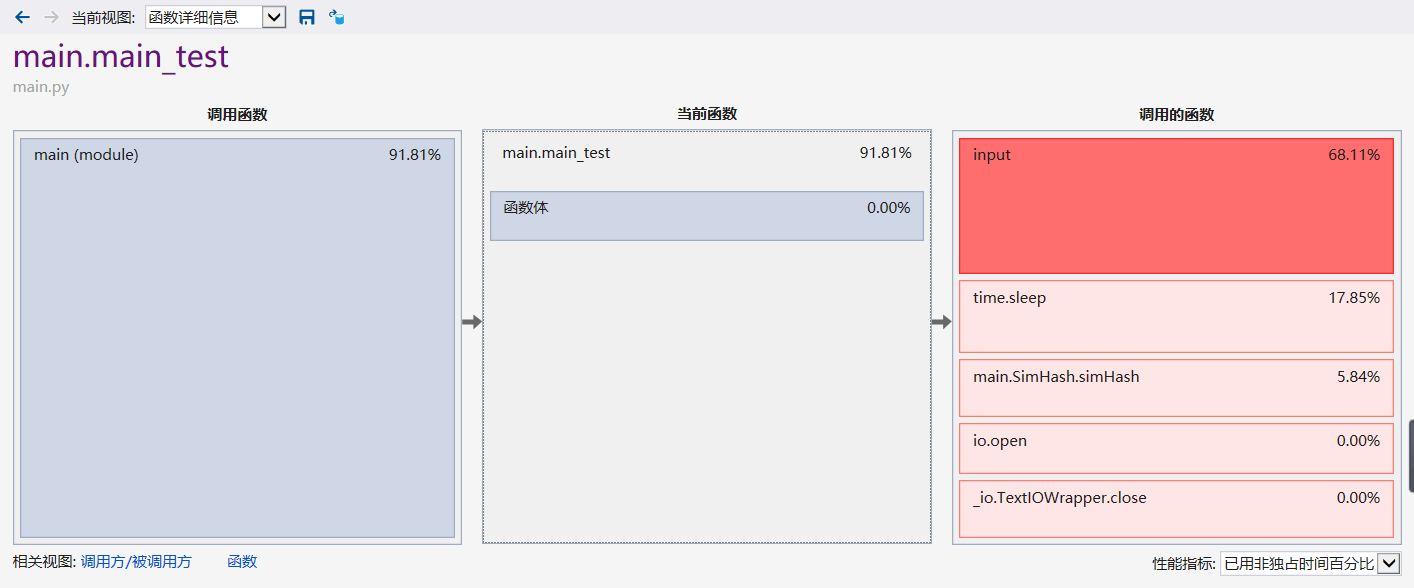
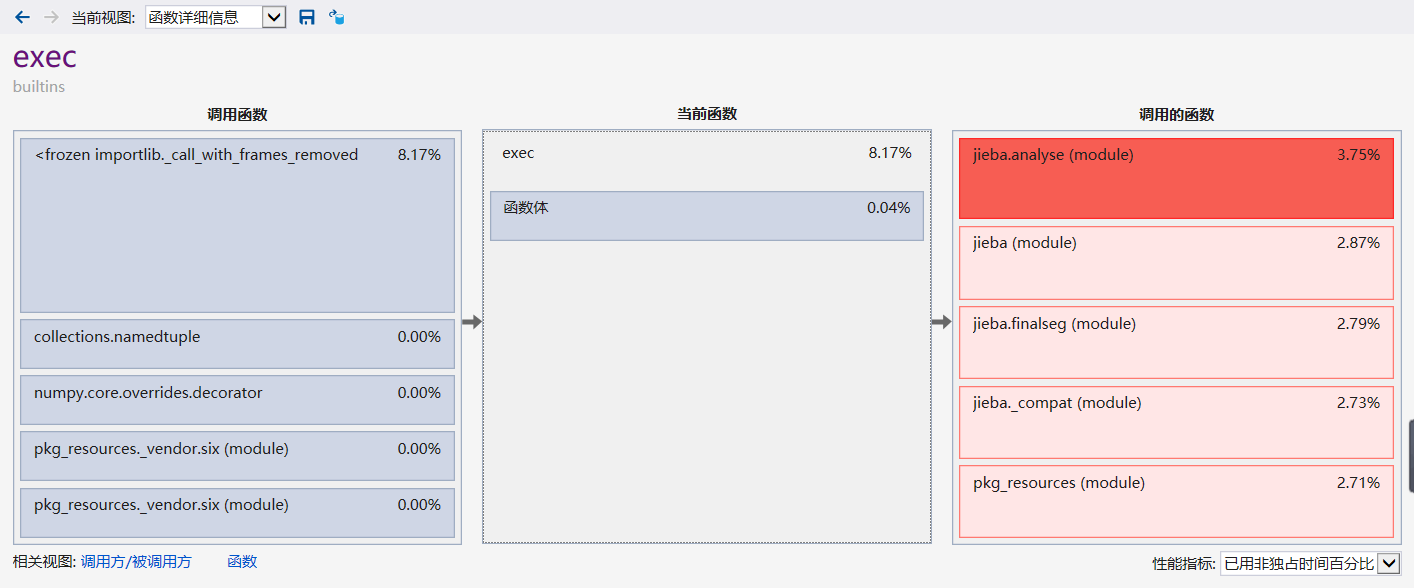
关系图:
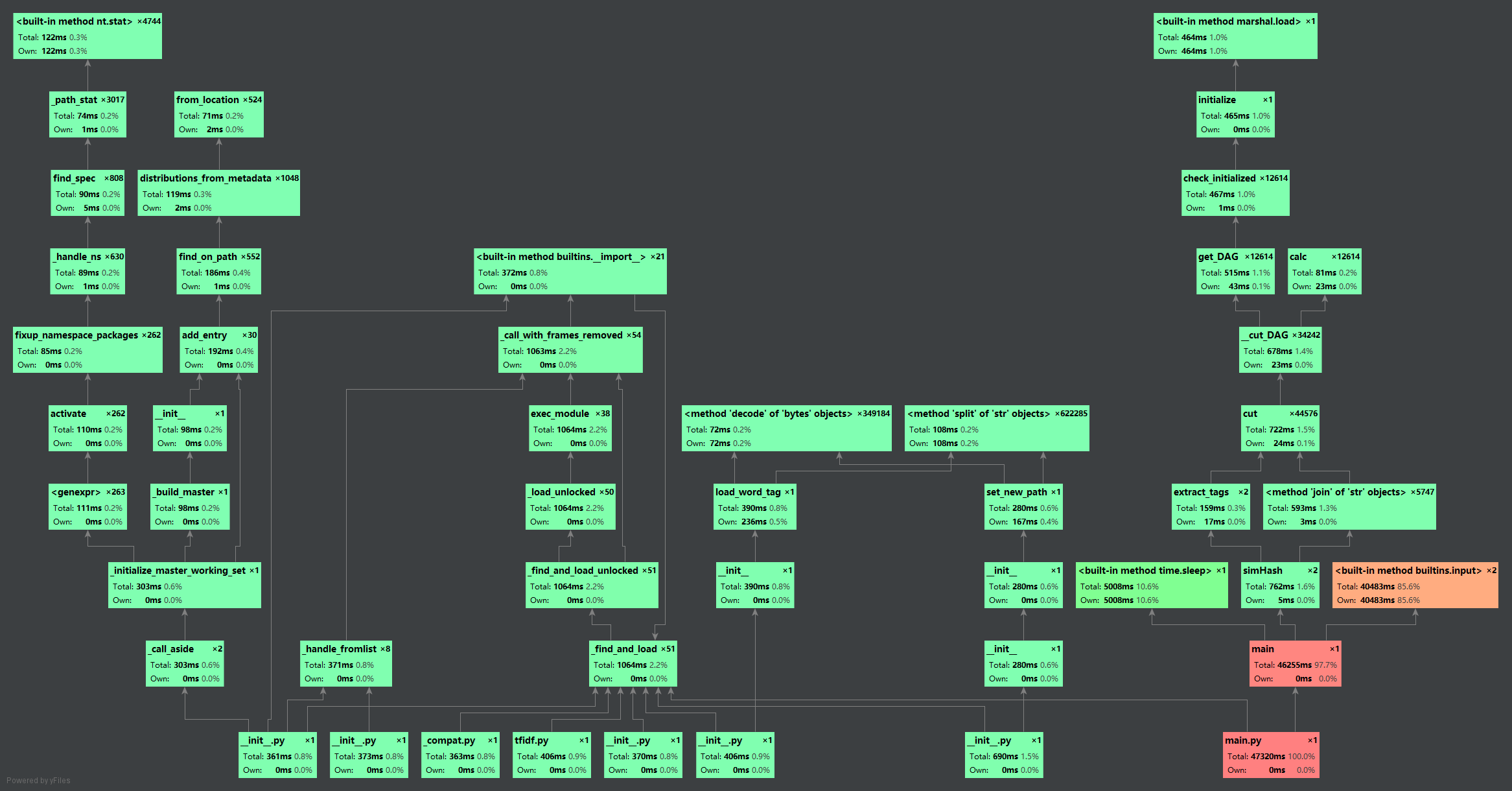
由性能测试可以看到,由于我使用input()来使用户输入文件路径,所以程序运行很大一部分时间取决于用户输入路径的速度,去除手动输入时间和time.sleep()结果呈现时间,程序运行约762ms,达到作业要求,同时在测试时的结果得出运行总时长也是在0.8s左右。结果如图下:

反思:可以优化的地方还有很多,比如简化输入路径,如输入名字即可找到文件,加快程序总运行速度。
5.计算模块部分单元测试展示:
测试方法:用循环把想得到的情况都遍历一遍,得出程序覆盖率

测试的函数有主函数main()以及主函数里面调用的getDistance(),simHash(),string_hash(),similarity()等。
测试数据构造思路以及测试结果:
1.正常运行;
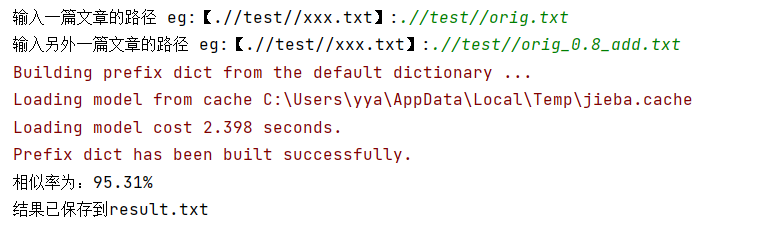
2.输入的路径不正确;

3.输入的路径正确但是文本文件内无内容;

测试结果:结果将存入文件result.txt内:

程序覆盖率100%:
6.计算模块部分异常处理说明:
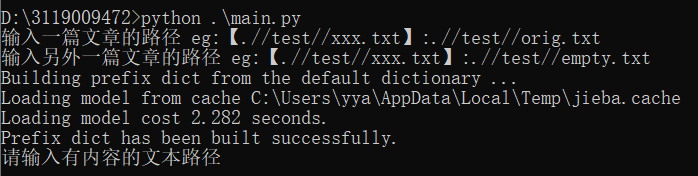
1.输入的路径不正确;

2.输入的路径正确但是文本文件内无内容;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号