树
| 这个作业属于哪个班级 |

| ---- | ---- | ---- |
| 这个作业的地址 |
| 这个作业的目标 |学习树结构设计及运算操作 |
| 姓名|喻文康|
0.PTA得分截图

1.本周学习总结
1.1 二叉树结构
1.1.1 二叉树的2种存储结构
顺序表适宜于做查找这样的静态操作;链表宜于做插入、删除这样的动态操作。 若线性表的长度变化不大,且其主要操作是查找,则采用顺序表;若线性表的长度变化较大,且其主要操作是插入、删除操作,则采用链表。
① 顺序存储时,相邻数据元素的存放地址也相邻(逻辑与物理统一);要求内存中可用存储单元的地址必须是连续的。
优点:存储密度大,存储空间利用率高。
缺点:插入或删除元素时不方便。
②链式存储时,相邻数据元素可随意存放,但所占存储空间分两部分,一部分存放结点值,另一部分存放表示结点间关系的指针
优点:插入或删除元素时很方便,使用灵活。
缺点:存储密度小,存储空间利用率低。
1.1.2 二叉树的构造
同一棵二叉树(节点值均不相同)具有唯一的先序、中序、后序序列和层次序列,但不同的二叉树可能具有相同的先序、中序序列、后序序列和层次序列,二叉树的构造就是根据提供的某些遍历序列构造二叉树的结构。(详细构造方法如下)
① 由先序序列和中序序列构造二叉树:先序序列提供了二叉树的根节点的信息(任何一棵二叉树的先序序列的第一个节点为根节点),而中序序列提供了由根节点将整个序列分为左、右子树的信息。
确定树的根节点:先序遍历的第一个节点
求解树的子树:找出根节点在中序遍历中的位置,根左边的是左子树,右边的是右子树。
递归求解树:将左子树和右子树看成一棵二叉树,重复上面步骤
②由后序序列和中序序列构造二叉树:后序序列提供了二叉树的根节点的信息(任何一棵二叉树的后序序列的最后一个节点为根节点),而中序序列提供了由根节点将整个序列分为左、右子树的信息。
确定树的根节点:后序遍历的最后一个节点
求解树的子树:找出根节点在中序遍历中的位置,根左边的是左子树,右边的是右子树。
递归求解树:将左子树和右子树看成一棵二叉树,重复上面步骤
③由层次序列和中序序列构造二叉树:层次序列提供了二叉树的根节点的信息(任何一棵二叉树的层次序列的第一个节点为根节点),而中序序列提供了由根节点将整个序列分为左、右子树的信息。
确定树的根节点:层次遍历的第一个节点
求解树的子树:找出根节点在中序遍历中的位置,根左边的是左子树,右边的是右子树。
递归求解树:将左子树和右子树看成一棵二叉树,重复上面步骤。
1.1.3 二叉树的遍历
二叉树的四种遍历方式:
二叉树的遍历是指从根结点出发,按照某种次序依次访问二叉树中所有的结点,使得每个结点被访问依次且仅被访问一次。
四种遍历方式分别为:先序遍历、中序遍历、后序遍历、层序遍历。
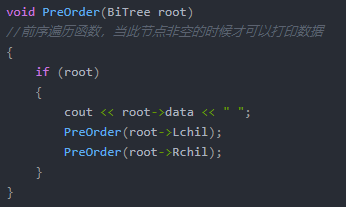
①先(根)序遍历(根左右)
代码实现:
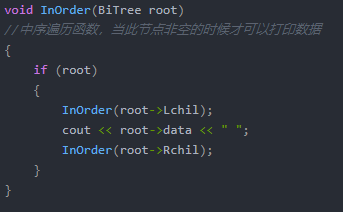
②中(根)序遍历(左根右)
代码实现:
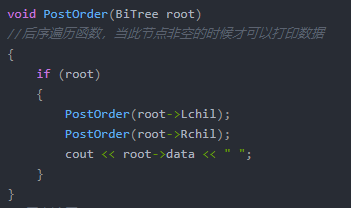
③后(根)序遍历(左右根)
代码实现:
④层次遍历(队列)
按照从上到下,从左到右依次将二叉树遍历一遍
代码实现:

1.1.4 线索二叉树
在二叉树的结点上加上线索的二叉树称为线索二叉树,对二叉树以某种遍历方式(如先序、中序、后序或层次等)进行遍历,使其变为线索二叉树的过程称为对二叉树进行线索化
线索化:
现将某结点的空指针域指向该结点的前驱后继,定义规则如下:
若结点的左子树为空,则该结点的左孩子指针指向其前驱结点。
若结点的右子树为空,则该结点的右孩子指针指向其后继结点。
这种指向前驱和后继的指针称为线索。将一棵普通二叉树以某种次序遍历,并添加线索的过程称为线索化。
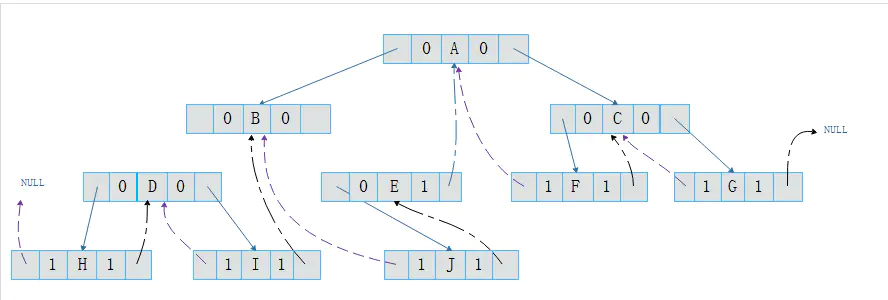
中序线索二叉树特点:
加上线索的二叉树结构是一个双向链表结构,为了便于遍历线索二叉树,我们为其添加一个头结点,头结点左孩子指向原二叉树的根结点,右孩子指针指向中序遍历的最后一个结点。同时,将第一个结点左孩子指针指向头结点,最后一个结点的右孩子指针指向头结点。
如何在中序线索二叉树查找前驱和后继:
在生成了线索化二叉树之后,查找某个结点的前驱或者是后继都变的简单起来
找前驱:
若无左子树,则为前驱线索所指的结点
否则为对其左子树最右的结点
找后继:
若无右子树,则为后继线索所指的结点
否则为对其右子树最左的结点
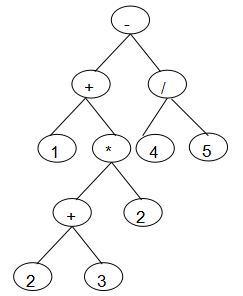
1.1.5 二叉树的应用--表达式树
表达式树的构造
算法思想:
从前向后依次扫描后缀表达式,如果是操作数就建立一个单节点树,并把其指针压入栈。
如果是操作符,则建立一个以该操作符为根的树,然后从栈中依次弹出两个指针(这2个指针分别指向2个树),作为该树的左右子树。
然后把指向这棵树的指针压入栈。直到扫描完后缀表达式。
最后栈中就会只有一个指针。这个指针指向构造的表达式树的根节点。
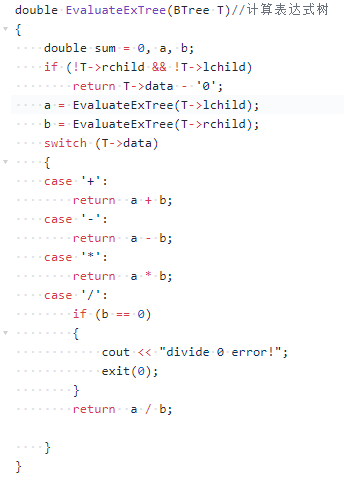
计算表达式树
运用递归调用,计算每个子树运算后的结果,从树根遍历到叶子结点后再不断返回子树计算的值
代码实现:
1.2 多叉树结构
1.2.1 多叉树结构
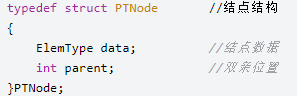
①父结点(双亲)表示法
这种结构的思想比较简单:除了根结点没有父结点外,其余每个结点都有一个唯一的父结点。将所有结点存到一个数组中。每个结点都有一个数据域data和一个数值parent指示其双亲在数组中存放的位置。根结点由于没有父结点,parent用-1表示。
②孩子表示法
换一种不同的考虑方法。由于每个结点可能有多棵子树,可以考虑使用多重链表,即每个结点有多个指针域,其中每个指针指向一棵子树的根结点,我们把这种方法叫做多重链表表示法。不过树的每个结点的度,也就是它的孩子个数是不同的。

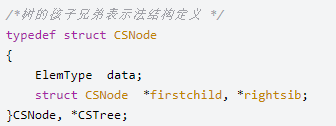
③孩子兄弟表示法
我们发现,任意一颗树,它的结点的第一个孩子如果存在就是唯一的,它的右兄弟如果存在也是唯一的。因此,我们设置两个指针,分别指向该结点的第一个孩子和此结点的右兄弟。
1.2.2 多叉树遍历
①递归法

②非递归法
运用栈来完成,可以省很多时间
这里需要注意一下,二叉树的前序遍历中直接右子节点先入栈然后左子节点入栈,在多叉树中,某个节点存在多个子节点,使用for循环逆序遍历入栈即可。

1.3 哈夫曼树
1.3.1 哈夫曼树定义
哈夫曼树(最优二叉树)
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
举例:
在很多问题的处理过程中,需要进行大量的条件判断,这些判断结构的设计直接影响着程序的执行效率。例如,编制一个程序,将百分制转换成五个等级输出。大家可能认为这个程序很简单,并且很快就可以用下列形式编写出来,若考虑上述程序所耗费的时间,就会发现该程序的缺陷。在实际中,学生成绩在五个等级上的分布是不均匀的。当学生百分制成绩的录入量很大时,上述判定过程需要反复调用,此时程序的执行效率将成为一个严重问题。
但在实际应用中,往往各个分数段的分布并不是均匀的。而运用哈夫曼树可以使数据的存储更精简,运算更高效,这样就有效地解决程序运行效率低的这类问题。
1.3.2 哈夫曼树的结构体
构建哈夫曼树
对于给定的有各自权值的 n 个结点,构建哈夫曼树有一个行之有效的办法:
1.在 n 个权值中选出两个最小的权值,对应的两个结点组成一个新的二叉树,且新二叉树的根结点的权值为左右孩子权值的和;
2.在原有的 n 个权值中删除那两个最小的权值,同时将新的权值加入到 n–2 个权值的行列中,以此类推;
3.重复 1 和 2 ,直到所以的结点构建成了一棵二叉树为止,这棵树就是哈夫曼树。
哈弗曼树中结点结构
构建哈夫曼树时,首先需要确定树中结点的构成。由于哈夫曼树的构建是从叶子结点开始,不断地构建新的父结点,直至树根,所以结点中应包含指向父结点的指针。但是在使用哈夫曼树时是从树根开始,根据需求遍历树中的结点,因此每个结点需要有指向其左孩子和右孩子的指针。
所以,哈夫曼树中结点构成用代码表示为:

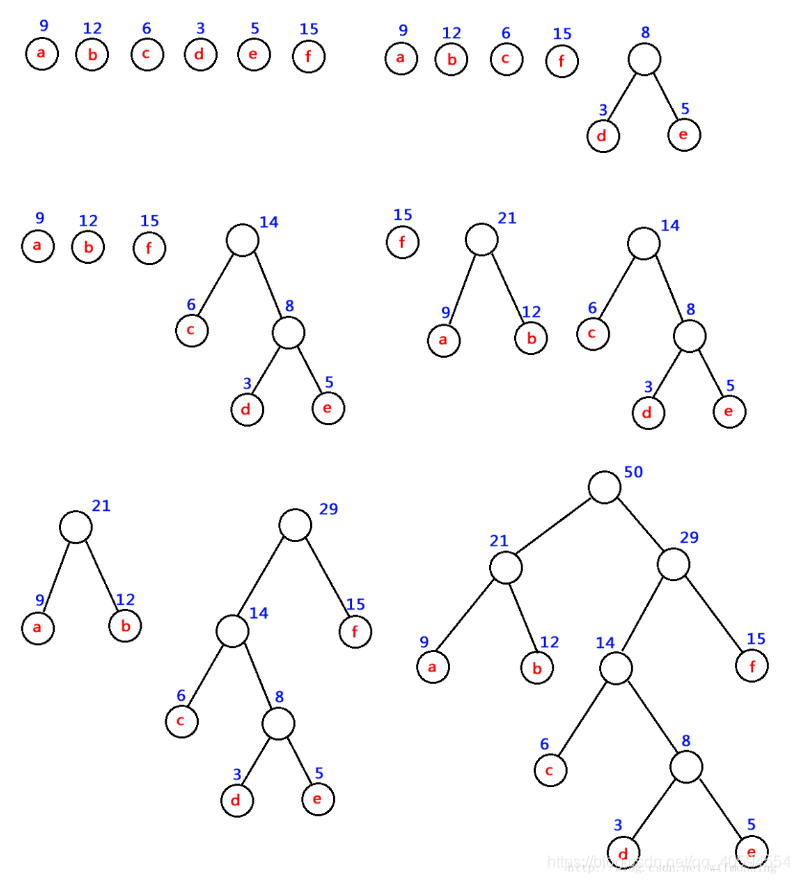
1.3.2 哈夫曼树构建及哈夫曼编码
构造Huffman树的步骤:
① 根据给定的n个权值,构造n棵只有一个根结点的二叉树,n个权值分别是这些二叉树根结点的权;
②设F是由这n棵二叉树构成的集合,在F中选取两棵根结点权值最小的树作为左、右子树,构造成一颗新的二叉树,置新二叉树根结点的权值等于左、右子树根结点的权值之和。为了使得到的哈夫曼树的结构唯一,规定根结点权值最小的作为新二叉树的左子树。
③从F中删除这两棵树,并将新树加入F;
④重复②、③步,直到F中只含一棵树为止,这棵树便是Huffman树。
说明:n个结点需要进行n-1次合并,每次合并都产生一个新的结点,最终的Huffman树共有2n-1个结点。
图解:
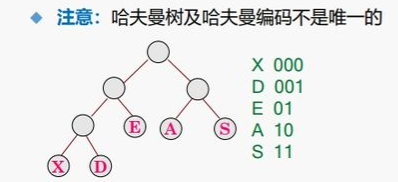
哈夫曼编码:
从根结点开始,到达某叶子结点所走过的路径(根节点到左子树为0,根节点到右子树为1),设为该叶子结点的哈夫曼编码。
图例:
1.4 并查集
①什么是并查集
并查集是线性表的一种应用,是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。常常在使用中以森林来表示。集就是让每个元素构成一个单元素的集合,也就是按一定顺序将属于同一组的元素所在的集合合并。
②并查集操作
并查集的初始化方法为先让所有的结点自成一个独立的集合,自己作为自己的簇头(是用簇头来标识集合的);若已知两个元素属于同一集合,则将这两个元素所在的集合合并。
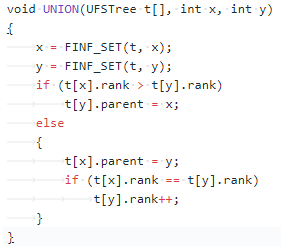
并操作:将两个元素所在的集合合并
查操作:找到给定元素的簇头
③并查集解决什么类型的问题
在很多笔试题目中,经常需要将n个不同元素划分成不相交的集合,通过一定的条件和关系让一些集合合并。在此过程中经常需要判断该元素是否属于某个集合,或查询该集合中元素的个数。适用于解决这类问题的数据结构类型称为并查集
④并查集的优势
并查集:(union-find sets)是一种简单的用途广泛的集合. 并查集是若干个不相交集合,能够实现较快的合并和判断元素所在集合的操作,应用很多,如其求无向图的连通分量个数、最小公共祖先、带限制的作业排序,还有最完美的应用:实现Kruskar算法求最小生成树。
⑤并查集的结构体

⑥并查集的查找

⑦并查集的合并
1.5.谈谈你对树的认识及学习体会
1.关于树的学习上,从遍历最基础的开始,树的很多操作都要用到递归,而递归是一件让人很头疼的事,在遇到递归函数时,经常有点摸不着头脑;
2.而要学会树的相关操作,则需要从递归遍历开始一层层深入学习,齐次我觉得可能和递归以前没有学好也有关系,可以适当看一下慕课上关于递归的视频来补充这方面缺失的知识面;
3.树的代码方面因为用到递归所以减少了不少代码量;在哈夫曼树解决修理牧场问题时,很巧妙的可以用到优先队列来解决,很大解决建树麻烦的问题;
2.PTA实验作业
2.1 二叉树(7-2 jmu-ds-二叉树叶子结点带权路径长度和)
2.1.1 解题思路及伪代码
BTree CreateBTree(int i)//建树
{
设定BTree变量BT
if(i>str.size()-1)return NULL;
if(是'#',是空节点)return NULL;
为BT开辟一个空间
BT->data=str[i];
BT的lc应该是第2i的元素
rc应该是第2i+1的元素
return BT;
}
int CalculateWpl(BTree bt, int h)//计算叶子结点带权路径长度和
{
定义h表示深度
先判断是否为空结点
if (bt == NULL)
return 0
判断是否是叶子节点
if (bt->lchild == NULL && bt->rchild == NULL)
return深度*当前data的值
非空非叶
递归访问其左右子树
return CalculateWpl(bt->lchild, h + 1) + CalculateWpl(bt->rchild, h + 1);
}
2.1.2 总结解题所用的知识点
解题需要对递归较为熟悉,并能良好掌握和运用,另外要会对叶子结点的判断,以及二叉树的创建
2.2 目录树
2.2.1 解题思路及伪代码
2.2.2 总结解题所用的知识点
3.阅读代码
3.1 题目及解题代码
题目:二叉树最大宽度
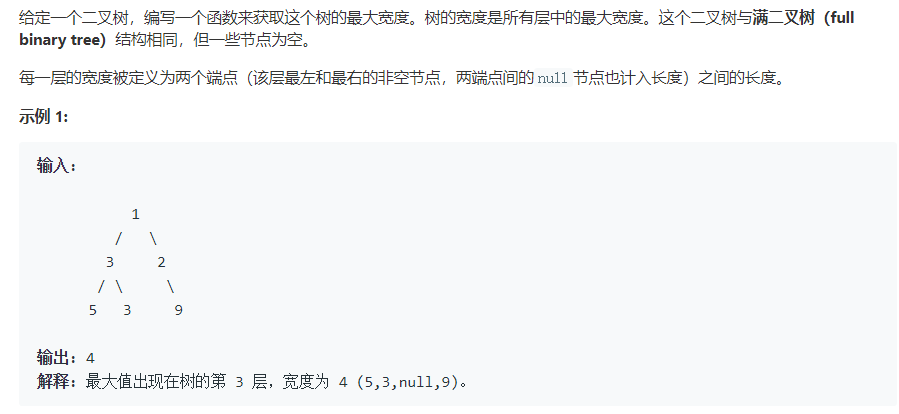

3.2 该题的设计思路及伪代码
解题思路
采用双端队列,二叉树的层次遍历。每层遍历前,在队列中清除左右两边的null指针,再计算队列长度即为该层的宽度。
伪代码

3.3 分析该题目解题优势及难点
- 有关于双端队列deque用法,即可以对队列的头尾都可以进行插入删除操作的队列。
- 本题计算二叉树的最大宽度时要考虑到结点为空时此时依旧占有一个宽度的情况,所以计算时,是从队列最左边不是NULL位置开始到最右边不是NULL结束,即为该层的最大宽度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号