
爬取B站的文章并存入csv表
前言:
对于一个网站的图片、文字音视频等,如果我们一个个的下载,不仅浪费时间,而且很容易出错。Python爬虫帮助我们获取需要的数据,这个数据是可以快速批量的获取。
工具使用:
开发工具: Visual Studio
开发环境:python-3.9.7-amd64, Windows10
使用工具包:
import requests from lxml import etree import os # 下载进度条 from tqdm import tqdm import csv
项目思路解析:
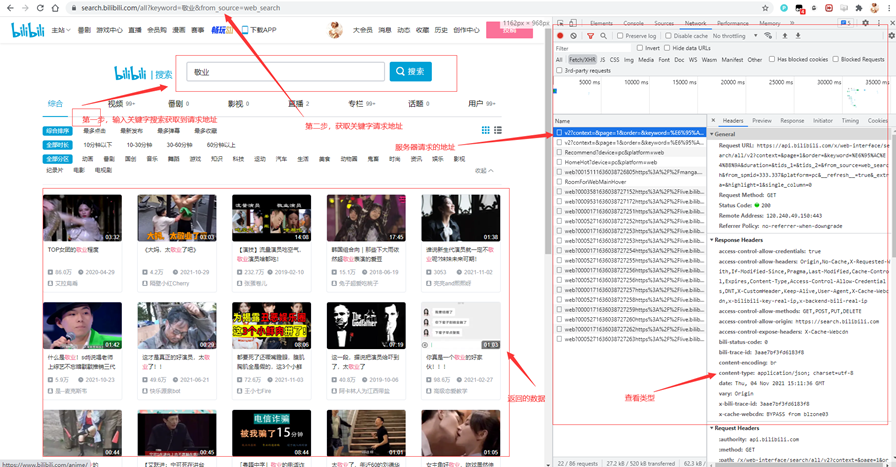
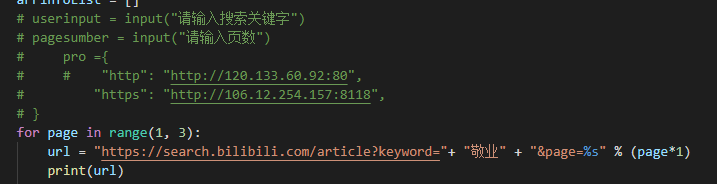
这里拿到请求地址https://search.bilibili.com/article?keyword=敬业&page=1,然后定位自己需要的元素
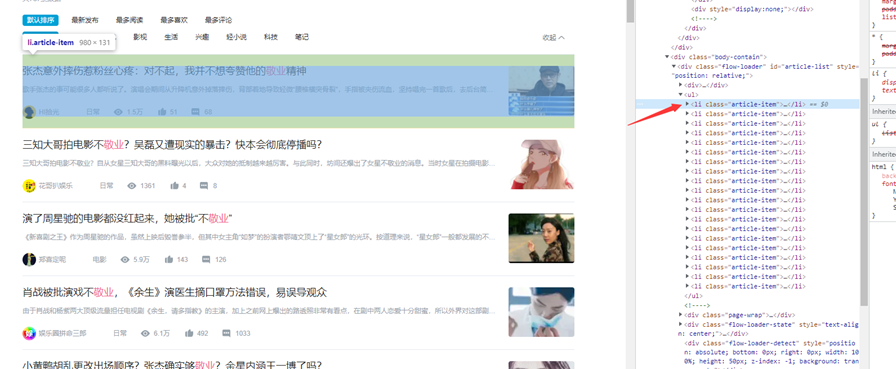
Li标签里面就是我们需要的数据,然后我们定位到关键词里标题,最后以此类推元素的代码位置。
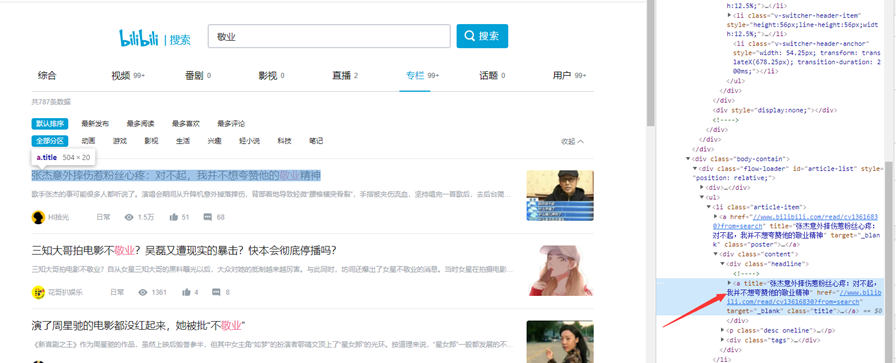
代码如下:
这里的关键字可以后期代码输入,不用写死数据,便于不用频繁的修改代码。

还有这里的页数,也是可以用代码进行抓完全部网页数据,这里为了演示就把数据写死了,只爬取两页数据。
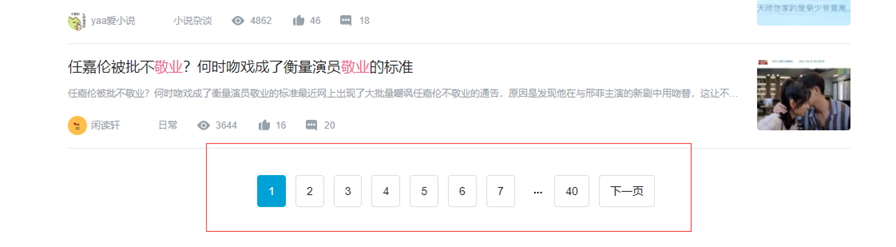
以下是元素(例如:标题,热度的数据)定位的代码
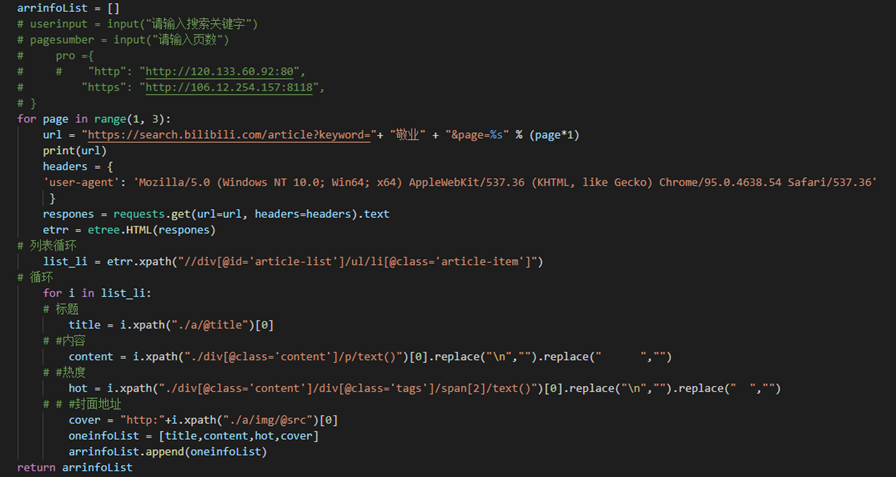
这里的replace是为了清除不需要的数据,方便于后面的数据分析。
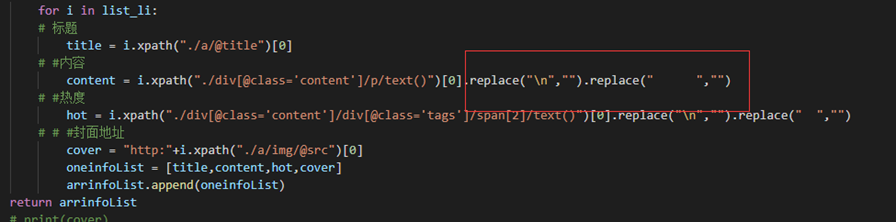
拿完数据,我们就要把数据进行存储化,存入csv表。
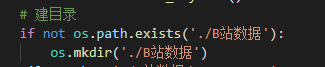
这里是建立一个文件夹,用于存放csv表
Csv存入的地址的名字

书写csv的表头

意思是csv的表头

项目完整代码:
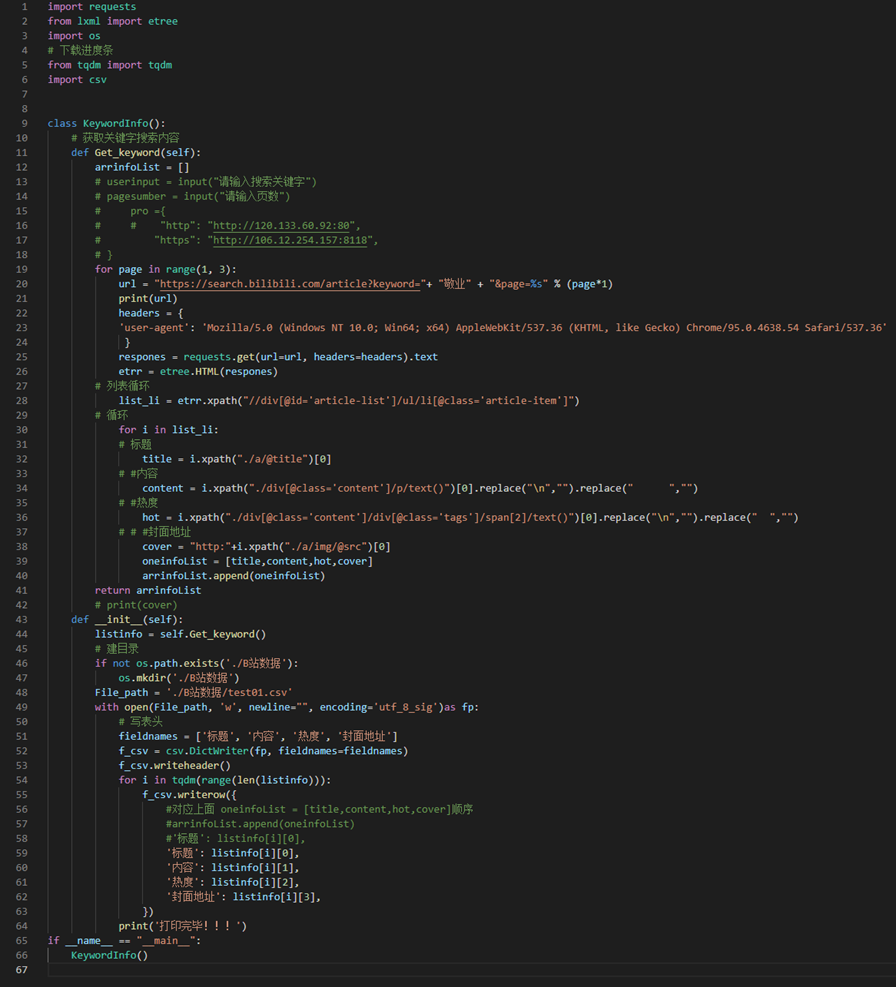
import requests
from lxml import etree
import os
# 下载进度条
from tqdm import tqdm
import csv
class KeywordInfo():
# 获取关键字搜索内容
def Get_keyword(self):
arrinfoList = []
# userinput = input("请输入搜索关键字")
# pagesumber = input("请输入页数")
# pro ={
# # "http": "http://120.133.60.92:80",
# "https": "http://106.12.254.157:8118",
# }
for page in range(1, 3):
url = "https://search.bilibili.com/article?keyword="+ "敬业" + "&page=%s" % (page*1)
print(url)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36'
}
respones = requests.get(url=url, headers=headers).text
etrr = etree.HTML(respones)
# 列表循环
list_li = etrr.xpath("//div[@id='article-list']/ul/li[@class='article-item']")
# 循环
for i in list_li:
# 标题
title = i.xpath("./a/@title")[0]
# #内容
content = i.xpath("./div[@class='content']/p/text()")[0].replace("\n","").replace(" ","")
# #热度
hot = i.xpath("./div[@class='content']/div[@class='tags']/span[2]/text()")[0].replace("\n","").replace(" ","")
# # #封面地址
cover = "http:"+i.xpath("./a/img/@src")[0]
oneinfoList = [title,content,hot,cover]
arrinfoList.append(oneinfoList)
return arrinfoList
# print(cover)
def __init__(self):
listinfo = self.Get_keyword()
# 建目录
if not os.path.exists('./B站数据'):
os.mkdir('./B站数据')
File_path = './B站数据/test01.csv'
with open(File_path, 'w', newline="", encoding='utf_8_sig')as fp:
# 写表头
fieldnames = ['标题', '内容', '热度', '封面地址']
f_csv = csv.DictWriter(fp, fieldnames=fieldnames)
f_csv.writeheader()
for i in tqdm(range(len(listinfo))):
f_csv.writerow({
#对应上面 oneinfoList = [title,content,hot,cover]顺序
#arrinfoList.append(oneinfoList)
#'标题': listinfo[i][0],
'标题': listinfo[i][0],
'内容': listinfo[i][1],
'热度': listinfo[i][2],
'封面地址': listinfo[i][3],
})
print('打印完毕!!!')
if __name__ == "__main__":
KeywordInfo()
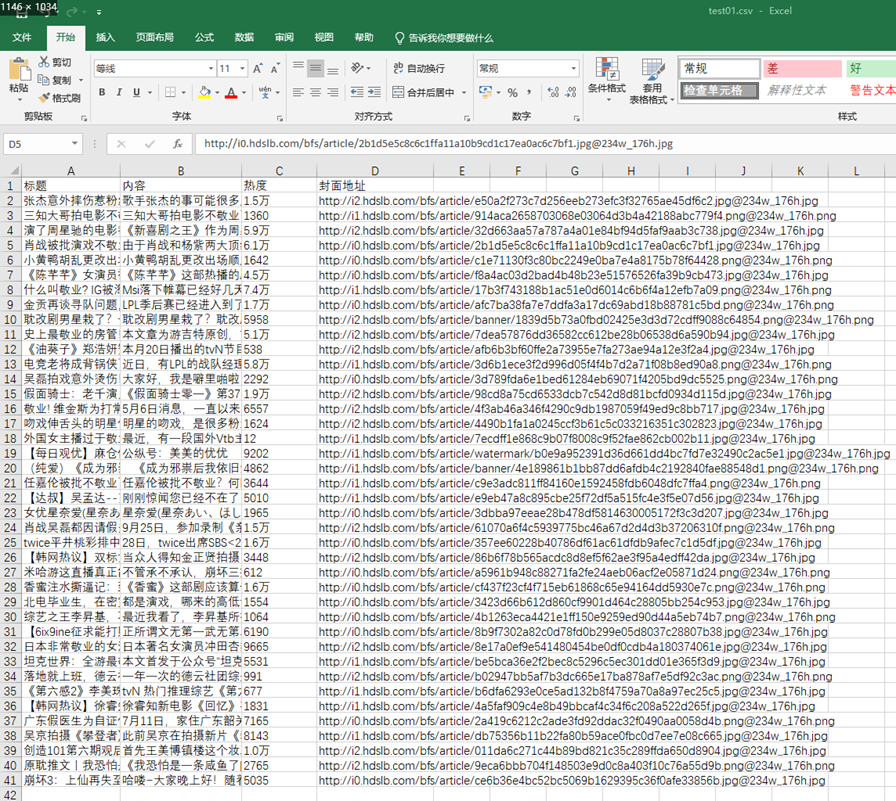
程序运行结果:


1 https://search.bilibili.com/article?keyword=敬业&page=1 2 3 https://search.bilibili.com/article?keyword=敬业&page=2 4 5 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 40/40 [00:00<00:00, 40108.09it/s] 6 7 打印完毕!!!
参考:https://blog.csdn.net/lucky_shi/article/details/105172283

 浙公网安备 33010602011771号
浙公网安备 33010602011771号