
Spark&Hive:如何使用scala开发spark访问hive作业,如何使用yarn resourcemanager。
- 背景:
接到任务,需要在一个一天数据量在460亿条记录的hive表中,筛选出某些host为特定的值时才解析该条记录的http_content中的经纬度:
解析规则譬如:
需要解析host: api.map.baidu.com
需要解析的规则:"result":{"location":{"lng":120.25088311933617,"lat":30.310684375444877},
"confidence":25
需要解析http_conent:renderReverse&&renderReverse({"status":0,"result":{"location":{"lng":120.25088311933617,"lat":30.310684375444877},"formatted_address":"???????????????????????????????????????","business":"","addressComponent":{"country":"??????","country_code":0,"province":"?????????","city":"?????????","district":"?????????","adcode":"330104","street":"????????????","street_number":"","direction":"","distance":""},"pois":[{"addr":"????????????5277???","cp":" ","direction":"???","distance":"68","name":"????????????????????????????????????","poiType":"????????????","point":{"x":120.25084961536486,"y":30.3112150
- Scala代码实现“访问hive,并保存结果到hive表”的spark任务:
开发工具为IDEA16,开发语言为scala,开发包有了spark对应集群版本下的很多个jar包,和对应集群版本下的很多个jar包,引入jar包:
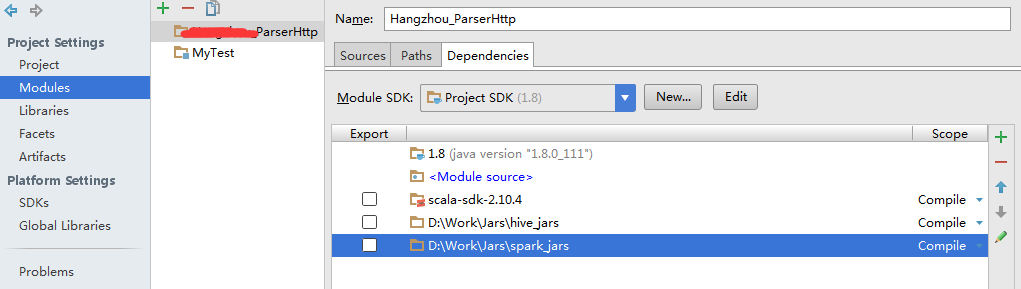
scala代码:
import java.sql.{Connection, DriverManager, PreparedStatement, Timestamp} import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.sql.hive.HiveContext import java.util import java.util.{UUID, Calendar, Properties} import org.apache.spark.rdd.JdbcRDD import org.apache.spark.sql.{Row, SaveMode, SQLContext} import org.apache.spark.storage.StorageLevel import org.apache.spark.{sql, SparkContext, SparkConf} import org.apache.spark.sql.DataFrameHolder /** * temp http_content **/ case class Temp_Http_Content_ParserResult(success: String, lnglatType: String, longitude: String, Latitude: String, radius: String) /** * Created by Administrator on 2016/11/15. */ object ParserMain { def main(args: Array[String]): Unit = { val conf = new SparkConf() //.setAppName("XXX_ParserHttp").setMaster("local[1]").setMaster("spark://172.21.7.10:7077").setJars(List("xxx.jar")) //.set("spark.executor.memory", "10g") val sc = new SparkContext(conf) val hiveContext = new HiveContext(sc) // use abc_hive_db; hiveContext.sql("use abc_hive_db") // error date format:2016-11-15,date format must be 20161115 val rdd = hiveContext.sql("select host,http_content from default.http where hour>='20161115' and hour<'20161116'") // toDF() method need this line... import hiveContext.implicits._ // (success, lnglatType, longitude, latitude, radius) val rdd2 = rdd.map(s => parse_http_context(s.getAs[String]("host"), s.getAs[String]("http_content"))).filter(s => s._1).map(s => Temp_Http_Content_ParserResult(s._1.toString(), s._2, s._3, s._4, s._5)).toDF() rdd2.registerTempTable("Temp_Http_Content_ParserResult_20161115") hiveContext.sql("create table Temp_Http_Content_ParserResult20161115 as select * from Temp_Http_Content_ParserResult_20161115") sc.stop() } /** * @ summary: 解析http_context字段信息 * @ param http_context 参数信息 * @ result 1:是否匹配成功; * @ result 2:匹配出的是什么经纬度的格式: * @ result 3:经度; * @ result 4:纬度, * @ result 5:radius **/ def parse_http_context(host: String, http_context: String): (Boolean, String, String, String, String) = { if (host == null || http_context == null) { return (false, "", "", "", "") } // val result2 = parse_http_context(“api.map.baidu.com”,"renderReverse&&renderReverse({\"status\":0,\"result\":{\"location\":{\"lng\":120.25088311933617,\"lat\":30.310684375444877},\"formatted_address\":\"???????????????????????????????????????\",\"business\":\"\",\"addressComponent\":{\"country\":\"??????\",\"country_code\":0,\"province\":\"?????????\",\"city\":\"?????????\",\"district\":\"?????????\",\"adcode\":\"330104\",\"street\":\"????????????\",\"street_number\":\"\",\"direction\":\"\",\"distance\":\"\"},\"pois\":[{\"addr\":\"????????????5277???\",\"cp\":\" \",\"direction\":\"???\",\"distance\":\"68\",\"name\":\"????????????????????????????????????\",\"poiType\":\"????????????\",\"point\":{\"x\":120.25084961536486,\"y\":30.3112150") // println(result2._1 + ":" + result2._2 + ":" + result2._3 + ":" + result2._4 + ":" + result2._5) var success = false var lnglatType = "" var longitude = "" var latitude = "" var radius = "" var lowerCaseHost = host.toLowerCase().trim(); val lowerCaseHttp_Content = http_context.toLowerCase() // api.map.baidu.com // "result":{"location":{"lng":120.25088311933617,"lat":30.310684375444877}, // "confidence":25 // --renderReverse&&renderReverse({"status":0,"result":{"location":{"lng":120.25088311933617,"lat":30.310684375444877},"formatted_address":"???????????????????????????????????????","business":"","addressComponent":{"country":"??????","country_code":0,"province":"?????????","city":"?????????","district":"?????????","adcode":"330104","street":"????????????","street_number":"","direction":"","distance":""},"pois":[{"addr":"????????????5277???","cp":" ","direction":"???","distance":"68","name":"????????????????????????????????????","poiType":"????????????","point":{"x":120.25084961536486,"y":30.3112150 if (lowerCaseHost.equals("api.map.baidu.com")) { val indexLng = lowerCaseHttp_Content.indexOf("\"lng\"") val indexLat = lowerCaseHttp_Content.indexOf("\"lat\"") if (lowerCaseHttp_Content.indexOf("\"location\"") != -1 && indexLng != -1 && indexLat != -1) { var splitstr: String = "\\,|\\{|\\}" var uriItems: Array[String] = lowerCaseHttp_Content.split(splitstr) var tempItem: String = "" lnglatType = "BD" success = true for (uriItem <- uriItems) { tempItem = uriItem.trim() if (tempItem.startsWith("\"lng\":")) { longitude = tempItem.replace("\"lng\":", "").trim() } else if (tempItem.startsWith("\"lat\":")) { latitude = tempItem.replace("\"lat\":", "").trim() } else if (tempItem.startsWith("\"confidence\":")) { radius = tempItem.replace("\"confidence\":", "").trim() } } } } else if (lowerCaseHost.equals("loc.map.baidu.com")) { 。。。 } longitude = longitude.replace("\"", "") latitude = latitude.replace("\"", "") radius = radius.replace("\"", "") (success, lnglatType, longitude, latitude, radius) } }
打包,注意应为我们使用的hadoop&hive&spark on yarn的集群,我们这里并不需要想spark&hadoop一样还需要在执行spark-submit时将spark-hadoop-xx.jar打包进来,也不需要在submit-spark脚本.sh中制定jars参数,yarn会自动诊断我们需要哪些集群系统包;但是,如果你应用的是第三方的包,比如ab.jar,那打包时可以打包进来,也可以在spark-submit 参数jars后边指定特定的包。
- 写spark-submit提交脚本.sh:

- 当执行spark-submit脚本出现错误时,怎么应对呢?
注意,我们这里不是spark而是spark on yarn,当我们使用yarn-cluster方式提交时,界面是看不到任何日志新的。我们需要借助yarn管理系统来查看日志:
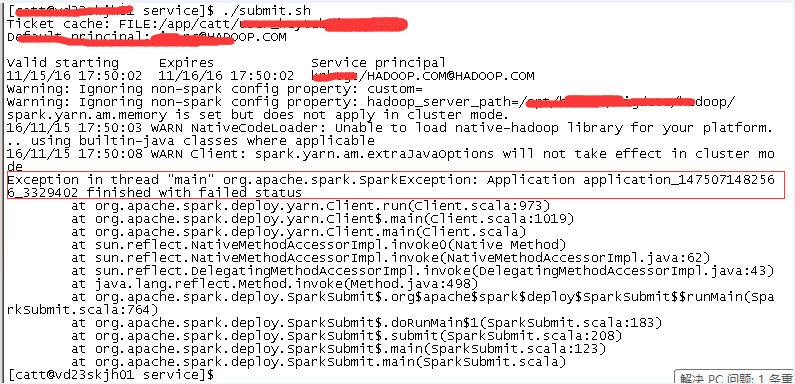
yarn logs -applicationId application_1475071482566_3329402
2、yarn页面查看日志
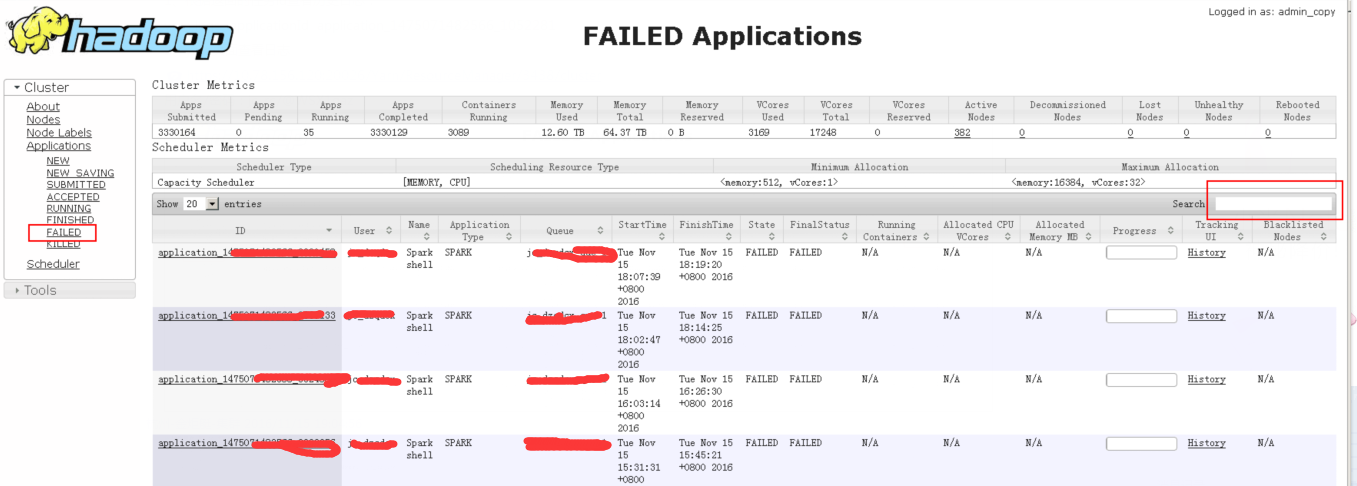
yarn application -kill application_1475071482566_3807023
或者从界面进入spark作业进度管理界面,进行查看作业具体执行进度,也可以kill application

Spark On YARN内存分配:http://blog.javachen.com/2015/06/09/memory-in-spark-on-yarn.html?utm_source=tuicool
基础才是编程人员应该深入研究的问题,比如:
1)List/Set/Map内部组成原理|区别
2)mysql索引存储结构&如何调优/b-tree特点、计算复杂度及影响复杂度的因素。。。
3)JVM运行组成与原理及调优
4)Java类加载器运行原理
5)Java中GC过程原理|使用的回收算法原理
6)Redis中hash一致性实现及与hash其他区别
7)Java多线程、线程池开发、管理Lock与Synchroined区别
8)Spring IOC/AOP 原理;加载过程的。。。
【+加关注】。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号