
大三第五周——hive作业
这周老师让用hive+hadoop实现日志数据的处理,然后对统计出的结果进行可视化的展示。
1.先对数据进行清洗
两阶段数据清洗:
(1)第一阶段:把需要的信息从原始日志中提取出来
ip: 199.30.25.88
time: 10/Nov/2016:00:01:03 +0800
traffic: 62
文章: article/11325
视频: video/3235
(2)第二阶段:根据提取出来的信息做精细化操作
ip--->城市 city(IP)
date--> time:2016-11-10 00:01:03
day: 10
traffic:62
type:article/video
id:11325
(3)hive数据库表结构:
create table data( ip string, time string , day string, traffic bigint,
type string, id string )
由于对MapReduce不熟练就先使用了用java清洗
对数据进行清洗:
package mapreduceShiYan; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.FileReader; import java.io.IOException; import java.io.OutputStreamWriter; import java.io.UnsupportedEncodingException; import java.io.Writer; public class Data { public static void main(String[] args) throws FileNotFoundException, UnsupportedEncodingException { FileReader read = new FileReader("result.txt"); BufferedReader br = new BufferedReader(read); Writer writer = null; File outFile = new File("result2.txt"); writer = new OutputStreamWriter(new FileOutputStream(outFile),"utf-8"); BufferedWriter bw = new BufferedWriter(writer); String row; String[] data=new String[6]; int hang=1; try { while((row = br.readLine())!=null){ data=change(row); data=chage(data); for(int i=0;i<data.length;i++) { System.out.print(data[i]+"\t"); } System.out.println(); row=data[0]+","+data[1]+","+data[2]+","+data[3]+","+data[4]+","+data[5]; bw.write(row + "\r\n"); //i++; } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } private static String[] chage(String[] data) { /* * for(int i=0;i<data.length;i++) { data[] } */ data[0]=data[0]; char[] str=data[1].toCharArray(); String[] time=new String[7]; int j=0; int k=0; for(int i=0;i<str.length;i++) { if(str[i]=='/'||str[i]==':'||str[i]==32) { time[k]=data[1].substring(j,i); j=i+1; k++; } } time[k]=data[1].substring(j, data[1].length()); switch(time[1]) { case "Jan":time[1]="01";break; case "Feb":time[1]="02";break; case "Mar":time[1]="03";break; case "Apr":time[1]="04";break; case "May":time[1]="05";break; case "Jun":time[1]="06";break; case "Jul":time[1]="07";break; case "Aug":time[1]="08";break; case "Sep":time[1]="09";break; case "Oct":time[1]="10";break; case "Nov":time[1]="11";break; case "Dec":time[1]="12";break; } data[1]=time[2]+"-"+time[1]+"-"+time[0]+" "+time[3]+":"+time[4]+":"+time[5]; data[3]=data[3].substring(0, data[3].length()-1); return data; } private static String [] change(String row) { char [] str1=row.toCharArray(); String [] data =new String [6]; int j=0; int k=0; for(int i=0;i<str1.length;i++) { if(str1[i]==',') { data[k]=row.substring(j, i); j=i+1; k++; } } data[k]=row.substring(j, str1.length); return data; } }
对清洗后的数据(我保存在了result2中)在Web界面上传到hive数据库中
2、数据处理:
·统计最受欢迎的视频/文章的Top10访问次数 (video/article)
·按照地市统计最受欢迎的Top10课程 (ip)
·按照流量统计最受欢迎的Top10课程 (traffic)
我用java连的hive数据库,根据sql语句新建了3个表
create table M_video
as select
id as type,
count(*) as num
from data1 group by id
order by num desc limit 10;
create table M_ip
as select
ip,type,id,count(*) as num
from data1
group by ip,type,id
order by num desc
limit 10;
create table M_traffic
as select
id,type,traffic from data1
order by traffic desc limit 10;
3、可视化
用FineBI将三个表分别用柱状图、饼状图、折线图表示
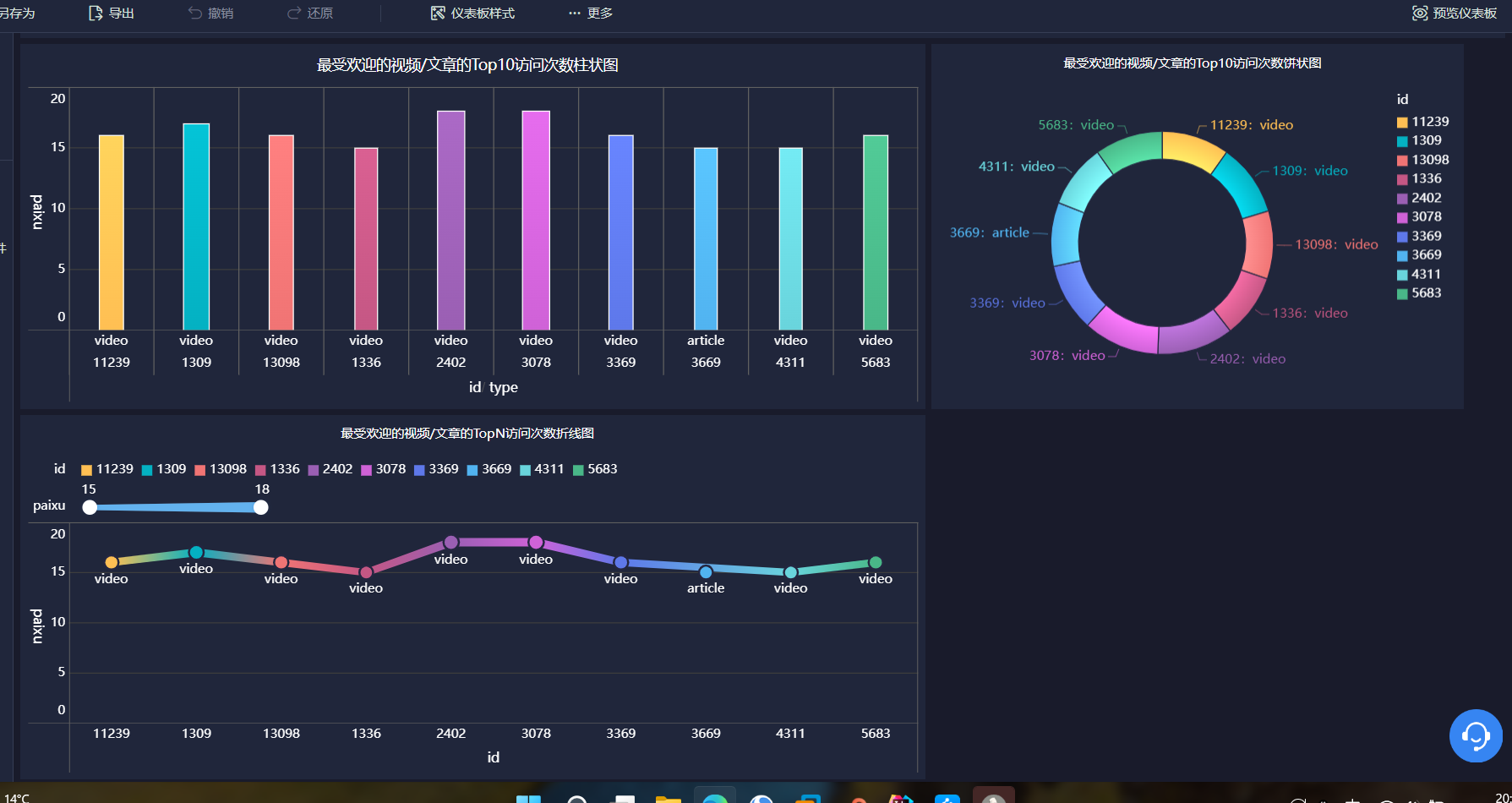
![]()
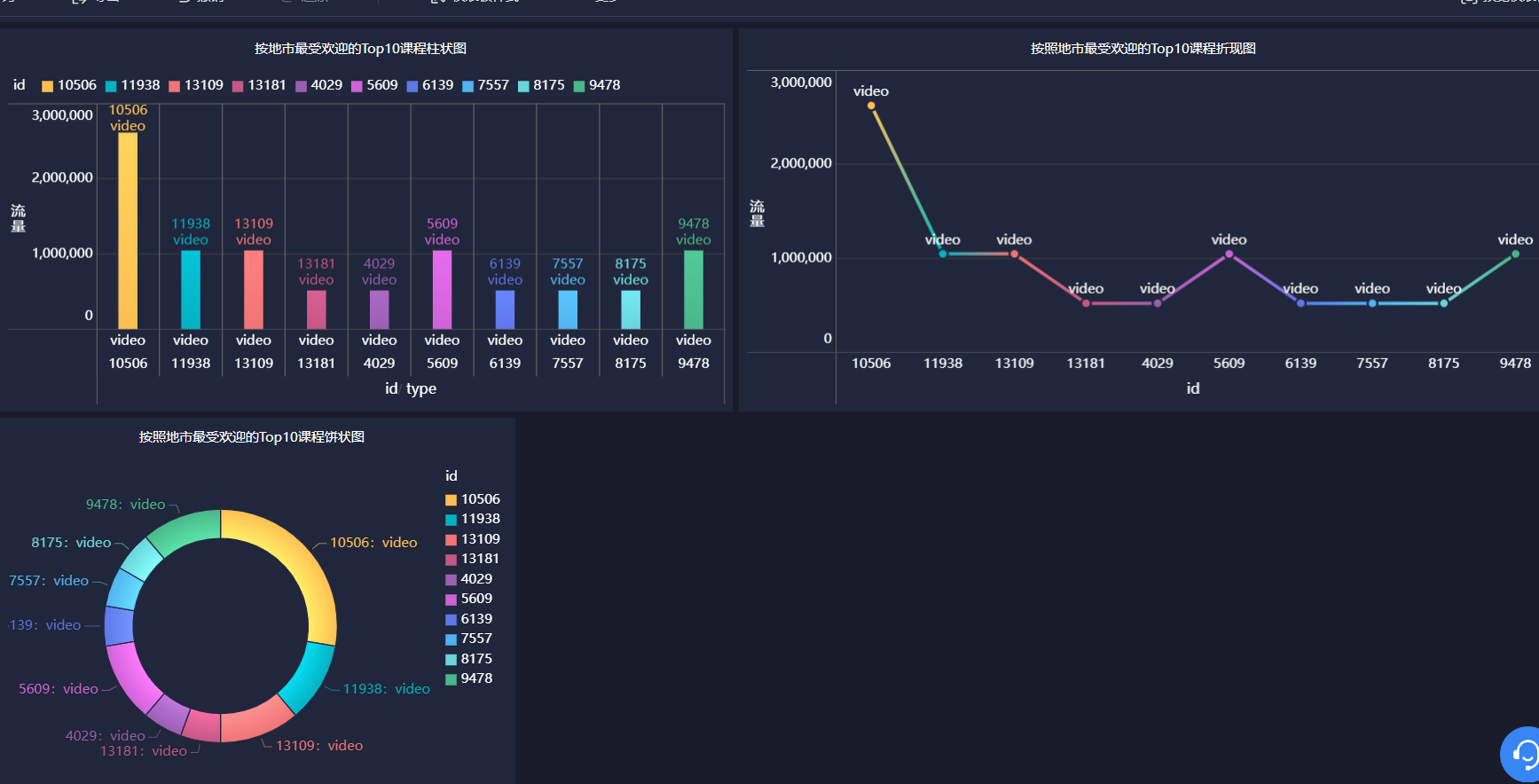
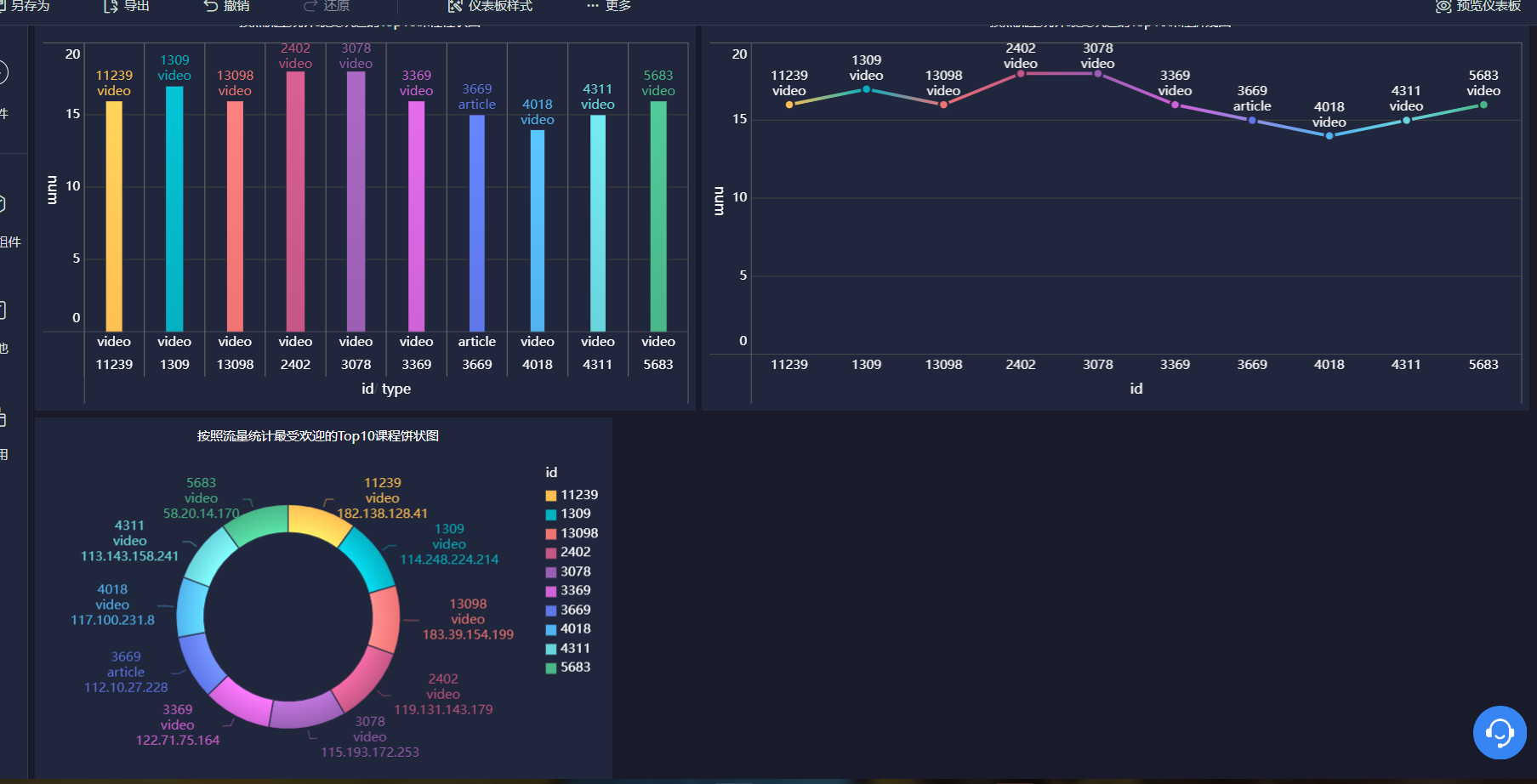
感受:
这次作业总体上来说还是比较简单的,重点是把脏数据进行清洗,然后根据要求建立三个新的表,后面的可视化用FineBI就很容易就完成了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号