python爬虫
一、正则表达式
1.1 正则模块
需要模块re
>>> import re
>>> print(dir(re))
['A', 'ASCII', 'DEBUG', 'DOTALL', 'I', 'IGNORECASE', 'L', 'LOCALE', 'M', 'MULTILINE', 'Match', 'NOFLAG', 'Pattern', 'RegexFlag', 'S', 'Scanner', 'T', 'TEMPLATE', 'U', 'UNICODE', 'VERBOSE', 'X', '_MAXCACHE', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '__version__', '_cache', '_casefix', '_compile', '_compile_repl', '_compiler', '_constants', '_expand', '_parser', '_pickle', '_special_chars_map', '_subx', 'compile', 'copyreg', 'enum', 'error', 'escape', 'findall', 'finditer', 'fullmatch', 'functools', 'match', 'purge', 'search', 'split', 'sub', 'subn', 'template']
re.findall("正则表达式","被处理字符串")
#返回值是符合正则表达式的集合[]
1.2 单个字符匹配
-
.匹配单个字符 -
[]逐一匹配中括号中的单个字符- 中括号内的
^表示取反 - 括号外的
^表示该单词必须是句子开头
- 中括号内的
-
\d匹配单个数字 0-9 -
\w匹配单个字母、数字、下划线 -
\s匹配空白字符(空格、\n、\t、\r)
1.3 字符串匹配
1.3.1 固定字符串匹配
re.findall("固定匹配的字符串","被处理的字符串")
1.3.2 多个字符串匹配
|
re.findall("字符串1|字符串2|字符串3","被处理的字符串")
1.3.3 可以存在字符
*左邻字符可以存在(出现0次到无穷次)
re.findall("ab*c","被处理字符串")
#ac、abc、abbc、abbbc...
.*可能出现贪婪匹配,配合?时.*?可以去贪婪
1.3.4 必须存在字符
+左邻字符必须存在(出现1次到无穷次)
re.findall("ab+c","被处理字符串")
#abc、abbc、abbbc、abbbbc...
.+可能出现贪婪匹配,配合?时.+?可以去贪婪
1.3.5 不存在或只存在一个
?左邻字符不存在或只存在一个(出现0或1次)
re.findall("ab?c","被处理字符串")
#ac、abc
1.3.6 指定存在个数
{}指定左邻字符存在的个数
re.findall("ab{2}c","被处理字符串")
#abbc
re.findall("ab{3,5}","被处理字符串")
#abbbc、abbbbbc
二、web页面数据获取
IE:
- 输入网址-->浏览器构造一个页面请求request-->请求送到服务器
- 服务器回应一个响应(响应信息、服务器信息、html源码)-->浏览器提取html源码-->对源码进行渲染展示
python:
- 伪装成浏览器构造请求,发送请求到服务器,申请页面信息
- 服务器回应一个响应(响应信息、服务器信息、html源码)-->python提取html源码-->对源码进行查看分析
2.1 获取数据
#!/usr/bin/python3
import urllib.request as r
url = "http://47.100.*.*/test/"
#包含响应头和源码
response = r.urlopen(url)
#提取出源码
html = response.read()
#b'字节串' 的形式,中文会以十六进制的形式显示其字节值
print(html)
#解码为字符串形式
print(str(html,encoding="utf8"))
2.2 伪造web请求头
2.2.1 添加UA
直接用python请求页面资源能被辨别出来,因为请求头中的UA和普通浏览器不一样
所以在发送请求头之前,先添加UA信息
#!/usr/bin/python3
import urllib.request as r
url = "http://47.100.*.*/test/"
#构造对url的请求头
request = r.Request(url)
#修改请求头,添加值
request.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0")
#将请求头传到urlopen中发送给服务器
response = r.urlopen(request)
#提取出源码
html = response.read()
#解码为字符串形式
print(str(html,encoding="utf8"))
2.2.2 添加cookie
获取cookie:
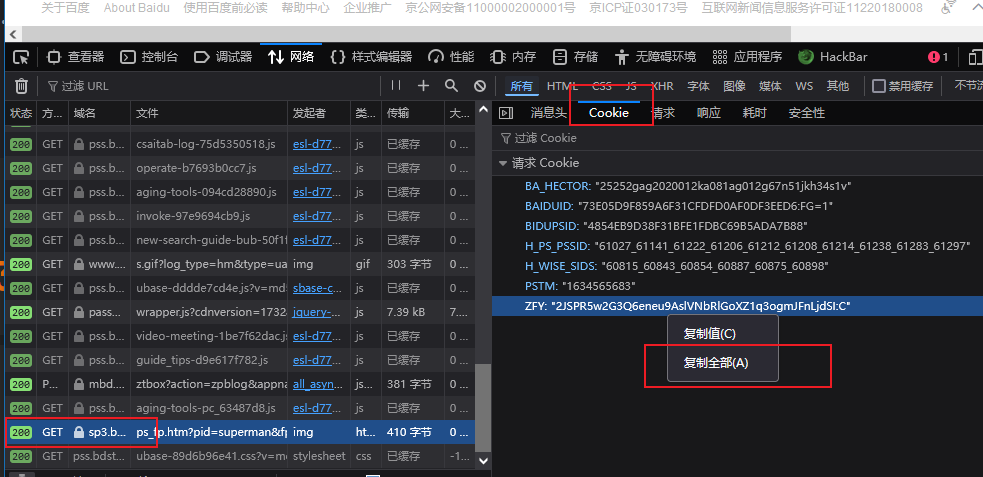
- 使用火狐浏览器打开网站(登录)
- f12进入调试台-->网络-->开始性能分析

- 随便点击一个200的请求-->Cookie-->右键复制全部
2.3 获取web数据改造成函数
#!/usr/bin/python3
import urllib.request as r
def getWebData(url):
"给出页面地址,返回页面html字符串"
#构造对url的请求头
request = r.Request(url)
#修改请求头,添加值
request.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0")
#将请求头传到urlopen中发送给服务器
response = r.urlopen(request)
#提取出源码
html = response.read()
#解码为字符串形式
return str(html,encoding="utf8")
if __name__ == "__main__":
print(getWebData("http://47.100.*.*/test/"))
三、爬取图片
3.1 爬取指定图片
#!/usr/bin/python3
import urllib.request as r
"""
爬虫相关代码
"""
def get_data(url):
"给出url地址,返回html数据"
#构造对url的请求头
request = r.Request(url)
#修改请求头,添加值
request.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0")
#将请求头传到urlopen中发送给服务器
response = r.urlopen(request)
#返回提取出的源码
return response.read()
def download_image(image_url):
"给出图片地址,下载图片到image目录下"
#获取图片源码
image_code = get_data(image_url)
#打开目标路径文件,并在内存中开辟空间,w写模式,b字节编码
with open("image/1.jpg","wb") as f:
f.write(image_code)
if __name__ == "__main__":
download_image("http://47.100.174.86/test/style/u18825255304088225336fm170sC213CF281D23248E7ED6550F0100A0E1w.jpg")
3.2 爬取多个图片
#!/usr/bin/python3
import urllib.request as r
import re
"""
爬虫相关代码
"""
def get_data(url):
"给出url地址,返回资源"
#构造对url的请求头
request = r.Request(url)
#修改请求头,添加值
request.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0")
#将请求头传到urlopen中发送给服务器
response = r.urlopen(request)
#返回提取出的源码
html = response.read()
return html
def download_image(url):
"给出页面url,批量下载图片到image目录下"
image_list=get_imagelist(url)
num = 1
for i in image_list:
#获取图片源码
image_code = get_data(i)
#打开目标路径文件,并在内存中开辟空间,w写模式,b字节编码
#{num:04}表示此数字如果不足四位,则用0填充
with open(f"image/{num:04}.jpg","wb") as f:
f.write(image_code)
num+=1
def get_imagelist(url):
"给出页面url,过滤出图片url列表"
#获取html源码字符串
html = str(get_data(url),encoding="utf8")
#提取图片url
half_imagelist = re.findall("style/\w{60}\.jpg",html)
image_list=[]
for i in half_imagelist:
image_list.append(url + "/" + i)
return image_list
if __name__ == "__main__":
download_image("http://47.100.*.*/test/")
3.3 实例
爬取漫漫漫画中的图片
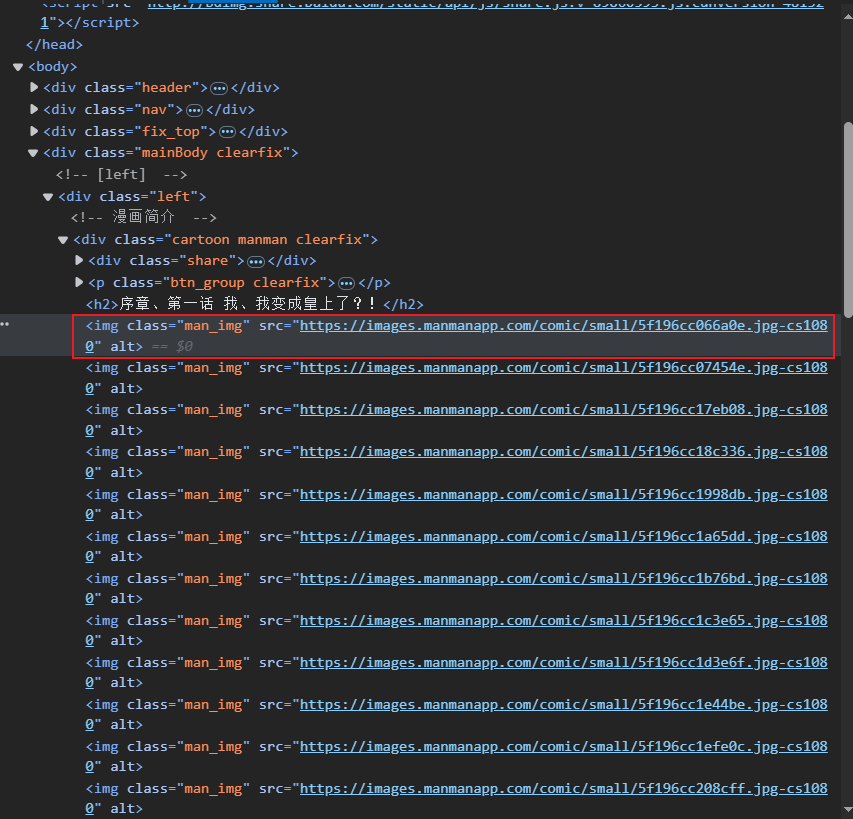
随便打开一页漫画,f12查看目标图片url,分析规律:
https://images.manmanapp.com/comic/small/开头- 13个数字或字母
.jpg结尾
-->正则表达式: https://images.manmanapp.com/comic/small/\w{13}\.jpg
#!/usr/bin/python3
import urllib.request as r
import re
"""
爬取manman图片
"""
def get_data(url):
"给出url地址,返回资源"
#构造对url的请求头
request = r.Request(url)
#修改请求头,添加值
request.add_header("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0")
#将请求头传到urlopen中发送给服务器
response = r.urlopen(request)
#返回提取出的源码
html = response.read()
return html
def download_image(url):
"给出页面url,批量下载图片到image目录下"
image_list=get_imagelist(url)
num = 1
for i in image_list:
#获取图片源码
image_code = get_data(i)
#打开目标路径文件,并在内存中开辟空间,w写模式,b字节编码
#{num:04}表示此数字如果不足四位,则用0填充
with open(f"image/{num:04}.jpg","wb") as f:
f.write(image_code)
num+=1
def get_imagelist(url):
"给出页面url,过滤出图片url列表"
#获取html源码字符串
html = str(get_data(url),encoding="utf8")
#提取图片url
image_list = re.findall("https://images.manmanapp.com/comic/small/\w{13}\.jpg",html)
return image_list
if __name__ == "__main__":
download_image("https://manmanapp.com/comic/detail-1405576.html")
四、爬取文字
以豆瓣读书 Top 250为例
4.1 使用模块
4.1.1 requests模块
- 自动解码(utf8)
- 更简单的访问https网站
- 比起
urllib.request代码简练
#!/usr/bin/python3
import requests
def get_html(url):
"""
给出url地址,返回html字符串
"""
ua={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0"}
#添加伪装ua
response = requests.get(url,headers=ua)
#如果页面不是utf8编码格式
#response.encoding = "gbk"
#返回源码,默认utf8解码
return response.text
if __name__ == "__main__":
print(get_html("https://book.douban.com/top250"))

4.1.2 bs4模块
beautiful soup
识别所有html标签,并且提取指定标签中的文字
import bs4
def get_html(url):
"""
给出url地址,返回html字符串
"""
ua={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0"}
#添加伪装ua
response = requests.get(url,headers=ua)
#如果页面不是utf8编码格式
#response.encoding = "gbk"
#返回源码,默认utf8解码
return response.text
def get_text(url):
"""
根据url,获得该界面html中指定标签中的内容
"""
#得到html字符串
html = get_html(url)
#得到bs4分析html的结果(固定写法)
result = bs4.BeautifulSoup(html,"html.parser")
bookname = result.find("span") #查找第一个span标签,返回值是一个标签
booknames = result.findAll("sapn") #查找所有span标签,返回值是一个列表
booknamePlus = result.find("span",property="v:itemreviewed") #基于标签属性精确查找标签
#标签.text为标签的内容
return booknamePlus.text
if __name__ == "__main__":
print(get_text("https://book.douban.com/subject/1007305/"))

4.1.3 openpyxl
建立excel表格
#!/usr/bin/python3
import requests
import bs4
import openpyxl
def get_html(url):
"""
给出url地址,返回html字符串
"""
ua={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0"}
# 添加伪装ua
response = requests.get(url,headers=ua)
# 如果页面不是utf8编码格式
#response.encoding = "gbk"
# 返回源码,默认utf8解码
return response.text
def get_text(url):
"""
根据url,获得该界面html中指定标签中的内容
"""
# 得到html字符串
html = get_html(url)
# 得到bs4分析html的结果(固定写法)
result = bs4.BeautifulSoup(html,"html.parser")
bookname = result.find("span") #查找第一个span标签,返回值是一个标签
booknames = result.findAll("sapn") #查找所有span标签,返回值是一个列表
booknamePlus = result.find("span",property="v:itemreviewed") #基于标签属性精确查找标签
#标签.text为标签的内容
return booknamePlus.text
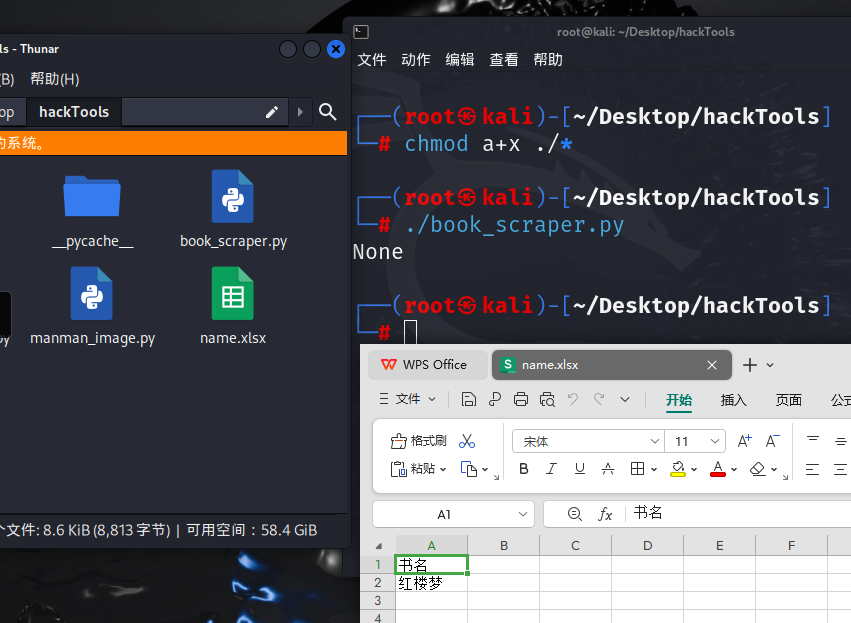
def save_text(url):
"""
根据url,爬取指定内容并保存到表格文件中
"""
# 创建表格工作薄
wb = openpyxl.Workbook()
# 创建新的工作表
ws = wb.active
title = ['书名']
name = [get_text(url)]
# 将标题添加到表格中
ws.append(title)
# 添加内容
ws.append(name)
# 保存工作簿
wb.save("name.xlsx")
if __name__ == "__main__":
print(save_text("https://book.douban.com/subject/1007305/"))
4.2 爬取单书指定信息
#!/usr/bin/python3
import requests
import bs4
import openpyxl
def get_html(url):
""""
给出url地址,返回该页面的html字符串
"""
ua={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0"}
# 添加伪装ua
response = requests.get(url,headers=ua)
# 如果页面不是utf8编码格式
#response.encoding = "gbk"
# 返回源码,默认utf8解码
return response.text
def get_bookinfo(url):
"""
根据url,获得指定标签中的内容
"""
# 得到html字符串
html = get_html(url)
# 得到bs4分析html的结果(固定写法)
result = bs4.BeautifulSoup(html,"html.parser")
book_info = []
#获取书名
book_name = result.find("span",property="v:itemreviewed").text
book_info.append(book_name)
#获取评分
book_score = result.find("strong").text
book_info.append(book_score)
#获取作者
auther_list1 = result.find("div",id="info")
auther_list2 = auther_list1.span.findAll("a") #author_list2 是标签列表
# 循环列表 取出内容
authers = ""
for i in auther_list2:
authers += i.text + " "
book_info.append(authers)
#获取简介(和python冲突时后跟_)
book_intro = result.find("div",class_="intro").text
book_info.append(book_intro)
return book_info
def save_text(url):
"""
根据url,爬取制定内容并保存到表格文件中
"""
# 创建表格工作薄
wb = openpyxl.Workbook()
# 创建新的工作表
ws = wb.active
title = ['书名','评分','作者','简介']
book_info = get_bookinfo(url)
# 将标题添加到表格中
ws.append(title)
# 添加内容
ws.append(book_info)
# 保存工作簿
wb.save("HongLou.xlsx")
if __name__ == "__main__":
print(save_text("https://book.douban.com/subject/1007305/"))

4.3 爬取一页书的指定信息
#!/usr/bin/python3
import requests
import bs4
import openpyxl
import re
def get_html(url):
"""
给出界面url地址,返回该界面html字符串
"""
ua={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0"}
cookie = {
"__utma": "30149280.958469161.1732803923.1732803923.1732803923.1",
"__utmb": "30149280.2.10.1732803923",
"__utmc": "30149280",
"__utmt_douban": "1",
"__utmz": "30149280.1732803923.1.1.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/",
"_vwo_uuid_v2": "D95FBF3DE1027E0C7291984816C404FC9|449a2f19af572a9a98ce8c0d99731e33",
"bid": "STsFIybspvY",
"ck": "vX1D",
"dbcl2": "\"285096155:KQFpfMu2500\"",
"frodotk_db": "\"c13c9a6f014cb34743b5cf4d03e619d5\"",
"push_doumail_num": "0",
"push_noty_num": "0"
}
# 添加伪装ua和cookie
response = requests.get(url,headers=ua,cookies=cookie)
# 如果页面不是utf8编码格式
#response.encoding = "gbk"
# 返回源码,默认utf8解码
return response.text
def get_bookinfo(url):
"""
根据书的详情界面url,获得该书信息
"""
# 得到html字符串
html = get_html(url)
# 得到bs4分析html的结果(固定写法)
result = bs4.BeautifulSoup(html,"html.parser")
book_info = []
#获取书名
book_name = result.find("span",property="v:itemreviewed").text
book_info.append(book_name)
#获取评分
book_score = result.find("strong").text
book_info.append(book_score)
#获取作者
auther_list1 = result.find("div",id="info")
auther_list2 = auther_list1.span.findAll("a") #author_list2 是标签列表
# 循环列表 取出内容
authers = ""
for i in auther_list2:
authers += i.text + " "
book_info.append(authers)
#获取简介(和python冲突时后跟_)
book_intro = result.find("div",class_="intro").text
book_info.append(book_intro)
#标签.text为标签的内容
return book_info
def get_books_urls (url):
"""
根据书籍列表url,返回该页面的书籍url列表
"""
#获得书籍列表界面的html字符串
html = get_html(url)
#筛出每本书的详情界面url
books = re.findall("https://book.douban.com/subject/\d{7,8}/",html)
#去重
books_urls = []
for i in books:
if i not in books_urls :
books_urls.append(i)
return books_urls
def save_books(url):
"""
根据书籍列表url,将所有该页面的书籍信息保存到表格中
"""
#获取该页面书籍url列表
books_url = get_books_urls(url)
# 创建表格工作薄
wb = openpyxl.Workbook()
# 创建新的工作表
ws = wb.active
ws.append(['书名','评分','作者','简介'])
#循环保存书籍信息到工作表中
for i in books_url:
ws.append(get_bookinfo(i))
wb.save("25books.xlsx")
if __name__ == "__main__":
save_books("https://book.douban.com/top250")

4.4 爬取所有页面书的指定信息
有的书的详情界面不按套路出牌:

捕获异常解决
如果没有加cookie,调试的次数多了会被网站要求登陆,加上cookie即可。
#!/usr/bin/python3
import requests
import bs4
import openpyxl
import re
def get_html(url):
"""
给出界面url地址,返回该界面html字符串
"""
ua={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0"}
cookie = {
"__utma": "30149280.958469161.1732803923.1732803923.1732803923.1",
"__utmb": "30149280.2.10.1732803923",
"__utmc": "30149280",
"__utmt_douban": "1",
"__utmz": "30149280.1732803923.1.1.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/",
"_vwo_uuid_v2": "D95FBF3DE1027E0C7291984816C404FC9|449a2f19af572a9a98ce8c0d99731e33",
"bid": "STsFIybspvY",
"ck": "vX1D",
"dbcl2": "\"285096155:KQFpfMu2500\"",
"frodotk_db": "\"c13c9a6f014cb34743b5cf4d03e619d5\"",
"push_doumail_num": "0",
"push_noty_num": "0"
}
# 添加伪装ua和cookie
response = requests.get(url,headers=ua,cookies=cookie)
# 如果页面不是utf8编码格式
#response.encoding = "gbk"
# 返回源码,默认utf8解码
return response.text
def get_bookinfo(url):
"""
根据书的详情界面url,获得该书信息
"""
# 得到html字符串
html = get_html(url)
# 得到bs4分析html的结果(固定写法)
result = bs4.BeautifulSoup(html,"html.parser")
book_info = []
#获取书名
book_name = result.find("span",property="v:itemreviewed").text
book_info.append(book_name)
#获取评分
book_score = result.find("strong").text
book_info.append(book_score)
#获取作者
auther_list1 = result.find("div",id="info")
auther_list2 = auther_list1.span.findAll("a") #author_list2 是标签列表
# 循环列表 取出内容
authers = ""
for i in auther_list2:
authers += i.text + " "
book_info.append(authers)
#获取简介(和python冲突时后跟_)
book_intro = result.find("div",class_="intro").text
book_info.append(book_intro)
#标签.text为标签的内容
return book_info
def get_books_urls (url):
"""
根据书籍列表页面的url,返回该页面的书籍url列表
"""
#获得书籍列表界面的html字符串
html = get_html(url)
#筛出每本书的详情界面url
books = re.findall("https://book.douban.com/subject/\d{7,8}/",html)
#去重
books_urls = []
for i in books:
if i not in books_urls :
books_urls.append(i)
return books_urls
def save_books(url):
"""
根据书籍列表的第一页的url,将所有页面的书籍信息保存到表格中
"""
# 创建表格工作薄
wb = openpyxl.Workbook()
# 创建新的工作表
ws = wb.active
ws.append(['书名', '评分', '作者', '简介'])
#一页一页的进行保存
i,num=0,
while i < 250:
#获取当前书籍列表页面url
books25_url = f"{url}?start={i}"
#获取该页面书籍url列表
books_urls = get_books_urls(books25_url)
#循环保存书籍信息到工作表中
for book_url in books_urls:
try:
ws.append(get_bookinfo(book_url))
except:
num+=1
continue
i+=25
wb.save("250books.xlsx")
print(f"保存完毕!其中有{num}本书发生了未知错误!")
if __name__ == "__main__":
save_books("https://book.douban.com/top250")


 浙公网安备 33010602011771号
浙公网安备 33010602011771号