
时下畅销小说排行
目标:用Python实现一个面向主题的网络爬虫程序
经过这段时间的python学习,为了检验下自己的学习情况,准备爬取一个小说网站来了解目前畅销的小说的一些基本数据
一,设计方案
1.首先明确要爬取的网站,这边选择爬取的url是:https://mbook.km.com/rank-wanben.html(完本小说网)
2.查看网站源码(f12)
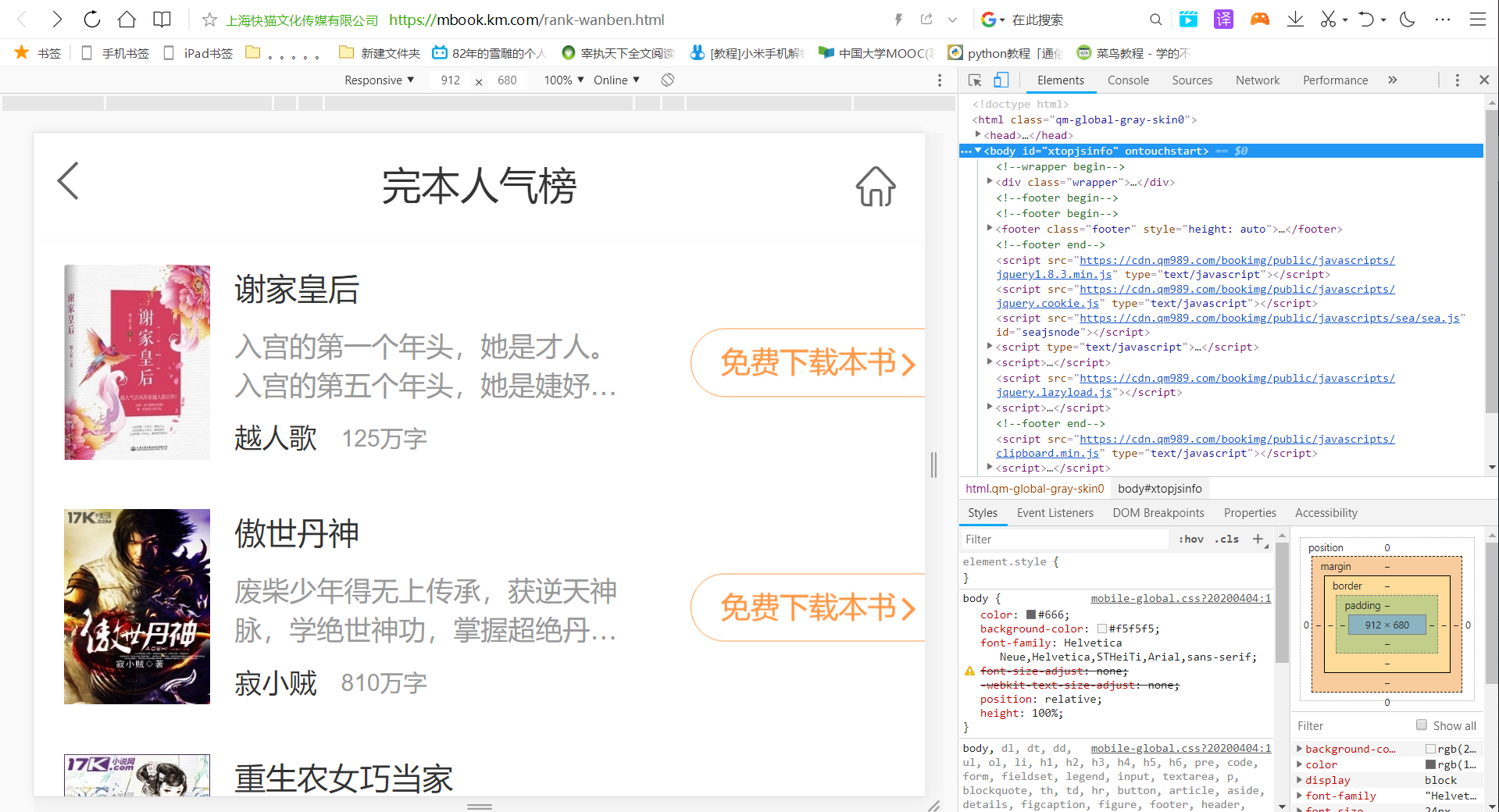
3.接下来一个一个去查看自己要爬的数据是在哪种标签下,一会儿就可以直接引用标签爬数据
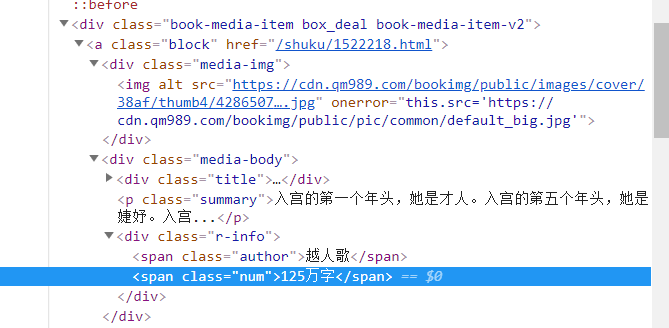
今天要爬的主要是小说名与字数
分别在【div class="media-body"】和【span class="num"】
4.接下来设计代码
先把可能需要的库全部引用下
1 import requests 2 from bs4 import BeautifulSoup 3 import pandas as pd 4 import numpy as np 5 import scipy as sp 6 from numpy import genfromtxt 7 import matplotlib 8 from pandas import DataFrame 9 import matplotlib.pyplot as plt 10 from scipy.optimize import leastsq 11 import urllib.request as urlrequest 12 #导入相关库
接下来设计爬虫
1 url='https://mbook.km.com/rank-wanben.html' 2 #搜索网址 3 headers={'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363'}#伪装爬虫 4 #伪装爬虫 5 r=requests.get(url) 6 #发送get请求 7 r.encoding=r.apparent_encoding 8 #统一编码 9 t=r.text 10 soup=BeautifulSoup(t,'lxml') 11 #使用BeautifulSoup工具解析 12 title=[] 13 count=[] 14 #建立列表 15 for x in soup.find_all('div',class_='title'): 16 title.append(x.get_text().strip()) 17 for y in soup.find_all('span',class_="num"): 18 count.append(y.get_text().strip()) 19 #使用find_all函数进行查找 20 data=[title,count] 21 #把两个列表收到data变量中 22 print(data) 23 df=pd.DataFrame(data,index=["小说","字数"]) 24 #数据可视化 25 print(df.T)
运行后结果如下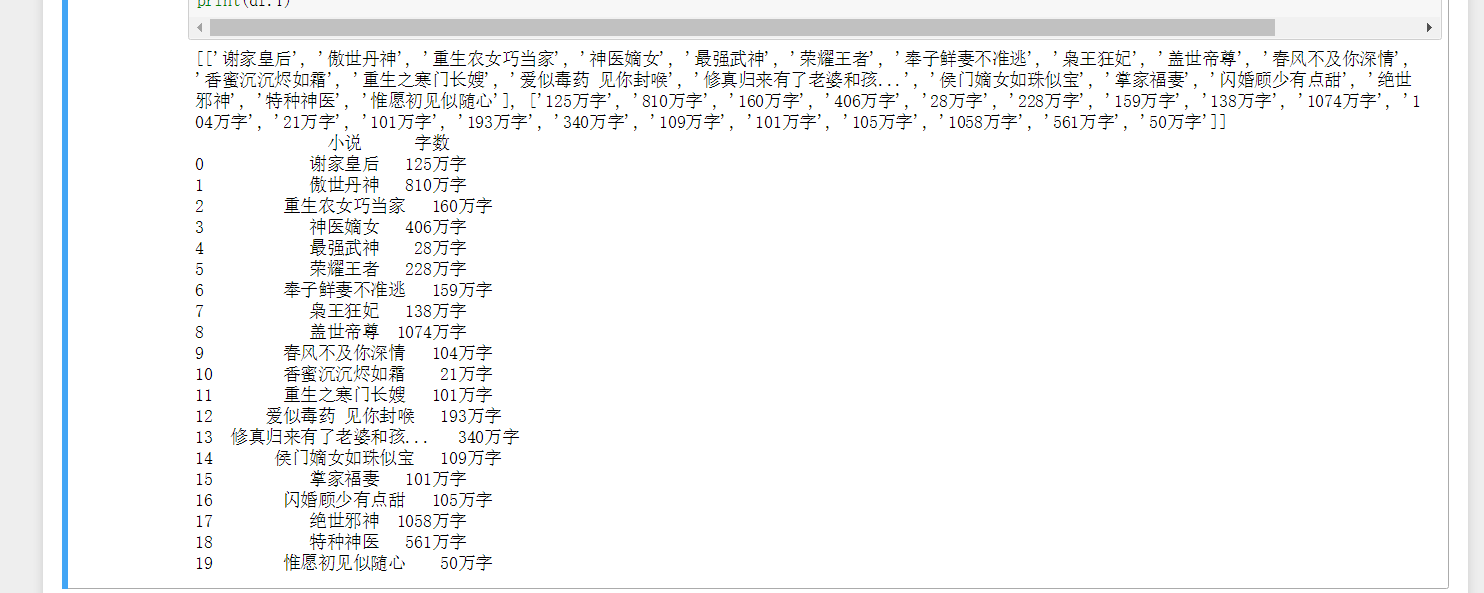
接下来进行数据可视化保存为csv文件
1 df=pd.DataFrame(data,index=["小说",'字数']) 2 #数据可视化 3 df.to_csv('精品小说.csv') 4 #读取csv文件 5 df = pd.DataFrame(pd.read_csv('精品小说.csv')) 6 #print(df) 7 df.head()
结果


按常规·对数据进行分析与处理下
#将数据转换为二维表方便数据清洗 data1=pd.DataFrame(df.T,index=range(1,19),columns=['小说','字数']) #print(data1)查看输出二维表是否出错 #数据清洗 #查找是否有缺失值 data1.isnull() #只显示存在缺失的行列 data1[data1.isnull().values==True] #查找重复值 data1.duplicated() #删除重复值 data2=data1.drop_duplicates() #统计空值 data2.isna() print(data2)
看字太麻烦了就想着把他做成图表
#进行数据可视化 #正常显示中文 plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.rcParams['axes.unicode_minus']=False #创建画布 plt.figure(figsize=(40,20))#设置画布大小
#绘制子图1 axes1=plt.subplot(2,2,4) X=data2.loc[:,'小说'] Y=data2.loc[:,'字数'] #绘制柱状图 plt.bar(X,Y) plt.title('小说') plt.xlabel('小说') plt.ylabel('字数')
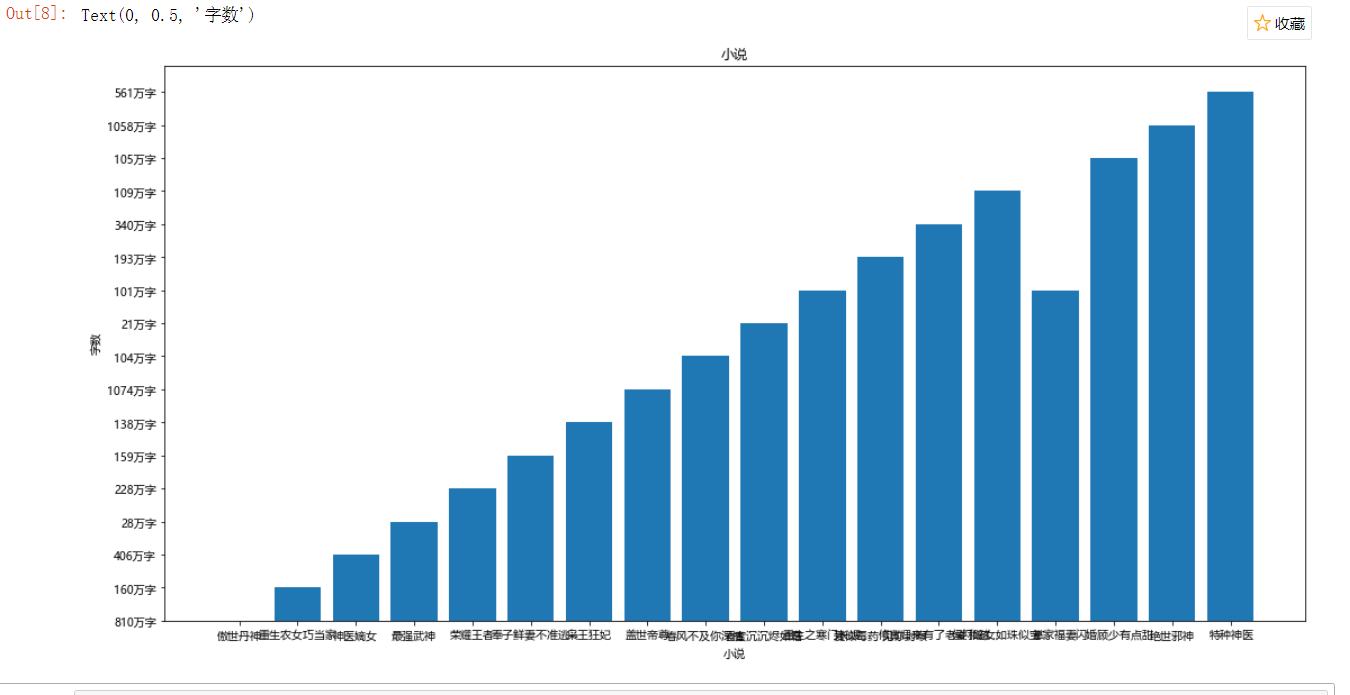
做回归线性
#绘制散点图建立回归方程 X=data2.loc[:,'小说'] Y=data2.loc[:,'字数']#计算相关性 X.corr(Y) def func(params,x): k,b=params return k*x+b #设误差函数 def error(params,x,y): return func(params,x)-y #主程序,输出最后的结果 def main(): plt.figure() p0=[1,1] Para=leastsq(error,p0,args=(X,Y)) k,b=Para[0] print("k={:.2f},b={:.2f}".format(k,b)) plt.scatter(X,Y,color="green",label="论小说名对字数的影响",linewidth=2) #画拟合曲线 x=np.linspace(1,70000,1000) y=k*x+b plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) plt.legend()#绘制图例 plt.grid() plt.show() main()#保存数据dataframe_file.to_csv("论小说名对字数的影响.csv", index=False) {y的数字带汉字,所以图不能生成}
发现无法生成,由于y中有文字所以无法读取(暂时未解决,探索中)
5.完整代码
import requests from bs4 import BeautifulSoup import pandas as pd import numpy as np import scipy as sp from numpy import genfromtxt import matplotlib from pandas import DataFrame import matplotlib.pyplot as plt from scipy.optimize import leastsq import urllib.request as urlrequest #导入相关库 url='https://mbook.km.com/rank-wanben.html' #搜索网址 headers={'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363'}#伪装爬虫 #伪装爬虫 r=requests.get(url) #发送get请求 r.encoding=r.apparent_encoding #统一编码 t=r.text soup=BeautifulSoup(t,'lxml') #使用BeautifulSoup工具解析 title=[] count=[] #建立列表 for x in soup.find_all('div',class_='title'): title.append(x.get_text().strip()) for y in soup.find_all('span',class_="num"): count.append(y.get_text().strip()) #使用find_all函数进行查找 data=[title,count] #把两个列表收到data变量中 print(data) df=pd.DataFrame(data,index=["小说","字数"]) #数据可视化 print(df.T) df=pd.DataFrame(data,index=["小说",'字数']) #数据可视化 df.to_csv('精品小说.csv') #读取csv文件 df = pd.DataFrame(pd.read_csv('精品小说.csv')) #print(df) df.head() #将数据转换为二维表方便数据清洗 data1=pd.DataFrame(df.T,index=range(1,19),columns=['小说','字数']) #print(data1)查看输出二维表是否出错 #数据清洗 #查找是否有缺失值 data1.isnull() #只显示存在缺失的行列 data1[data1.isnull().values==True] #查找重复值 data1.duplicated() #删除重复值 data2=data1.drop_duplicates() #统计空值 data2.isna() print(data2) #进行数据可视化 #正常显示中文 plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.rcParams['axes.unicode_minus']=False #创建画布 plt.figure(figsize=(40,20))#设置画布大小 #绘制子图1 axes1=plt.subplot(2,2,4) X=data2.loc[:,'小说'] Y=data2.loc[:,'字数'] #绘制柱状图 plt.bar(X,Y) plt.title('小说') plt.xlabel('小说') plt.ylabel('字数') #绘制散点图建立回归方程 X=data2.loc[:,'小说'] Y=data2.loc[:,'字数']#计算相关性 X.corr(Y) def func(params,x): k,b=params return k*x+b #设误差函数 def error(params,x,y): return func(params,x)-y #主程序,输出最后的结果 def main(): plt.figure() p0=[1,1] Para=leastsq(error,p0,args=(X,Y)) k,b=Para[0] print("k={:.2f},b={:.2f}".format(k,b)) plt.scatter(X,Y,color="green",label="论小说名对字数的影响",linewidth=2) #画拟合曲线 x=np.linspace(1,70000,1000) y=k*x+b plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) plt.legend()#绘制图例 plt.grid() plt.show() main()#保存数据dataframe_file.to_csv("论小说名对字数的影响.csv", index=False) #y的数字带汉字,所以图不能生成
6.结论:现在的小说基本上都是20万字起步,写手辛苦了
7.小结:通过这次测验,发现自己还有很多地方欠缺,需要继续努力,比如本来想爬其他数据,却因为可能是自己代码有缺陷,只能爬出两个数据,等等。所以接下来需要不断学习,继续加强

 浙公网安备 33010602011771号
浙公网安备 33010602011771号