

微服务架构的可观测性三要素:从监控到洞察的架构演进 - 实践
可观测性的演进背景:为什么微服务架构需要新的监控范式?
在传统的单体应用架构中,系统监控相对简单直接。我们通常只需要关注服务器的CPU、内存使用情况、数据库连接池状态以及应用日志中的错误信息,就能基本掌握系统的运行状态。这是因为单体应用的所有组件都运行在同一个进程中,调用链路清晰,日志集中,故障定位简单。然而,随着业务规模的不断扩大和技术的持续演进,微服务架构已经成为现代互联网应用的主流选择(扩展阅读:微服务可观测性的“1-3-5”理想:从理论到实践的故障恢复体系)。
微服务架构的监控挑战
微服务架构通过将单体应用拆分为一组小而自治的服务,带来了开发敏捷性、技术多样性和弹性扩展等优势。但与此同时,它也引入了前所未有的复杂性:
故障定位困难:一次用户请求可能涉及数十个服务,问题可能出现在任何一个环节
性能瓶颈模糊:接口响应时间变慢,可能是由某个底层服务的慢查询、网络延迟或资源竞争引起
依赖关系复杂:服务之间的调用关系动态变化,难以可视化呈现
在微服务环境中,传统的监控手段显得力不从心,因为它们主要针对“已知的未知问题”(known unknowns)——即我们预先知道可能发生的问题,并针对性地设置监控点。但微服务架构中更多的是“未知的未知问题”(unknown unknowns)——那些我们无法预见的异常情况和复杂的连锁反应。
从监控到可观测性的演进
监控(Monitoring)和可观测性(Observability)虽然相关,但存在本质区别。监控主要关注系统是否按预期运行,它是基于预先定义的指标和阈值进行检测和告警。而可观测性则强调从系统外部输出推断内部状态的能力,即使面对从未见过的新型故障。
可观测性概念并非计算机领域首创,它源自控制理论。匈牙利裔工程师鲁道夫·卡尔曼(Rudolf E. Kálmán)在1960年针对线性动态系统提出了这一概念。在控制论中,可观测性是指系统通过其外部输出推断内部状态的程度。这一概念在云计算时代被引入IT领域,成为应对分布式系统复杂性的关键手段。
可观测性三要素的起源
可观测性实践逐渐形成了所谓的“三大支柱”:日志(Logging)、指标(Metrics)和追踪(Tracing)。这一框架并非刻意设计的结果,而是技术演进的自然产物:
日志最早被用来记录离散事件,帮助开发人员了解程序执行过程
指标随着系统规模扩大而出现,用于量化系统状态和资源使用情况
追踪在分布式系统普及后成为必要,用于理解请求在复杂服务拓扑中的传播路径
下面通过一个简单的类比来说明这三者的关系:假设一个快递配送系统,日志相当于记录每个环节的详细操作(如“包裹已出库”),指标相当于统计配送成功率、平均时效等量化数据,而追踪则相当于快递单号,可以还原整个配送路径和各环节耗时。
随着微服务架构的普及,这三大要素不再孤立存在,而是相互关联,共同构成了可观测性的基础。接下来,我们将深入解析每项要素的技术原理与架构设计。
可观测性三要素技术解读:从数据收集到洞察分析
日志(Logging):事件记录的基石
日志是可观测性中最基础、最传统的组成部分,它记录了系统运行过程中发生的离散事件。每个日志条目通常包含时间戳、日志级别、事件描述以及上下文信息。
日志系统的架构演进
在微服务架构下,日志收集面临新的挑战:日志数据分散在各个节点,需要统一的收集、存储和分析方案。现代日志系统通常采用以下架构:

结构化日志的最佳实践
传统的非结构化日志(如纯文本)在微服务环境中难以有效分析。以下是结构化日志的示例:
// 非结构化日志示例(不推荐)
log.info("用户下单失败,原因:" + e.getMessage());
// 结构化日志示例(推荐)
import com.fasterxml.jackson.databind.ObjectMapper;
import java.util.Map;
public class StructuredLogger {
private static final ObjectMapper mapper = new ObjectMapper();
public void logOrderFailure(String userId, String orderId, Exception error) {
try {
Map logEntry = Map.of(
"timestamp", System.currentTimeMillis(),
"level", "ERROR",
"service", "order-service",
"event", "order_failure",
"user_id", userId,
"order_id", orderId,
"error_code", "STOCK_EMPTY",
"error_message", error.getMessage(),
"stack_trace", getStackTrace(error),
"trace_id", getCurrentTraceId() // 与链路追踪集成
);
// 输出JSON格式的结构化日志
log.info(mapper.writeValueAsString(logEntry));
} catch (Exception e) {
log.error("Failed to write structured log", e);
}
}
private String getStackTrace(Exception e) {
// 获取堆栈跟踪信息
StringBuilder sb = new StringBuilder();
for (StackTraceElement element : e.getStackTrace()) {
sb.append(element.toString()).append("\n");
}
return sb.toString();
}
private String getCurrentTraceId() {
// 从当前上下文获取Trace ID
return TracingContext.getCurrentTraceId();
}
} 日志收集的现代解决方案
ELK/EFK栈是目前最流行的日志解决方案:
Elasticsearch:分布式搜索和分析引擎,提供近实时的日志索引和查询能力
Logstash/Fluentd:日志收集、解析和传输工具,支持多种输入输出插件
Kibana:可视化平台,提供日志搜索、仪表盘和告警功能
日志系统的发展经历了从单机日志(如syslog)到集中式日志管理(如Splunk),再到云原生日志架构的演进过程,逐步解决了微服务环境下的日志管理挑战。
指标(Metrics):系统健康的量化衡量
指标是数值型的测量数据,表示系统在特定时间点的状态或性能情况。与日志不同,指标通常是聚合数据,占用空间小,查询速度快,非常适合实时监控和告警。
指标的类型与维度
在微服务监控中,指标通常分为以下几类:
计数器(Counter):单调递增的数值,如请求次数、错误数量
计量器(Gauge):可增可减的瞬时值,如内存使用量、活跃连接数
直方图(Histogram):观测值的分布情况,如请求延迟的百分位数
现代指标系统支持多维度标签,使数据可以按不同维度切片分析:
// 使用Micrometer注册自定义指标示例
import io.micrometer.core.instrument.Counter;
import io.micrometer.core.instrument.MeterRegistry;
import io.micrometer.core.instrument.Timer;
import java.util.concurrent.TimeUnit;
@Service
public class OrderMetrics {
private final Counter orderRequests;
private final Counter orderFailures;
private final Timer orderProcessingTime;
public OrderMetrics(MeterRegistry registry) {
// 创建订单请求计数器,包含服务名和版本标签
this.orderRequests = Counter.builder("order.requests")
.description("Total number of order requests")
.tag("service", "order-service")
.tag("version", "1.0.0")
.register(registry);
// 创建订单失败计数器
this.orderFailures = Counter.builder("order.failures")
.description("Number of failed orders")
.tag("service", "order-service")
.register(registry);
// 创建订单处理时间计时器
this.orderProcessingTime = Timer.builder("order.processing.time")
.description("Order processing time distribution")
.tag("service", "order-service")
.register(registry);
}
public void recordOrderSuccess(long processingTimeMs) {
orderRequests.increment();
orderProcessingTime.record(processingTimeMs, TimeUnit.MILLISECONDS);
}
public void recordOrderFailure(long processingTimeMs, String errorCode) {
orderRequests.increment();
orderFailures.increment();
orderProcessingTime.record(processingTimeMs, TimeUnit.MILLISECONDS);
// 可以按错误类型进一步细分
Counter.builder("order.failures.by.reason")
.tag("error_code", errorCode)
.register(meterRegistry)
.increment();
}
}指标收集与可视化架构
现代指标监控通常采用Prometheus + Grafana组合:
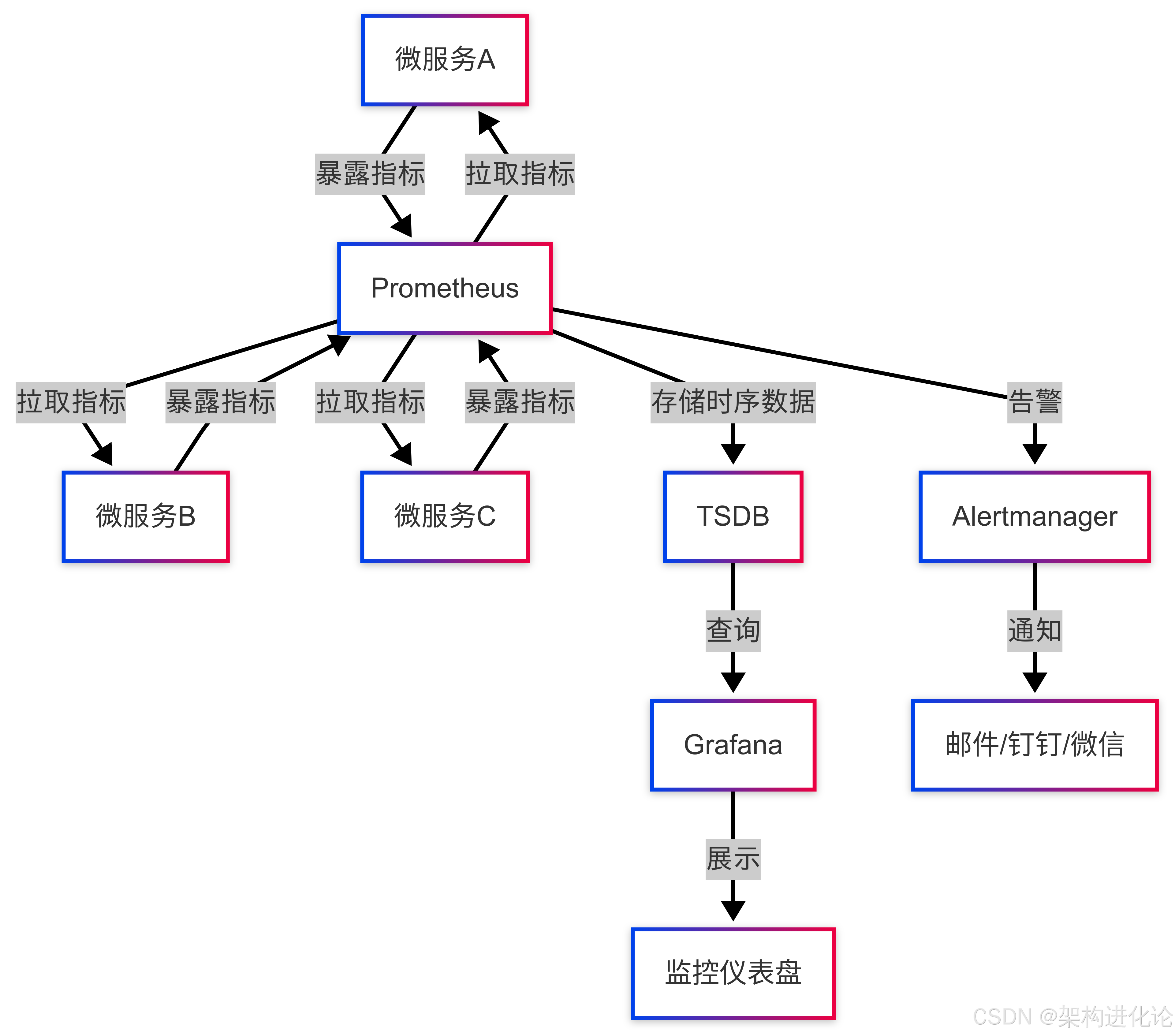
黄金指标与四大关键指标
Google SRE(Site Reliability Engineering)提出了四大黄金指标,用于衡量服务的健康状况:
延迟(Latency):处理请求所需的时间
流量(Traffic):系统负载的量化表示,如QPS(每秒查询数)
错误率(Errors):请求失败的比例
饱和度(Saturation):系统资源的使用程度,如CPU、内存使用率
这些指标为服务监控提供了标准化的视角,是构建可观测性体系的重要基础。
链路追踪(Tracing):分布式请求的全景视图
链路追踪记录了单个请求在分布式系统中流转的完整路径,包括经过的服务、每个服务的处理时间以及服务间的调用关系。它是微服务可观测性中最具挑战性也是最有价值的组成部分。
链路追踪的核心概念
Trace:代表一个完整的请求链路,从请求进入系统开始,到最终响应返回为止
Span:Trace中的单个操作单元,代表在一个服务中的处理过程
Span Context:在服务间传递的上下文信息,用于关联同一个Trace的所有Span
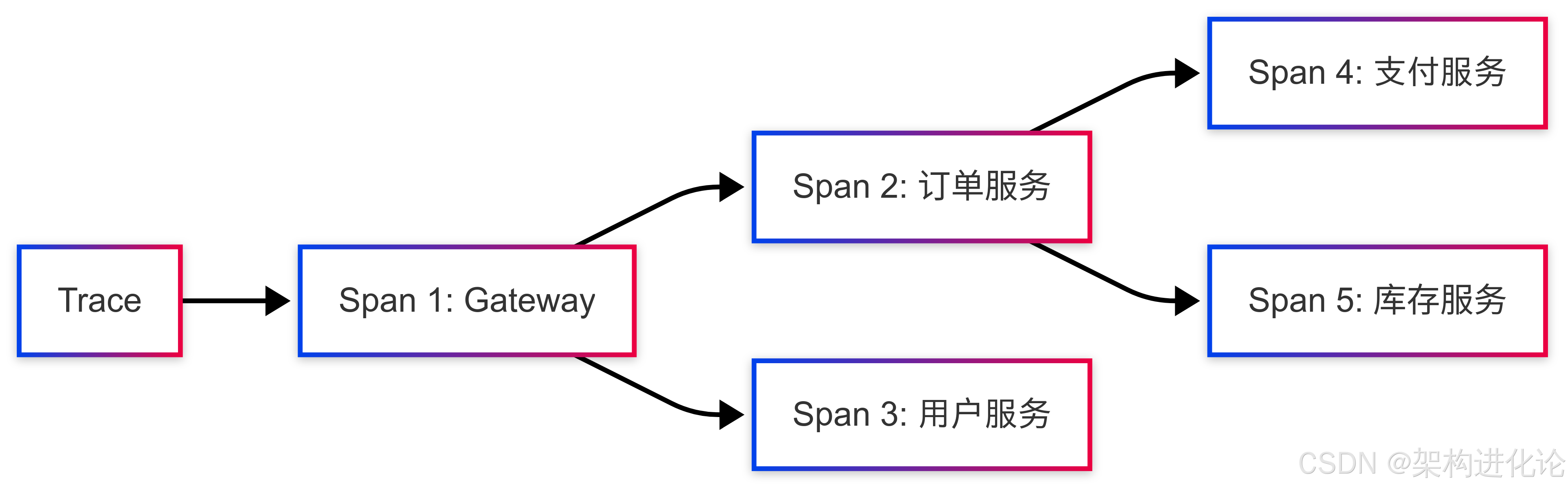
追踪数据的生成与传播
下面是一个简单的链路追踪实现示例,展示TraceID在服务间的传播:
// 1. 在网关层生成TraceID
@Component
public class TraceFilter implements GlobalFilter {
@Override
public Mono filter(ServerWebExchange exchange, GatewayFilterChain chain) {
String traceId = exchange.getRequest().getHeaders().getFirst("X-Trace-ID");
if (StringUtils.isEmpty(traceId)) {
// 生成唯一TraceID(雪花算法或UUID)
traceId = "trace-" + UUID.randomUUID().toString().substring(0, 8);
}
// 将TraceID放入请求头
ServerHttpRequest request = exchange.getRequest().mutate()
.header("X-Trace-ID", traceId)
.build();
// 将TraceID放入MDC,便于日志记录
MDC.put("traceId", traceId);
return chain.filter(exchange.mutate().request(request).build())
.doFinally(signal -> MDC.clear());
}
}
// 2. 在业务服务中传播TraceID
@RestController
public class OrderController {
@Autowired
private RestTemplate restTemplate;
@PostMapping("/orders")
public ResponseEntity createOrder(@RequestBody OrderRequest orderRequest) {
// 获取当前TraceID
String traceId = MDC.get("traceId");
// 记录开始时间
long startTime = System.currentTimeMillis();
try {
// 创建订单
Order order = orderService.create(orderRequest);
// 调用支付服务,传递TraceID
HttpHeaders headers = new HttpHeaders();
headers.set("X-Trace-ID", traceId);
HttpEntity entity = new HttpEntity<>(paymentRequest, headers);
ResponseEntity paymentResponse = restTemplate.postForEntity(
"http://payment-service/payments", entity, PaymentResponse.class);
// 记录成功日志
log.info("Order created successfully: {}", order.getId());
return ResponseEntity.ok(order);
} finally {
// 记录处理耗时
long duration = System.currentTimeMillis() - startTime;
Metrics.timer("order.create.duration").record(duration, TimeUnit.MILLISECONDS);
}
}
}
// 3. 异步上下文管理
@Component
public class TracingContext {
private static final ThreadLocal currentTraceId = new ThreadLocal<>();
public static String getCurrentTraceId() {
return currentTraceId.get();
}
public static void setTraceId(String traceId) {
currentTraceId.set(traceId);
}
public static void clear() {
currentTraceId.remove();
}
// 用于线程池间传递Trace上下文
public static Callable wrapWithTraceContext(Callable task) {
String traceId = getCurrentTraceId();
return () -> {
setTraceId(traceId);
try {
return task.call();
} finally {
clear();
}
};
}
} 主流追踪框架对比
目前主流的分布式追踪系统包括SkyWalking、Jaeger和Zipkin等:
| 特性 | SkyWalking | Jaeger | Zipkin |
|---|---|---|---|
| 数据存储 | Elasticsearch, MySQL | Cassandra, Elasticsearch | MySQL, Elasticsearch |
| 语言支持 | Java, .NET, Node.js等 | 多语言 | Java为主 |
| 部署方式 | 探针/Agent | 容器化 | 独立服务 |
| 性能影响 | 低 | 中等 | 中等 |
| 用户体验 | 优秀 | 良好 | 简单 |
在选择追踪系统时,需要考虑技术栈兼容性、性能开销、存储方案和运维成本等因素。
可观测性三要素的协同与融合:1+1+1>3的协同效应
虽然日志、指标和追踪各自具有独立价值,但真正的威力在于它们的有机结合。现代可观测性平台致力于打破三大支柱之间的隔阂,实现数据的关联分析。
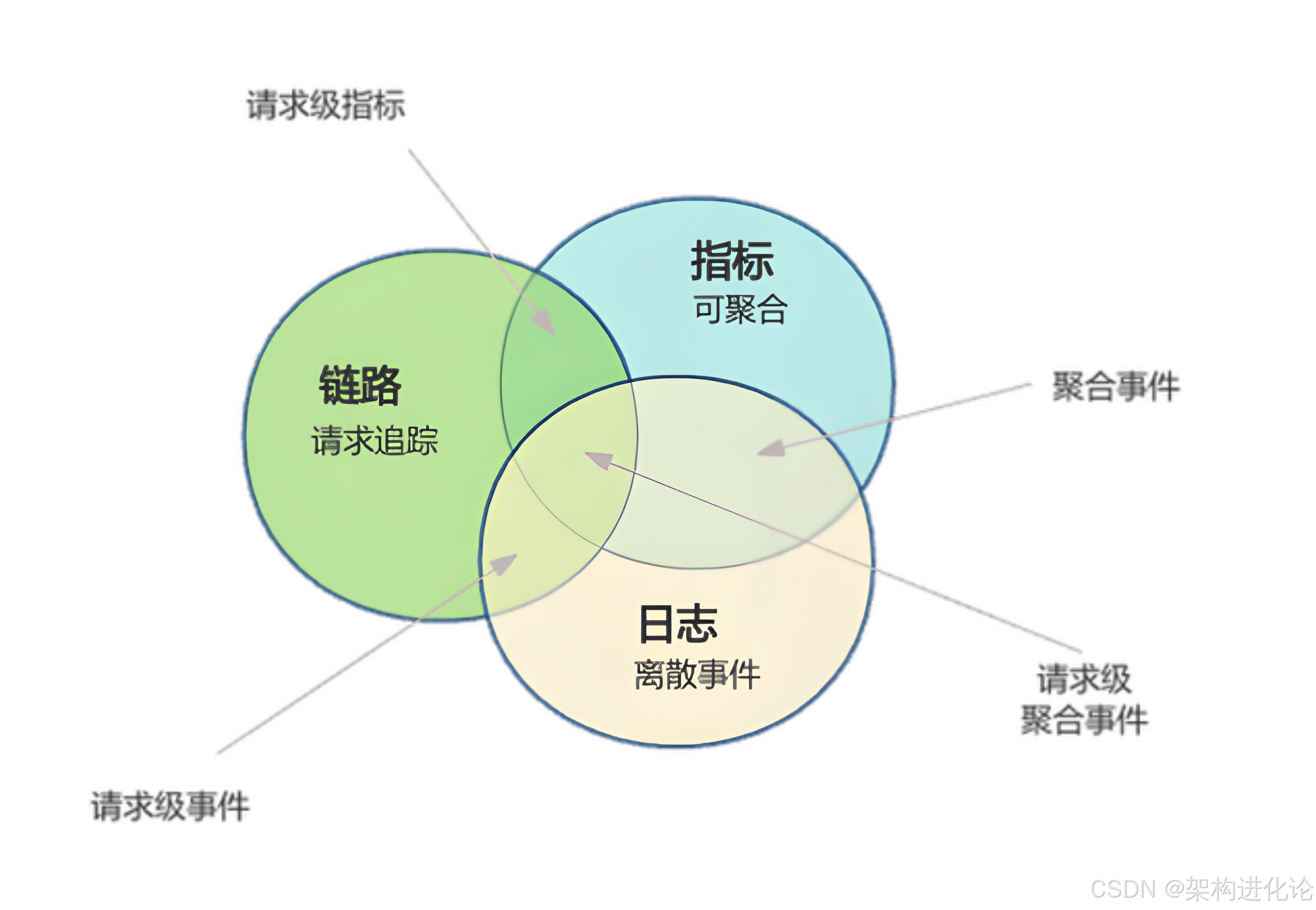
三者的内在联系与数据关联
日志、指标和追踪并非完全独立,而是存在密切的关联:
追踪 + 日志 = 请求级事件:通过TraceID将分散的日志关联到具体请求
指标 + 日志 = 聚合级事件:将指标异常与详细日志关联,深入分析根本原因
追踪 + 指标 = 请求级指标:从追踪数据中提取性能指标,如服务延迟、错误率
这三者的交集构成了完整的可观测性基础,使运维人员能够快速从现象(指标异常)定位到根源(具体代码问题)。
数据关联的实战案例
下面通过一个实际案例展示三大支柱如何协同工作:
// 1. 问题检测:通过指标发现异常
@RestController
public class HealthCheckController {
@GetMapping("/health/metrics")
public Map getMetrics() {
// 模拟从监控系统获取的关键指标
return Map.of(
"order.service.error_rate", "15%", // 错误率突增
"order.service.latency_p95", "850ms", // 95分位延迟升高
"timestamp", System.currentTimeMillis()
);
}
}
// 2. 根因分析:通过追踪定位问题范围
@Service
public class OrderAnalysisService {
public void analyzeSlowTraces() {
// 查询最近5分钟慢追踪
List slowTraces = traceQueryService.findSlowTraces(
"order-service",
Duration.ofMinutes(5),
1000 // 阈值:1000ms
);
// 分析慢追踪的共同特征
Map serviceCount = slowTraces.stream()
.flatMap(trace -> trace.getSpans().stream())
.filter(span -> span.getDuration() > 200)
.collect(Collectors.groupingBy(
span -> span.getServiceName() + ":" + span.getOperationName(),
Collectors.counting()
));
// 发现支付服务的"createPayment"操作频繁出现
serviceCount.entrySet().stream()
.sorted(Map.Entry.comparingByValue().reversed())
.limit(5)
.forEach(entry ->
log.info("Slow operation: {} ({} occurrences)",
entry.getKey(), entry.getValue()));
}
}
// 3. 详细调查:通过日志查明根本原因
@Service
public class PaymentService {
private static final Logger logger = LoggerFactory.getLogger(PaymentService.class);
public PaymentResult createPayment(PaymentRequest request) {
long startTime = System.currentTimeMillis();
String traceId = TracingContext.getCurrentTraceId();
try {
// 记录关键业务信息
logger.info("Creating payment for order: {}, amount: {}, traceId: {}",
request.getOrderId(), request.getAmount(), traceId);
// 模拟业务逻辑
if (request.getAmount().compareTo(BigDecimal.ZERO) <= 0) {
logger.warn("Invalid payment amount: {}, traceId: {}",
request.getAmount(), traceId);
throw new IllegalArgumentException("Invalid amount");
}
// 模拟数据库调用
Payment payment = savePayment(request);
logger.info("Payment created successfully: {}, traceId: {}",
payment.getId(), traceId);
return PaymentResult.success(payment.getId());
} catch (Exception e) {
logger.error("Payment failed for order: {}, traceId: {}, error: {}",
request.getOrderId(), traceId, e.getMessage(), e);
// 记录错误指标
Metrics.counter("payment.failures").increment();
return PaymentResult.failure(e.getMessage());
} finally {
long duration = System.currentTimeMillis() - startTime;
logger.debug("Payment processing time: {}ms, traceId: {}", duration, traceId);
Metrics.timer("payment.processing.time").record(duration, TimeUnit.MILLISECONDS);
}
}
} 统一可观测性平台架构
现代可观测性平台通过统一的数据模型和关联分析,实现三大支柱的深度融合:
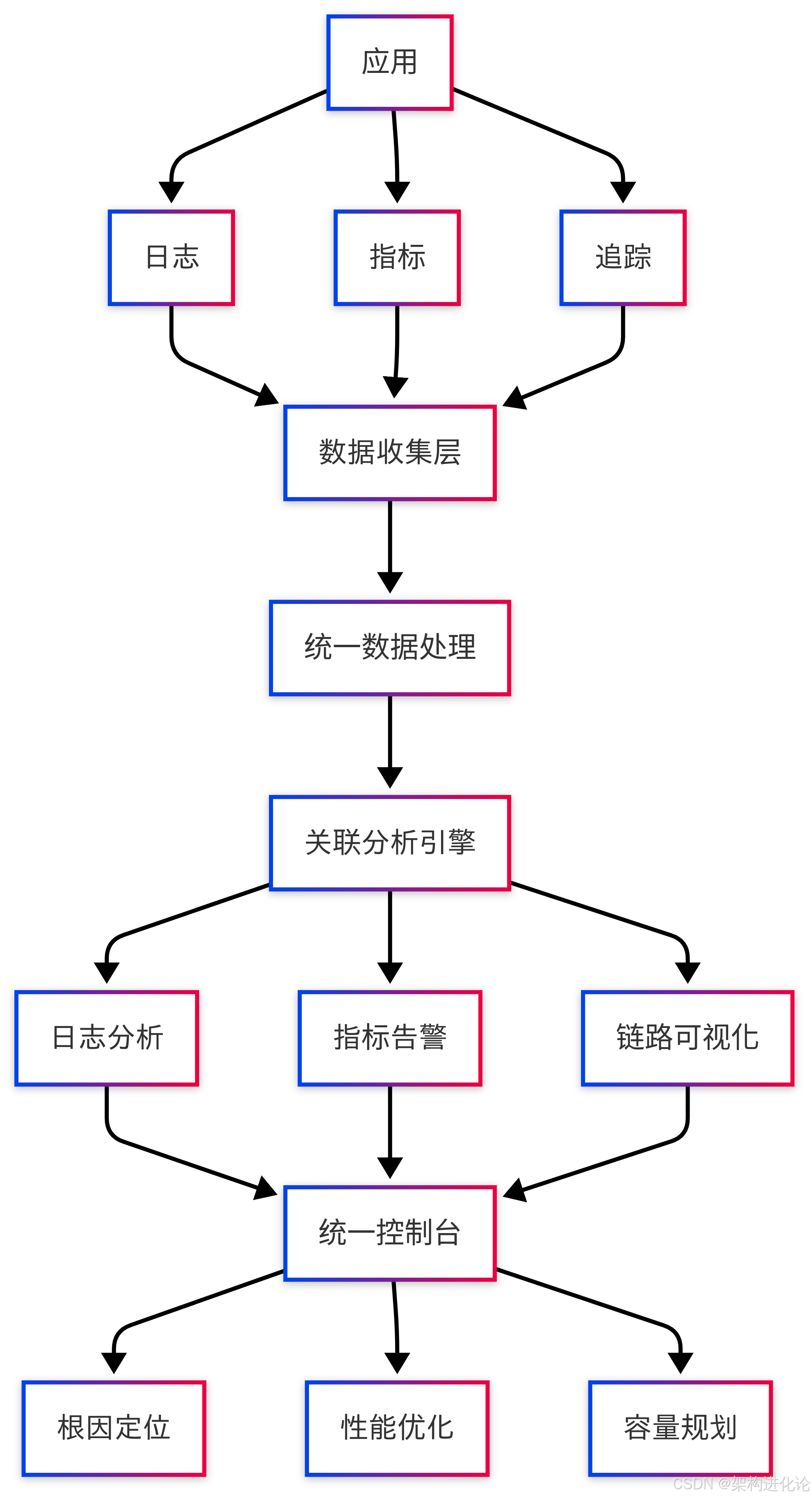
这种统一架构能够自动发现日志、指标和追踪之间的关联,大大缩短故障排查时间。例如,当指标系统检测到错误率上升时,运维人员可以立即查看相关服务的链路追踪,发现缓慢或失败的调用,然后通过关联的日志明细定位根本原因。
生活化案例:快递配送系统的可观测性类比
为了更直观地理解三要素的协同作用,我们可以用一个快递配送系统来类比:
指标相当于快递公司的KPI看板:准时率95%、破损率<0.1%、客户满意度4.8/5.0
追踪相当于每个包裹的物流轨迹:已发货→运输中→到达分拣中心→派送中→已签收
日志相当于每个环节的详细记录:包裹已扫描入库,装车完成,派送员张三领取包裹
当客户投诉包裹延迟时:
首先查看指标看板,发现整体准时率下降(指标)
然后查询该包裹的物流轨迹,发现卡在某个分拣中心(追踪)
最后查看该分拣中心的操作日志,发现因机器故障导致积压(日志)
这种类比可以帮助我们理解三要素在复杂系统中的不同角色和协同价值。
现代可观测性架构实践:从理论到生产环境
在微服务架构中实施可观测性需要全面的规划和技术选型。本节将介绍现代可观测性架构的实践要点。
云原生环境下的可观测性挑战
容器化和编排平台(如Kubernetes)为可观测性带来了新的挑战:
动态性:容器频繁创建销毁,传统基于静态IP的监控方式失效
短暂性:容器生命周期短,故障现场难以保留
密度高:单节点运行多个容器,资源竞争复杂
Kubernetes环境下的可观测性架构
# 可观测性组件在K8s中的部署示例
apiVersion: apps/v1
kind: Deployment
metadata:
name: observability-stack
spec:
replicas: 1
selector:
matchLabels:
app: observability
template:
metadata:
labels:
app: observability
spec:
containers:
- name: prometheus
image: prom/prometheus:latest
ports:
- containerPort: 9090
volumeMounts:
- mountPath: /etc/prometheus
name: prometheus-config
- name: grafana
image: grafana/grafana:latest
ports:
- containerPort: 3000
env:
- name: GF_SECURITY_ADMIN_PASSWORD
value: "admin"
- name: jaeger
image: jaegertracing/all-in-one:latest
ports:
- containerPort: 16686
- containerPort: 14268
env:
- name: COLLECTOR_ZIPKIN_HTTP_PORT
value: "9411"
volumes:
- name: prometheus-config
configMap:
name: prometheus-config
---
# 使用Sidecar模式收集日志
apiVersion: apps/v1
kind: Deployment
metadata:
name: order-service
spec:
replicas: 3
selector:
matchLabels:
app: order-service
template:
metadata:
labels:
app: order-service
spec:
containers:
- name: order-service
image: my-registry/order-service:latest
env:
- name: JAEGER_AGENT_HOST
value: "localhost"
- name: JAEGER_AGENT_PORT
value: "6831"
# 日志收集Sidecar
- name: log-collector
image: fluent/fluentd:latest
volumeMounts:
- mountPath: /var/log
name: app-logs
resources:
requests:
memory: "64Mi"
cpu: "50m"
limits:
memory: "128Mi"
cpu: "100m"
volumes:
- name: app-logs
emptyDir: {}可观测性实施策略与最佳实践
渐进式实施策略
构建可观测性体系应采取渐进式策略:
基础监控:先确保关键业务指标和错误日志的收集
链路追踪:在核心业务流程实施分布式追踪
高级分析:引入机器学习、异常检测等高级功能
数据采样与存储优化
全量收集所有可观测性数据成本高昂,需要合理的采样策略:
/**
* 智能采样策略示例
* 根据请求特征决定采样率,重要请求100%采样,普通请求按比例采样
*/
@Component
public class IntelligentSampler {
// 重要用户列表(高价值客户)
private Set importantUsers = Set.of("user123", "user456", "user789");
// 关键业务操作
private Set criticalOperations = Set.of("createOrder", "processPayment", "updateInventory");
public boolean shouldSample(String userId, String operation, String traceId) {
// 重要用户的操作100%采样
if (importantUsers.contains(userId)) {
return true;
}
// 关键业务操作100%采样
if (criticalOperations.contains(operation)) {
return true;
}
// 异常请求100%采样
if (isErrorTrace(traceId)) {
return true;
}
// 普通请求按1%比例采样
return ThreadLocalRandom.current().nextDouble() < 0.01;
}
private boolean isErrorTrace(String traceId) {
// 检查该Trace是否包含错误
// 实现逻辑根据具体技术栈而定
return false;
}
}
/**
* 可观测性数据生命周期管理
*/
@Service
public class ObservabilityDataManager {
// 热数据保留时间(高查询频率)
private static final Duration HOT_DATA_RETENTION = Duration.ofDays(7);
// 温数据保留时间
private static final Duration WARM_DATA_RETENTION = Duration.ofDays(30);
// 冷数据保留时间(低查询频率)
private static final Duration COLD_DATA_RETENTION = Duration.ofDays(365);
public void manageDataLifecycle() {
// 移动热数据到温存储
moveHotToWarm(HOT_DATA_RETENTION);
// 移动温数据到冷存储
moveWarmToCold(WARM_DATA_RETENTION);
// 归档或删除过期数据
cleanupExpiredData(COLD_DATA_RETENTION);
}
private void moveHotToWarm(Duration retention) {
// 实现数据迁移逻辑
// 例如从Elasticsearch热节点迁移到温节点
}
private void moveWarmToCold(Duration retention) {
// 实现数据迁移逻辑
// 例如从Elasticsearch迁移到对象存储(如S3)
}
private void cleanupExpiredData(Duration retention) {
// 清理过期数据
}
} 可观测性治理与规范
为确保可观测性体系的有效性,需要建立相应的治理规范:
日志规范
定义统一的日志格式(JSON结构化日志)
制定日志级别使用指南(DEBUG、INFO、WARN、ERROR)
规范敏感信息过滤规则
指标规范
统一的命名约定(如
service.operation.result)标签/维度定义标准
指标收集频率和聚合方式
追踪规范
服务间上下文传播协议
采样率配置标准
跨语言追踪SDK兼容性要求
可观测性成熟度模型
企业可观测性实践可以分为不同成熟度等级:
| 等级 | 特征 | 关键能力 |
|---|---|---|
| 初始级 | 基本监控 | 服务器指标、错误日志 |
| 可重复级 | 标准化监控 | 统一日志格式、业务指标收集 |
| 已定义级 | 全面可观测 | 分布式追踪、关联分析 |
| 已管理级 | 预测性分析 | AI异常检测、自动根因分析 |
| 优化级 | 业务可观测 | 业务指标驱动、主动优化 |
通过评估当前成熟度等级,企业可以制定合理的可观测性演进路线图。
总结与展望:可观测性的未来发展趋势
微服务架构下的可观测性已从“奢侈品”变为“必需品”。随着系统复杂性的不断增加,良好的可观测性能力已成为企业技术竞争力的关键组成部分。
技术演进趋势
可观测性领域仍在快速发展,主要趋势包括:
OpenTelemetry的崛起:作为CNCF(云原生计算基金会)的毕业项目,OpenTelemetry正成为可观测性数据收集的标准
eBPF技术的应用:无需代码修改即可实现网络、性能观测
AI驱动的可观测性:通过机器学习自动检测异常、定位根因
边缘计算可观测性:适应边缘计算场景的特殊挑战
可观测性即代码:通过声明式配置管理可观测性组件
架构师的关键考量
作为架构师,在设计和实施可观测性体系时,需要平衡多个考量因素:
成本与收益:在数据收集详细度和系统开销间取得平衡
实时性与准确性:根据业务需求确定数据处理的延迟要求
灵活性与标准化:在统一标准和特殊需求间找到平衡点
短期需求与长期演进:设计能够适应未来变化的可观测性架构
结语
可观测性不是单一工具或技术的堆砌,而是一种系统性的能力和文化。它要求开发、运维和业务团队紧密协作,共同构建对系统行为的深入理解。通过有效实施可观测性三要素——日志、指标和追踪,企业能够真正驾驭微服务架构的复杂性,实现快速故障恢复、性能优化和持续改进。
在微服务架构成为主流的今天,可观测性已不再是可选项,而是确保系统稳定性、可靠性和性能的基础设施。正如控制论创始人诺伯特·维纳所言:“我们不仅需要控制系统的能力,更需要理解系统行为的能力。”可观测性正是赋予我们这种理解能力的关键所在。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号