
Spark2.2(三十八):Spark Structured Streaming2.4之前版本使用agg和dropduplication消耗内存比较多的问题(Memory issue with spark structured streaming)调研
在spark中《Memory usage of state in Spark Structured Streaming》讲解Spark内存分配情况,以及提到了HDFSBackedStateStoreProvider存储多个版本的影响;从stackoverflow上也可以看到别人遇到了structured streaming中内存问题,同时也对问题做了分析《Memory issue with spark structured streaming》;另外可以从spark的官网问题修复列表中查看到如下内容:
1)在流聚合中从值中删除冗余密钥数据(Split out min retain version of state for memory in HDFSBackedStateStoreProvider)
问题描述:
HDFSBackedStateStoreProvider has only one configuration for minimum versions to retain of state which applies to both memory cache and files. As default version of "spark.sql.streaming.minBatchesToRetain" is set to high (100), which doesn't require strictly 100x of memory, but I'm seeing 10x ~ 80x of memory consumption for various workloads. In addition, in some cases, requiring 2x of memory is even unacceptable, so we should split out configuration for memory and let users adjust to trade-off memory usage vs cache miss.
In normal case, default value '2' would cover both cases: success and restoring failure with less than or around 2x of memory usage, and '1' would only cover success case but no longer require more than 1x of memory. In extreme case, user can set the value to '0' to completely disable the map cache to maximize executor memory.
修复情况:
对应官网bug情况概述《[SPARK-24717][SS] Split out max retain version of state for memory in HDFSBackedStateStoreProvider #21700》、《Split out min retain version of state for memory in HDFSBackedStateStoreProvider》
相关知识:
《Spark Structrued Streaming源码分析--(三)Aggreation聚合状态存储与更新》
HDFSBackedStateStoreProvider存储state的目录结构在该文章中介绍的,另外这些文件是一个系列,建议可以多读读,下边借用作者文章中的图展示下state存储目录结构:
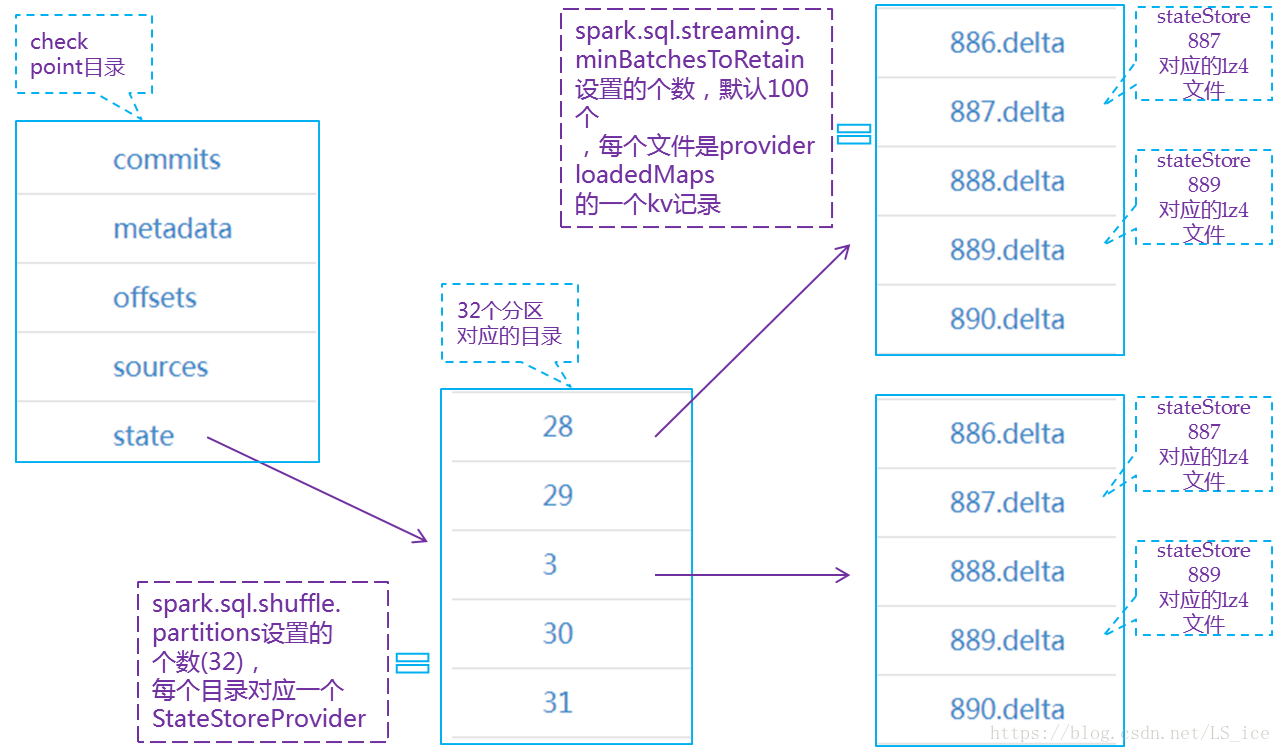
备注:spark2.2到spark2.4 checkpoint下offset下文件内容变化:
- Spark2.2
[MCP@CDH-143 ~]$ hadoop fs -cat /user/my/streaming/checkpoint/mycheckpoint2/offsets/99
v1
{
"batchWatermarkMs":1553382000000,
"batchTimestampMs":1553393700220,
"conf":{"spark.sql.shuffle.partitions":"600"}
}
{
"MyTopic2":
{
"23":40168,"17":36491,"8":42938,"11":44291,"20":48748,"2":44540,"5":44467,"14":43479,"13":41859,
"4":41019,"22":42281,"16":45344,"7":43083,"1":41771,"10":42247,"19":43330,"18":41246,"9":45828,
"21":40189,"3":46158,"12":48594,"15":44804,"6":43951,"0":49266
}
}
- Spark2.4
[MCP@CDH-143 ~]$ hadoop fs -cat /user/my/streaming/checkpoint_test/mycheckpoint1/offsets/1741
v1
{
"batchWatermarkMs":1557741000000,
"batchTimestampMs":1557747791249,
"conf":
{
"spark.sql.streaming.stateStore.providerClass":"org.apache.spark.sql.execution.streaming.state.HDFSBackedStateStoreProvider",
"spark.sql.streaming.flatMapGroupsWithState.stateFormatVersion":"2",
"spark.sql.streaming.multipleWatermarkPolicy":"min",
"spark.sql.streaming.aggregation.stateFormatVersion":"2",
"spark.sql.shuffle.partitions":"900"
}
}
{
"MyTopic1":
{
"17":180087368,"8":178758076,"11":177803667,"2":179003711,"5":179528808,"14":181918503,"13":179712700,"4":180465249,"16":179847967,
"7":180236912,"1":182446091,"10":179839083,"19":176659272,"18":178425265,"9":179766656,"3":177935949,"12":179457233,"15":178173350,
"6":179053634,"0":177830020
}
}
2)Spark2.4下解决情况,在HDFSBackedStateStoreProvider中为内存分配最大保留版本的状态(Remove redundant key data from value in streaming aggregation)
问题描述:
Key/Value of state in streaming aggregation is formatted as below:
- key: UnsafeRow containing group-by fields
- value: UnsafeRow containing key fields and another fields for aggregation results
which data for key is stored to both key and value.
This is to avoid doing projection row to value while storing, and joining key and value to restore origin row to boost performance, but while doing a simple benchmark test, I found it not much helpful compared to "project and join". (will paste test result in comment)
So I would propose a new option: remove redundant in stateful aggregation. I'm avoiding to modify default behavior of stateful aggregation, because state value will not be compatible between current and option enabled.
修复情况:
对应官网bug情况概述《[SPARK-24763][SS] Remove redundant key data from value in streaming aggregation #21733》、《Remove redundant key data from value in streaming aggregation》
可能能解决问题的另外办法:在spark2.3版本下自定义StateStoreProviver《https://github.com/chermenin/spark-states》
3)Spark2.4下测试情况,以及问题
- Spark程序业务:
读取kafka上topic,然后对流数据源进行聚合统计,之后输出到kafka的另外一个topic。
- 运行情况:
- 1)在cdh环境下(spark2.2)使用spark structured streaming,经常会出现内存溢出问题(state存储到内存版本数过多导致,这个bug已经在spark2.4修改),在spark2.2下解决方案:将executor内存设置大一些。我的提交脚本如下:
/spark-submit \ --conf “spark.yarn.executor.memoryOverhead=4096M” --num-executors 15 \ --executor-memory 46G \ --executor-cores 3 \ --driver-memory 6G \
这种情况下,可以保证spark程序可以长久的稳定运行,而且executor storage memory 低于10M(已经稳定运行超过20天)。
但是,实际上这个spark程序处理的数据量不大,15分钟触发一次trigger,每次trigger处理记录数30w条,每条记录大概有2000个列。
- 2)从spark2.4版本升级信息上,看到了spark2.4版本中解决了state存储消耗内存问题得到了解决。
于是在CDH下将spark升级到SPARK2.4,尝试去运行spark程序,发现使用内存却是降低了,
但是一个问题却出现了,随着运行时间的增长,executor的storage memory在不断增长(从Spark on Yarn Resource Manager UI上查看到"Executors->Storage Memory"),
这个程序已经运行了14天了(在SPARK2.2下以这个提交资源运行,正常运行时间不超过1天,就会出现Executor内存异常问题)。
spark2.4下程序提交脚本如下:
/spark-submit \ --conf “spark.yarn.executor.memoryOverhead=4096M” --num-executors 15 \ --executor-memory 9G \ --executor-cores 2 \ --driver-memory 6G \
Storage Memory跟随时间增长情况统计:
| Run-time(hour) | Storage Memory size(MB) | Memory growth rate(MB/hour) |
| 23.5H | 41.6MB/1.5GB | 1.770212766 |
| 108.4H | 460.2MB/1.5GB | 4.245387454 |
| 131.7H | 559.1MB/1.5GB | 4.245254366 |
| 135.4H | 575MB/1.5GB | 4.246676514 |
| 153.6H | 641.2MB/1.5GB | 4.174479167 |
| 219H | 888.1MB/1.5GB | 4.055251142 |
| 263H | 1126.4MB/1.5GB | 4.282889734 |
| 309H | 1228.8MB/1.5GB | 3.976699029 |
跟进信息请参考《https://issues.apache.org/jira/browse/SPARK-27648》
基础才是编程人员应该深入研究的问题,比如:
1)List/Set/Map内部组成原理|区别
2)mysql索引存储结构&如何调优/b-tree特点、计算复杂度及影响复杂度的因素。。。
3)JVM运行组成与原理及调优
4)Java类加载器运行原理
5)Java中GC过程原理|使用的回收算法原理
6)Redis中hash一致性实现及与hash其他区别
7)Java多线程、线程池开发、管理Lock与Synchroined区别
8)Spring IOC/AOP 原理;加载过程的。。。
【+加关注】。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号