
结对编程作业
PART 1 链接以及分工
一、链接
二、分工
| 队伍成员 | 姓名 | 负责部分 |
| ---- | ---- | ---- | ---- |
| 组长 | 杨文龙 | AI算法的实现,原型图的绘制 |
| 组员 | 蔡沿江 | 可玩华容道的实现,优化游戏界面 |
PART 2 原型设计
一、设计过程
-
本次原型设计采用了Axure Rp
-
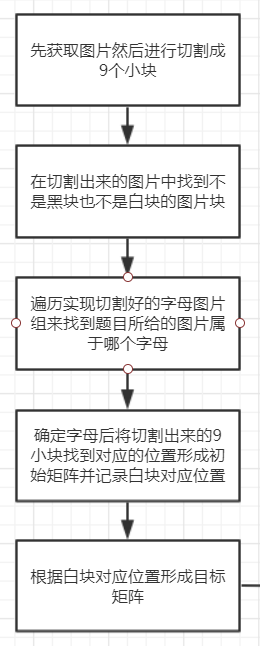
首先我们先从网上找到了一个数字华容道的代码,将其的数字改造成图片华容道,而该数字华容道的话,是固定每次将第九个格子变成空格,为了符合题目要求,应该设计成空白图片随机生成,所以我们设计了以下这个缺失了第三块图片的华容道,并将其打乱。

-
接着我们认为如果只有游戏的话未免显得太过单调,于是我们就设计了一个游戏开始之前的开始页面,在这个页面中有三个按钮,一个是开始游戏,一个是显示历史成绩,一个是结束选择退出程序。
-
点击开始游戏就可以进入到最开始我们设计的游戏界面,并关闭开始界面;点击历史成绩就会打开历史成绩页面,并关闭开始界面;点击退出按钮则会结束程序。

- 在历史得分界面我们会将最近十五次的游戏成绩呈现,但并不按照步数的长短来进行排序,因为华容道的生成是随机的,那么完成的步数并没有对比的公平性。同时我们也添加了返回开始页面的按钮和再来一局的按钮,用来进行页面的跳转。

- 最后考虑到游戏界面的美观问题,决定将开始界面的背景图片融入到游戏界面当中,并且稍微加大图片块之间的间隔。

二、结队
(1)结队过程
- 两个人在上课时候一拍即合组队成功十分顺利没有意外

(2)困难及解决方法
- 刚开始并不会使用Axure Rp,然后及时去B站上学了一下才发现并不困难。之后就是感觉自己设计的原型图太过丑陋,
希望图没事就一直改图,而且背景图总感觉和开始界面格格不入,一直找好看的图片,后面去参考了一下网上的一写界面设计才有了一些思路,虽然设计出来的原型还是很丑陋,但至少能看一些了(这大概就是理工直男吧)。
PART 3 AI与原型设计实现
一、代码实现思路
- 网络接口的使用
--> 贴代码
#获取文本
def gethtml(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3941.4 Safari/537.36'
}
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
#获取赛题列表
def getchallengelist():
url = "http://47.102.118.1:8089//api/challenge/list"
# 每次请求的结果都不一样,动态变化
datalist = json.loads(gethtml(url))
for t in datalist:
print(t)
#获取具体赛题
def getchallenge(uuid):
url = "http://47.102.118.1:8089/api/challenge/start/" + uuid
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3941.4 Safari/537.36',
'Content-Type': 'application/json'
}
data_json = json.dumps({
"teamid": 21,
"token": "a8aee99c-f29b-42c6-abd0-72216d8d851c"
})
r = requests.post(url, headers=headers, data=data_json)
text = json.loads(r.text)
chanceleftleft = text["chanceleft"]
data = text["data"]
img_base64 = data["img"]
step = data["step"]
swap = data["swap"]
success = text["success"]
img = base64.b64decode(img_base64)
uuid = text["uuid"]
expire = text["expire"]
with open("photo.jpg", "wb") as fp:
fp.write(img) # 900*900
return step, swap, uuid
#提交答案
def postAnswer(uuid,operations,swap):
url ="http://47.102.118.1:8089/api/challenge/submit"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3941.4 Safari/537.36',
'Content-Type': 'application/json'
}
data_json = json.dumps({
"uuid": uuid,
"teamid": 24,
"token": "a8aee99c-f29b-42c6-abd0-72216d8d851c",
"answer": {
"operations": operations,
"swap": swap}}
)
r=requests.post(url,headers = headers,data = data_json)
print(r.text)
--> getchallengelist():获取今日赛题后打印列表
--> getchallenge(uuid):传入getchallengelist()中获取的的uuid获取具体的赛题数据和答题所用的uuid
--> postAnswer(uuid,operations,swap):输入getchallenge(uuid)获取的uuid和答题数据来上传答案,返回排名等数据
- 代码组织与内部实现设计(类图)
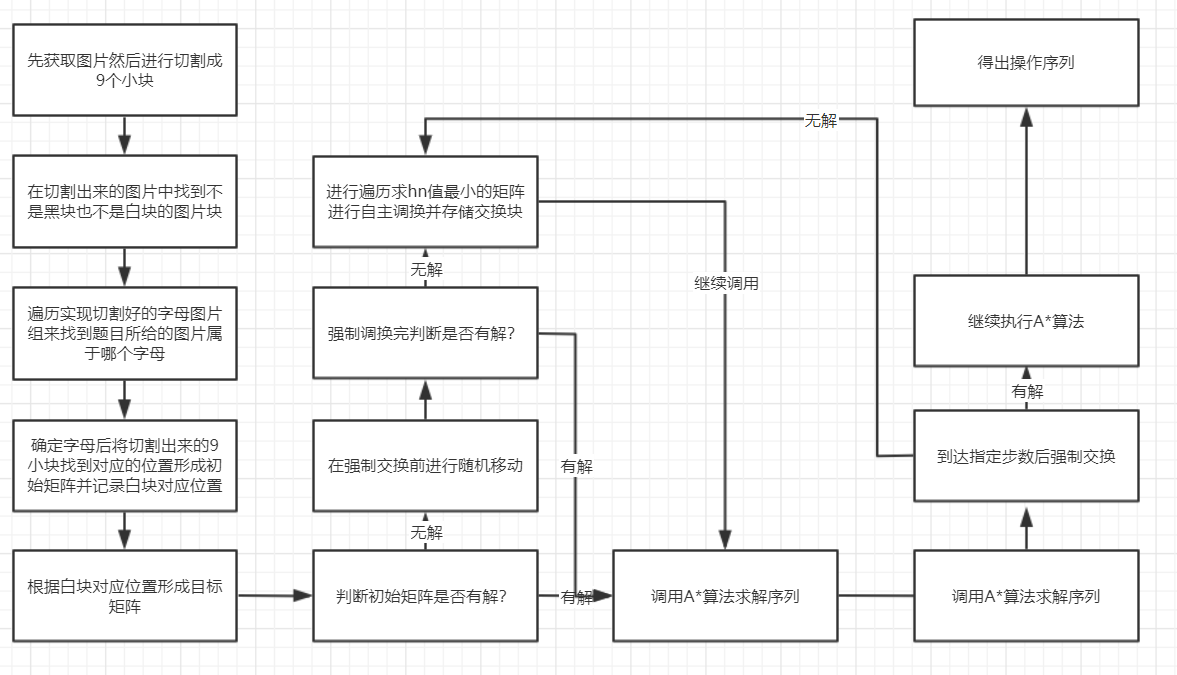
- 说明算法的关键与关键实现部分流程图
--> 算法关键是如何将原始图片转换成对应矩阵进行求解,这部分求解了大佬才知道该怎么做
- 贴出你认为重要的/有价值的代码片段,并解释
def cutimage():
# 切割图片
img = Image.open('photo.jpg')
size = img.size
# 准备将图片切割成9张小图片
weight = int(size[0] // 3)
height = int(size[1] // 3)
# 切割后的小图的宽度和高度
for j in range(3):
for i in range(3):
box = (weight * i, height * j, weight * (i + 1), height * (j + 1))
region = img.crop(box)
region.save('{}{}.jpg'.format(j, i))
-->切割图片用的函数,调用了PIL库的crop函数,给定边界将图片切割成9块保存
def compare(pic1,pic2):
image1 = Image.open(pic1)
image2 = Image.open(pic2)
histogram1 = image1.histogram()
histogram2 = image2.histogram()
differ = math.sqrt(reduce(operator.add, list(map(lambda a,b: (a-b)**2,histogram1, histogram2)))/len(histogram1))
if differ == 0:
return True
else:
return False
--> 对比两张图片是否相同的函数,调用PIL库中histogram函数比较,但是发现只能用同一切割函数切出来的块图片才能准确识别
#获得图片所对应的图是哪一区域
def getnum(path11):
path = 'E://PyCharm 2020.2.1//python//确定序列//'
for i in range(0, 36):
path2 = path + str(i) + '_'
for j in range(1, 10):
path22 = path2 + str(j) + '.jpg'
if compare(path11, path22):
return i
def bulitlist(num):
list1 = []
for i in range(3):
for j in range(3):
path1 = 'E://PyCharm 2020.2.1//python//' + str(i) + str(j) + '.jpg'
if compare(path1, 'E://PyCharm 2020.2.1//python//确定序列//white.jpg'):
list1.append(0)
else:
for k in range(1, 10):
path2 = 'E://PyCharm 2020.2.1//python//确定序列//' + str(num) + '_' + str(k) + '.jpg'
if compare(path1, path2):
list1.append(k)
sum = 0
for i in list1:
sum += i
whitenum = 45-sum
list2 = [[], [], []]
list2[0] = list1[0:3]
list2[1] = list1[3:6]
list2[2] = list1[6:9]
return list2,whitenum
-->获取到初始矩阵的函数,getnum函数负责对比找到题目所给图片位于36张中对应的那一组,builitlist函数负责将9张切割过的图片和对应字母组的预先切割好的图片进行匹配,然后得到初始矩阵
- 性能分析与改进
--> 原本采用的A算法,效率太低就想着采用A*算法来改进了
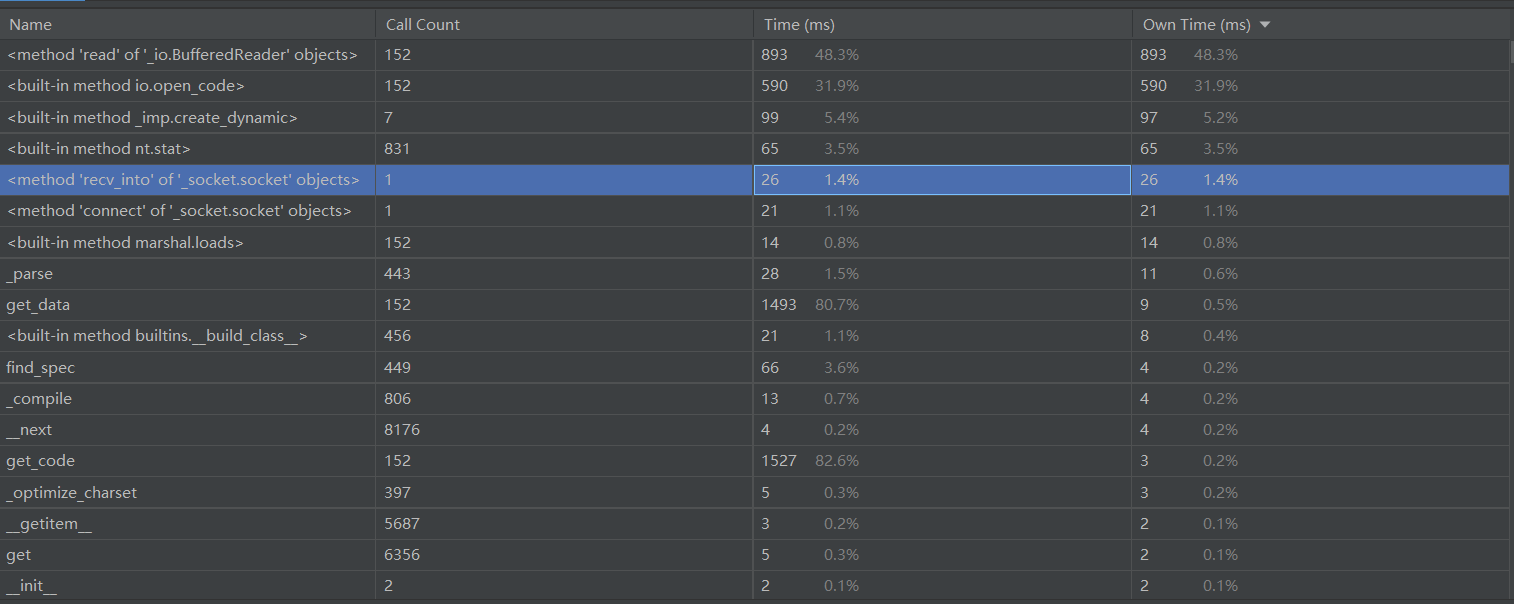
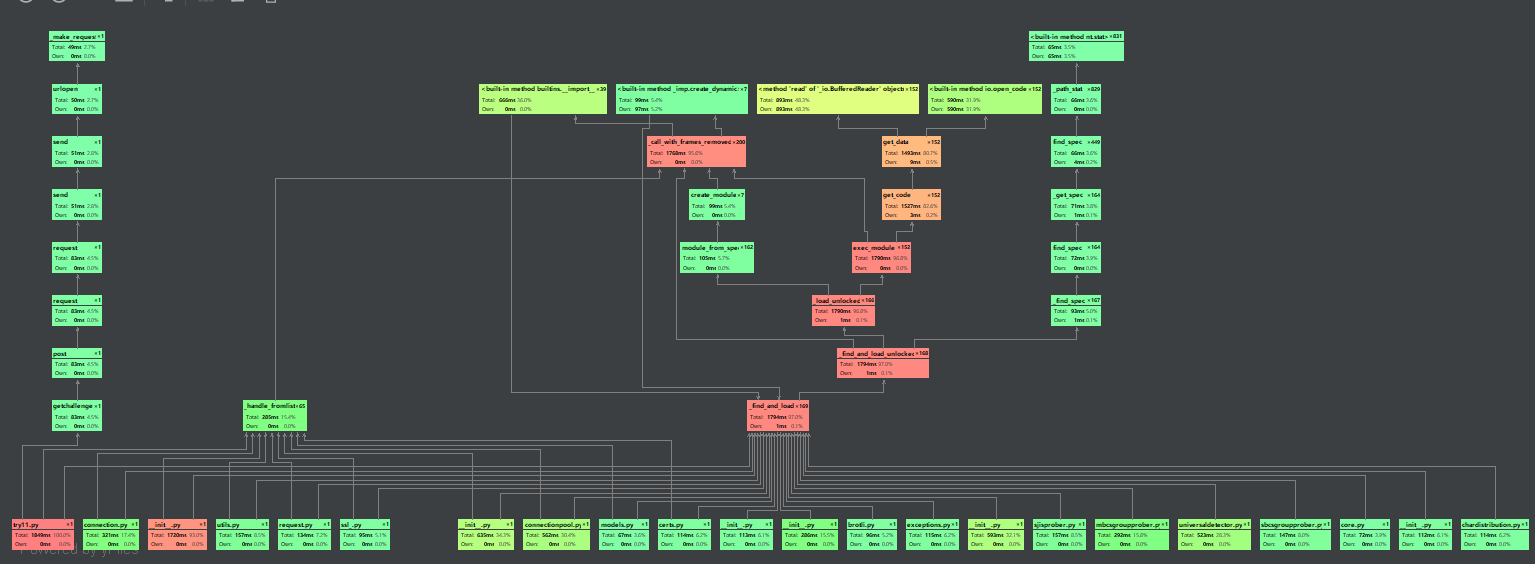
- 展示性能分析图和程序中消耗最大的函数
--> 贴下图
- 展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路
#获取文本
def gethtml(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3941.4 Safari/537.36'
}
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
#获取问题
def getproblem():
url = "http://47.102.118.1:8089/api/problem?stuid=031802435"
# 每次请求的结果都不一样,动态变化
text = json.loads(gethtml(url))
# print(text.keys())#dict_keys(['img', 'step', 'swap', 'uuid'])
# text["img"] = "none" #{'img': 'none', 'step': 0, 'swap': [7, 7], 'uuid': '3bc827e5008d460b893e5cb28769e6bf'}
img_base64 = text["img"]
step = text["step"]
swap = text["swap"]
uuid = text["uuid"]
img = base64.b64decode(img_base64)
# 获取接口的图片并写入本地
with open("photo.jpg", "wb") as fp:
fp.write(img) # 900*900
return step, swap, uuid
#提交答案
def postAnswer(uuid, opertions, swap):
url = "http://47.102.118.1:8089/api/answer"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3941.4 Safari/537.36',
'Content-Type': 'application/json'
}
data_json = json.dumps({
"uuid": uuid,
"answer": {
"operations": opertions,
"swap": swap}
})
r = requests.post(url, headers=headers, data=data_json)
print(r.text)
--> 测试代码我采用的是结对编程要求的接口,经过测试没有问题
二、贴出Github的代码签入记录,合理记录commit信息
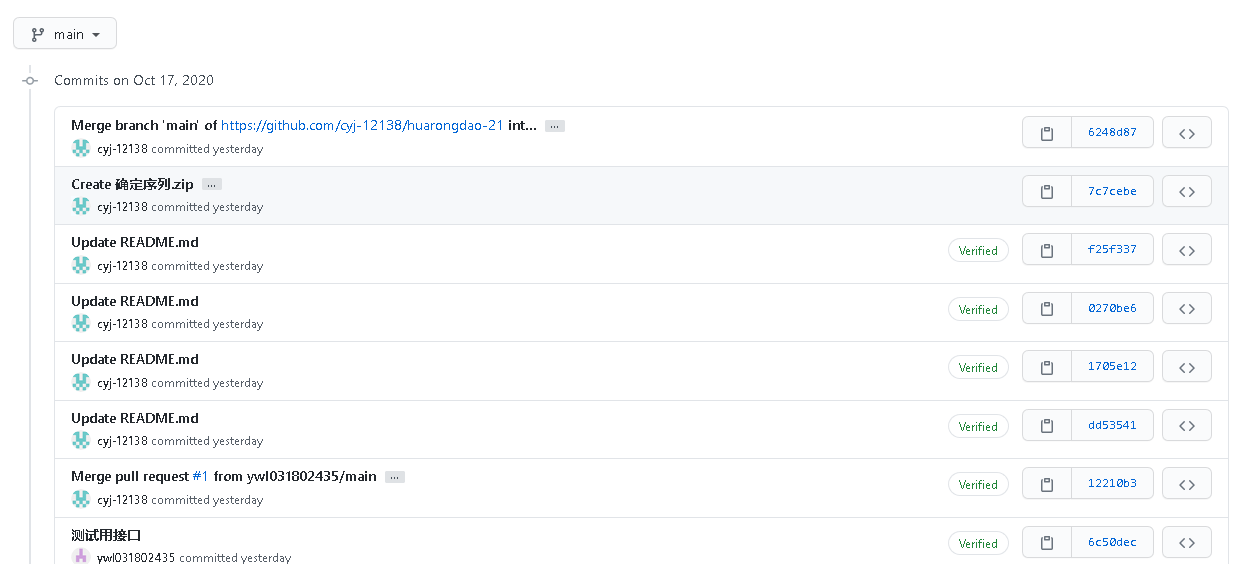
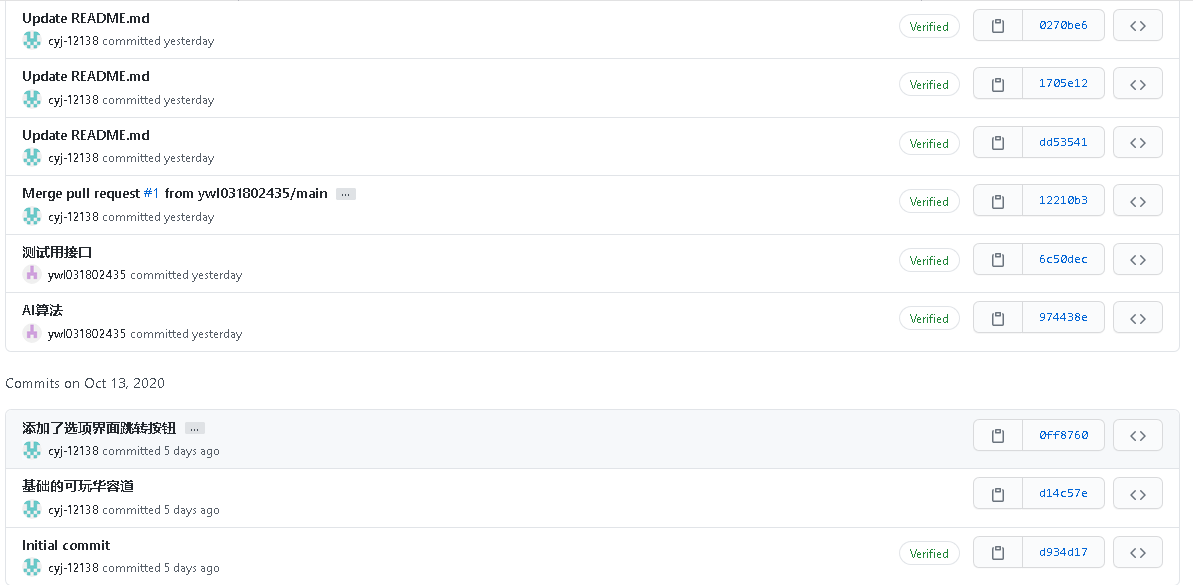
三、遇到的代码模块异常或结对困难及解决方法
--> 一开始对算法不了解,采用A算法经常跑不出结果,效率过低,然后换用A*算法。
--> 在测试前一天发现自己的代码有时对有时错,询问测试组大佬才知道自己理解错题,然后一顿倒腾才解决强制交换的问题。
四、评价你的队友
- ddl前速成UI设计,着实猛,给游戏加了些功能,自学能力强,不介意我写的算法太low(555)
- 觉得我们都还是太拖拉了,希望之后能互相监来让自己的ddl前的生活过的不要那么艰难(梦里都是软工太可怕了)
五、PSP和学习进度条
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 540 | 600 |
| · Estimate | · 估计这个任务需要多少时间 | 540 | 600 |
| Development | 开发 | 1000 | 1140 |
| · Analysis | · 需求分析 (包括学习新技术) | 480 | 540 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 30 | 40 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 60 | 60 |
| · Coding | · 具体编码 | 240 | 300 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting | 报告 | 120 | 120 |
| · Test Repor | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 1660 | 1860 |
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 无 |
| 2 | 250 | 250 | 10 | 10 | 对题目的意思深度理解寻求解决八数码问题的代码并对其改进 |
| 3 | 100 | 350 | 15 | 25 | 改进代码使其符合题目的要求,包括处理图片,矩阵交换等问题 |
| 4 | 100 | 450 | 10 | 35 | 进行测试,然后bug越改越多,好在还是在比拼前改完 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号