
SPARK:作业基本运行原理
Spark作业基本运行原理:
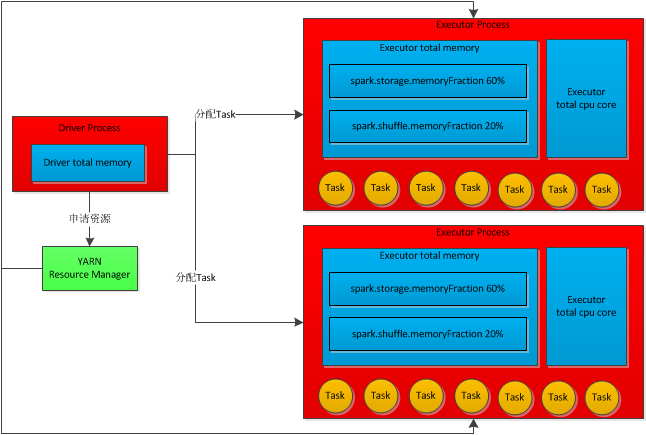
我们使用spark-submit提交一个spark作业之后,这个作业就会启动一个对应的Driver进程。根据你使用的部署模式(deploy-mode)不同:
1)Driver进程可能在本地启动,也可能在集群中的某个工作节点上启动;
2)Driver进程本身会根据我们设置的参数,占有一定数量的内存和CPU core。
而Driver进程要做的第一件事情,就是向集群管理器(可以是Spark Standlone集群,也可以是其他的资源管理集群,比如:YARN作为资源管理集群。)申请运行spark作业需要使用的资源,这里的资源指的是Executor进程。YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数据量的Executor进程,每个Executor进程都会占有一定数量的内存和CPU core。
在申请到了作业执行所需要的资源之后,Driver进程就会开始调用和执行编写的作业代码。Driver进程会将编写的Spark作业代码拆分为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批task,然后将这些task分配到各个Executor进程中执行。
task是最小的计算单元,负责执行一模一样的计算逻辑(编写代码的某个片段),只是每个task处理的数据不同而已。一个stage的所有task都执行完成之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的task的输入数据就是上一个stage输出的中间结果。如此循往复,直到将我们自己的编写的代码全部执行完成,并且计算完所有的数据,得到我们想要的结果为止。
参考《Spark性能优化:资源调优篇》
Spark不错的文章:
基础才是编程人员应该深入研究的问题,比如:
1)List/Set/Map内部组成原理|区别
2)mysql索引存储结构&如何调优/b-tree特点、计算复杂度及影响复杂度的因素。。。
3)JVM运行组成与原理及调优
4)Java类加载器运行原理
5)Java中GC过程原理|使用的回收算法原理
6)Redis中hash一致性实现及与hash其他区别
7)Java多线程、线程池开发、管理Lock与Synchroined区别
8)Spring IOC/AOP 原理;加载过程的。。。
【+加关注】。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号