
Hadoop:开发机运行spark程序,抛出异常:ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
问题:
windows开发机运行spark程序,抛出异常:ERROR Shell: Failed to locate the winutils binary in the hadoop binary path,但是可以正常执行,并不影响结果。
18/07/02 19:46:08 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 18/07/02 19:46:08 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries. at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:355) at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:370) at org.apache.hadoop.util.Shell.<clinit>(Shell.java:363) at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:79) at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:116) at org.apache.hadoop.security.Groups.<init>(Groups.java:93) at org.apache.hadoop.security.Groups.<init>(Groups.java:73) at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:293) at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:283) at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:260) at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:789) at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:774) at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:647) at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2198) at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2198) at scala.Option.getOrElse(Option.scala:120) at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2198) at org.apache.spark.SparkContext.<init>(SparkContext.scala:322) at org.apache.spark.api.java.JavaSparkContext.<init>(JavaSparkContext.scala:59) at com.lm.sparkLearning.utils.SparkUtils.getJavaSparkContext(SparkUtils.java:31) at com.lm.sparkLearning.rdd.RddLearning.main(RddLearning.java:30) 18/07/02 19:46:14 WARN RddLearning: singleOperateRdd mapRdd->[2, 3, 4, 4] 18/07/02 19:46:14 WARN RddLearning: singleOperateRdd flatMapRdd->[2, 3, 2, 3, 2, 3, 2, 3] 18/07/02 19:46:14 WARN RddLearning: singleOperateRdd filterRdd->[3, 3] 18/07/02 19:46:14 WARN RddLearning: singleOperateRdd distinctRdd->[2, 1, 3] 18/07/02 19:46:14 WARN RddLearning: singleOperateRdd sampleRdd->[1, 3] 18/07/02 19:46:14 WARN RddLearning: the program end
这里所执行的程序是:
package com.lm.sparkLearning.rdd; import java.util.Arrays; import java.util.Iterator; import java.util.List; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.VoidFunction; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import com.lm.sparkLearning.utils.SparkUtils; public class RddLearning { private static Logger logger = LoggerFactory.getLogger(RddLearning.class); public static void main(String[] args) { JavaSparkContext jsc = SparkUtils.getJavaSparkContext("RDDLearning", "local[2]", "WARN"); SparkUtils.createRddExternal(jsc, "D:/README.txt"); singleOperateRdd(jsc); jsc.stop(); logger.warn("the program end"); } public static void singleOperateRdd(JavaSparkContext jsc) { List<Integer> nums = Arrays.asList(new Integer[] { 1, 2, 3, 3 }); JavaRDD<Integer> numsRdd = SparkUtils.createRddCollect(jsc, nums); // map JavaRDD<Integer> mapRdd = numsRdd.map(new Function<Integer, Integer>() { private static final long serialVersionUID = 1L; @Override public Integer call(Integer v1) throws Exception { return (v1 + 1); } }); logger.warn("singleOperateRdd mapRdd->" + mapRdd.collect().toString()); JavaRDD<Integer> flatMapRdd = numsRdd.flatMap(new FlatMapFunction<Integer, Integer>() { private static final long serialVersionUID = 1L; @Override public Iterable<Integer> call(Integer t) throws Exception { return Arrays.asList(new Integer[] { 2, 3 }); } }); logger.warn("singleOperateRdd flatMapRdd->" + flatMapRdd.collect().toString()); JavaRDD<Integer> filterRdd = numsRdd.filter(new Function<Integer, Boolean>() { private static final long serialVersionUID = 1L; @Override public Boolean call(Integer v1) throws Exception { return v1 > 2; } }); logger.warn("singleOperateRdd filterRdd->" + filterRdd.collect().toString()); JavaRDD<Integer> distinctRdd = numsRdd.distinct(); logger.warn("singleOperateRdd distinctRdd->" + distinctRdd.collect().toString()); JavaRDD<Integer> sampleRdd = numsRdd.sample(false, 0.5); logger.warn("singleOperateRdd sampleRdd->" + sampleRdd.collect().toString()); } }
解决方案:
1.下载winutils的windows版本
GitHub上,有人提供了winutils的windows的版本,项目地址是:https://github.com/srccodes/hadoop-common-2.2.0-bin,直接下载此项目的zip包,下载后是文件名是hadoop-common-2.2.0-bin-master.zip,随便解压到一个目录。
2.配置环境变量
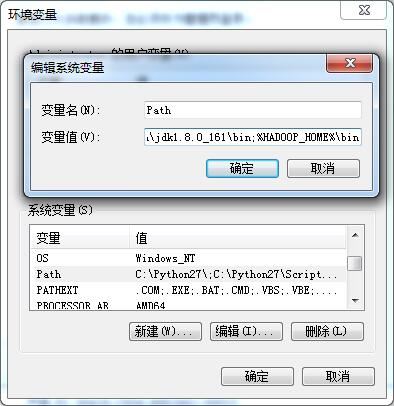
增加用户变量HADOOP_HOME,值是下载的zip包解压的目录,然后在系统变量path里增加$HADOOP_HOME\bin 即可。
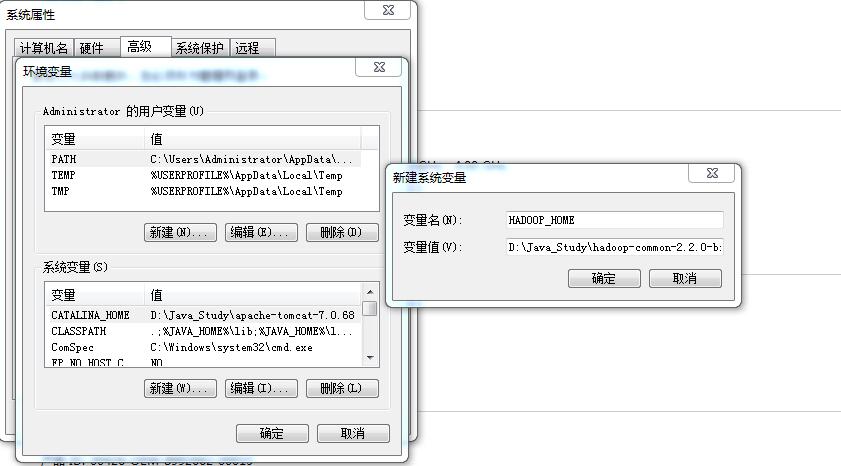
添加“%HADOOP%\bin”到path
再次运行程序,正常执行。
基础才是编程人员应该深入研究的问题,比如:
1)List/Set/Map内部组成原理|区别
2)mysql索引存储结构&如何调优/b-tree特点、计算复杂度及影响复杂度的因素。。。
3)JVM运行组成与原理及调优
4)Java类加载器运行原理
5)Java中GC过程原理|使用的回收算法原理
6)Redis中hash一致性实现及与hash其他区别
7)Java多线程、线程池开发、管理Lock与Synchroined区别
8)Spring IOC/AOP 原理;加载过程的。。。
【+加关注】。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号