promethues 之PromQL数据类型介绍(二)
promethues 之PromQL数据类型介绍(二)
1、PromQL 介绍
- PromQL是promethues 监控系统内置的一种查询语言,类似于MySQL的SQL语句,该语言仅用于读取数据。PromQL是我们学习Promethues最困难也是最重要的部分。
- 当Promethues从系统和服务收集到指标数据时,他会把数据存储在内置的时序数据库(TSDB)中,要对收集的数据进行处理,我们需要使用PromQL从TSDB中读取数据,同时可以对所选的数据执行过滤、聚合以及其他转换操作。
- 通过PromQL的学习,能够有效的构建和理解PromQL查询。可以帮助我们对报警规则、仪表盘可视化等需求。能够避免一些在使用PromQL表达式的时候遇到的一些陷阱。
2、PromQL的执行方式
PromQL的执行可以通过两种方式来触发
2.1 配置规则时自动发生
在 Prometheus 服务器中,记录规则和警报规则会定期运行,并执行查询操作来计算规则结果(例如触发报警)。该执行在 Prometheus 服务内部进行,并在配置规则时自动发生。
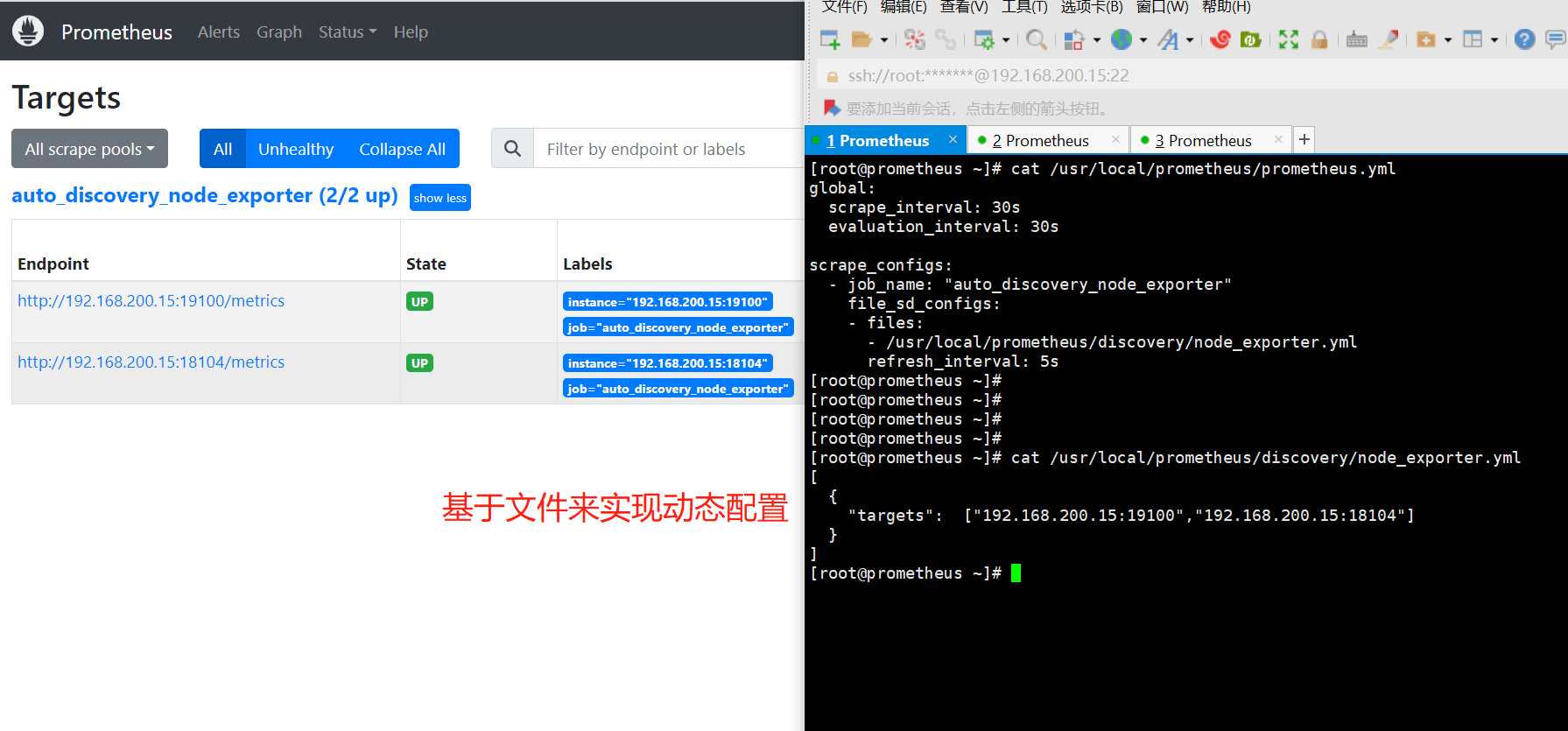
2.2 使用Promethues HTTP API 执行PromQL方式
外部用户和 UI 界面可以使用 Prometheus 服务提供的 HTTP API 来执行 PromQL 查询。这就是仪表盘软件(例如 Grafana、PromLens 以及 Prometheus 内置 Web UI)访问 PromQL 的方式。
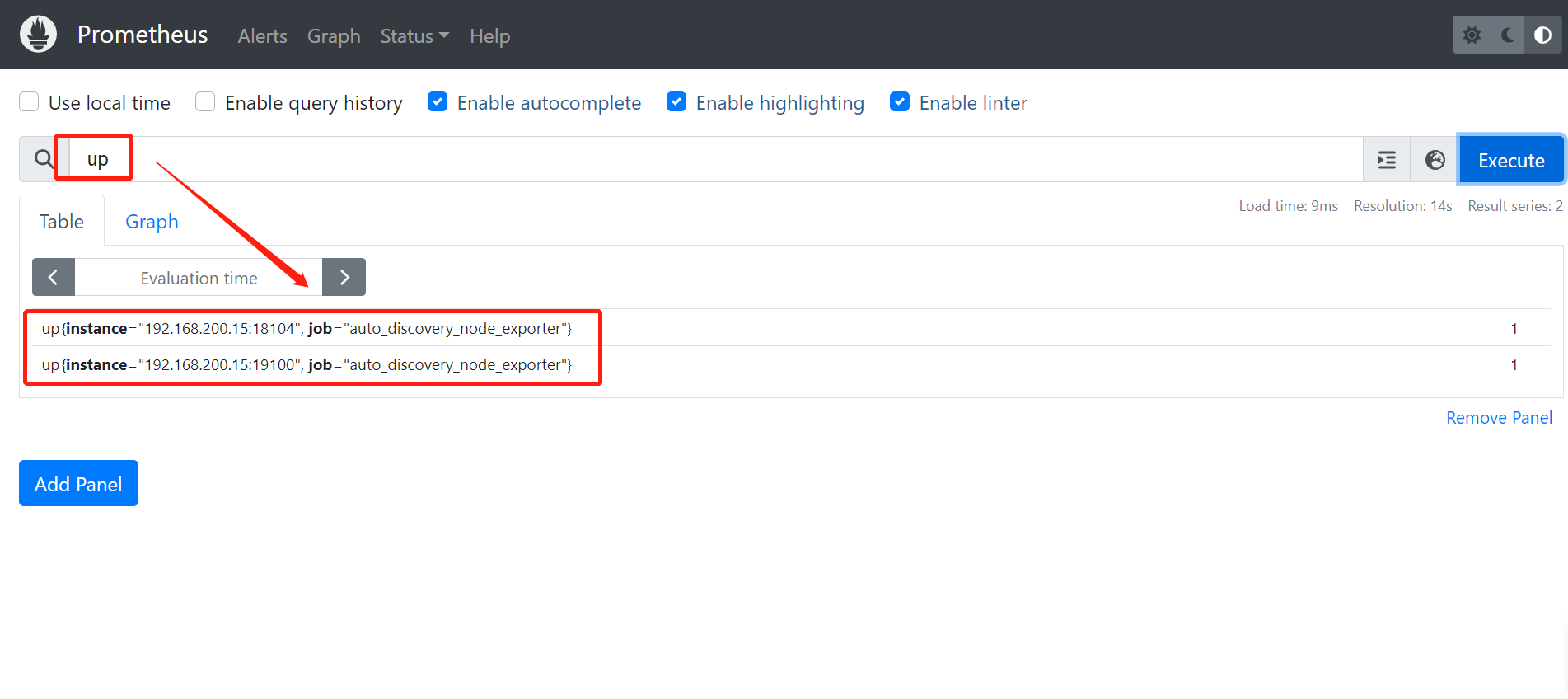
2.3 场景案例
我们可以利用PromQL来对收集的数据进行实时查询,这有助于去调式和诊断遇到的一些问题-。
我们一般也是直接使用内置的表达式在查询界面来执行这类查询:
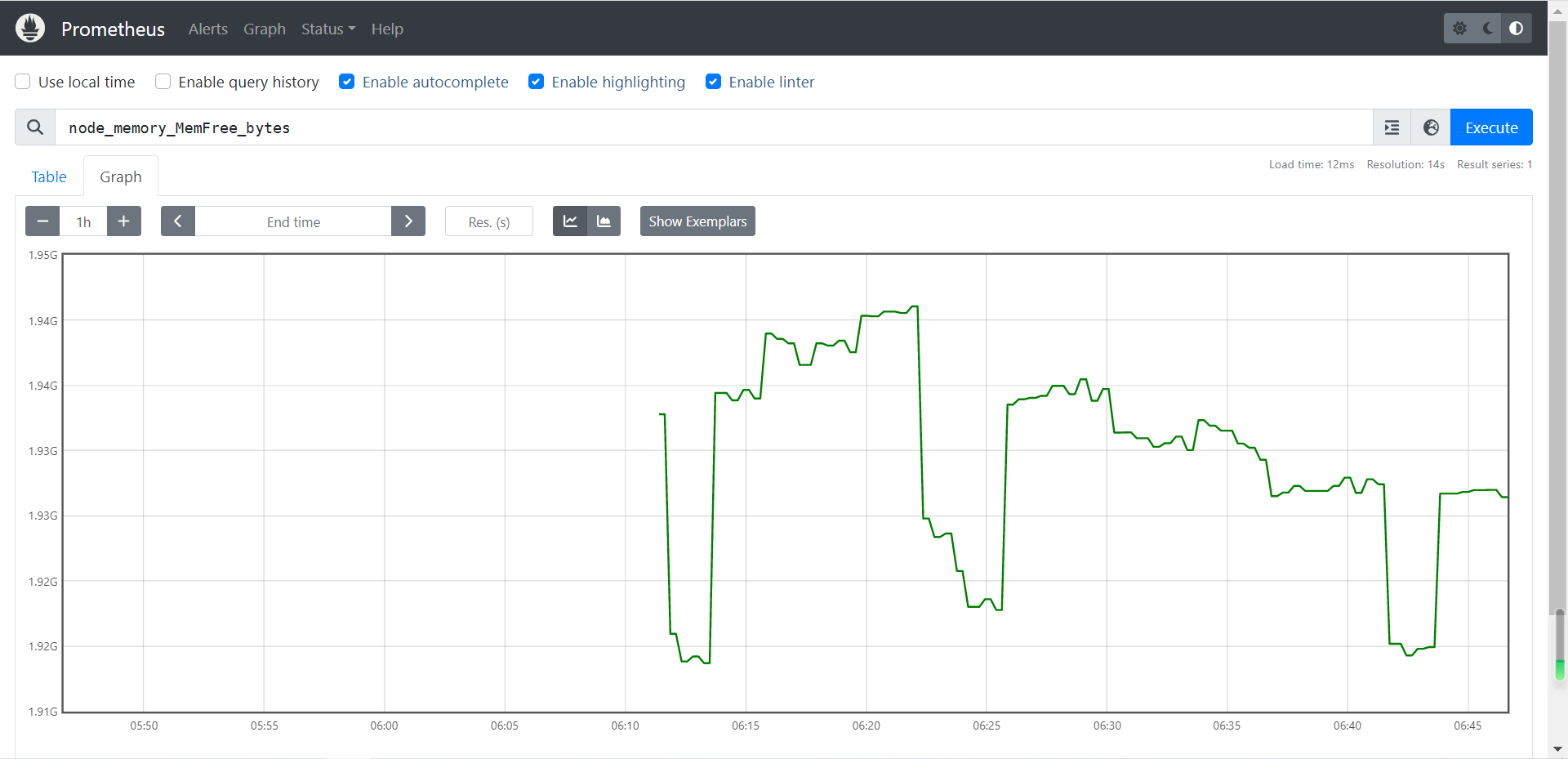
2.3.1 查看内存信息
# 查看CPU的空闲内存
node_memory_MemFree_bytes
# 查看CPU的总内存
node_memory_MemTotal_bytes
# 查看CPU的可用内存
node_memory_MemAvailable_bytes
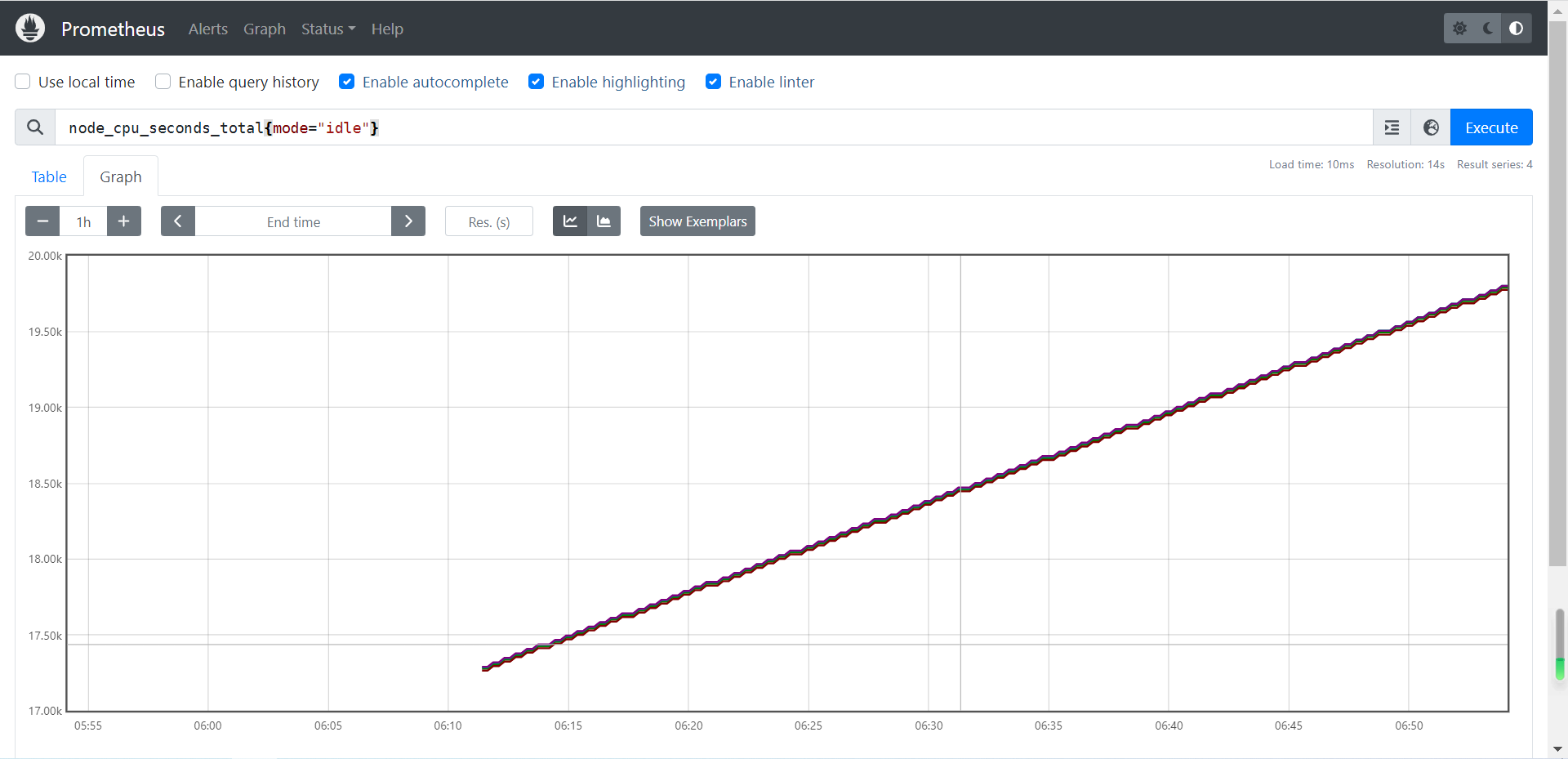
2.3.2 查看CPU信息
我们平时习惯了top,uptime,sar,vmstat,iostat这些简便的方式查看CPU使用率,往往浅尝辄止根本没有好好深入理解所谓的CPU使用率在Linux中到底是怎么回事。
# 使用标签过滤器查看所有CPU核心的空闲状态的总时间
node_cpu_seconds_total{mode="idle"}
# 使用标签过滤器查看所有CPU核心的非空闲状态的总时间
node_cpu_seconds_total{mode!="idle"}
# 使用标签过滤器查看mode名称以"i"开头的所有CPU核心
node_cpu_seconds_total{mode=~"i.*"}
# 使用标签过滤器查看除了mode名称以"i"开头的所有CPU核心
node_cpu_seconds_total{mode!~"i.*"}
# 表示查看所有CPU核心的所有状态的耗费时间
node_cpu_seconds_total
2.3.3 查看磁盘
# 查看磁盘最近10分钟总的增长量并以每秒的形式出图显式
rate(node_disk_write_time_seconds_total[10m])
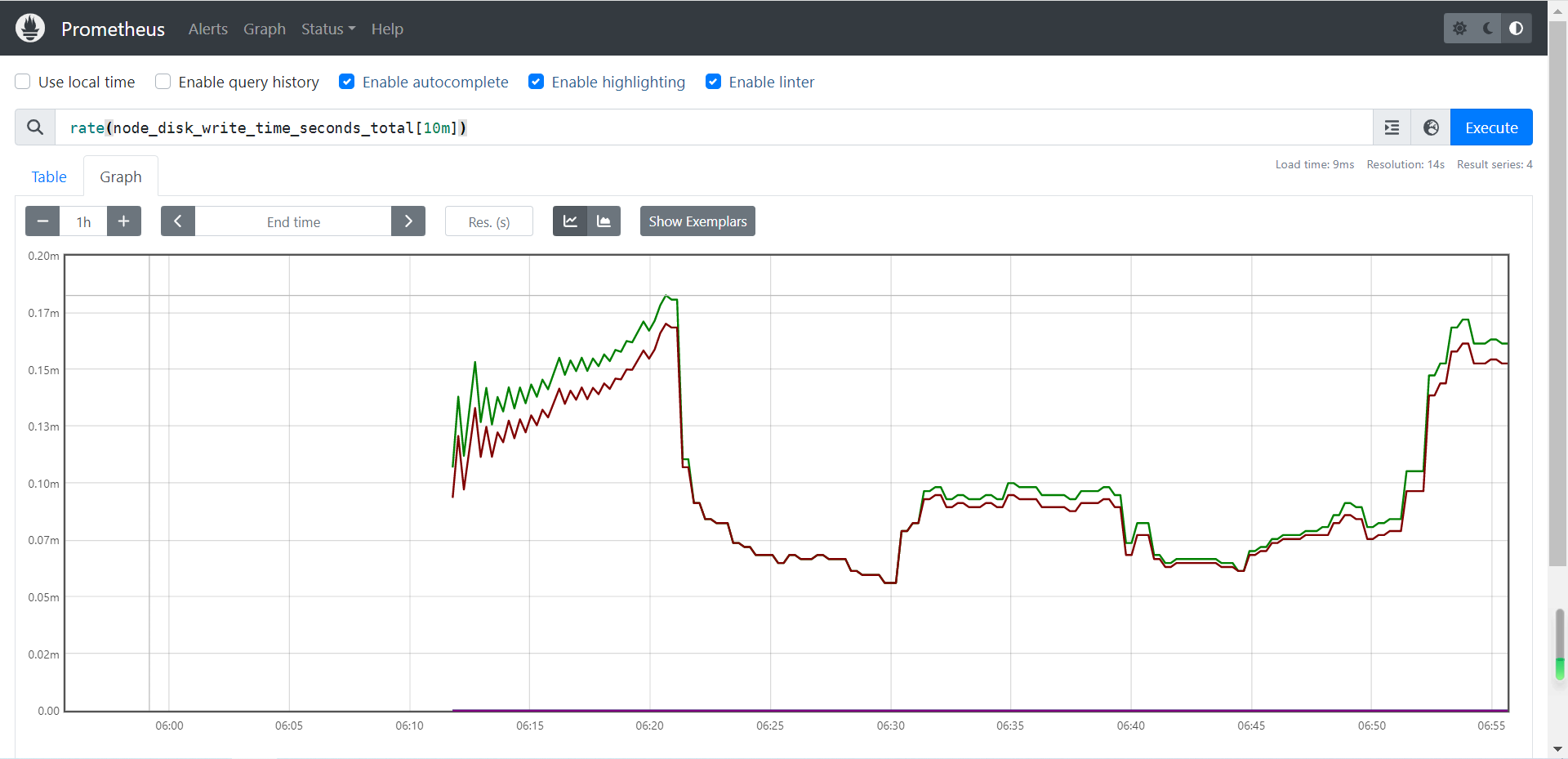
温馨提示:我们看到的图都是临时的,当关闭浏览器就不存在了,如果想要其永久存在,则可以借助grafana实现永久的图形的存储哟。
3、PromQL 中常用函数
3.1 increase函数
increase() 函数表示某段时间内数据的增量
- 当我们获取数据比较精细的时候 类似于1m取样推荐使用rate()
- 当我们获取数据比较粗糙的时候 类似于5m,10m甚至更长时间取样推荐使用increase()
表达式示例:
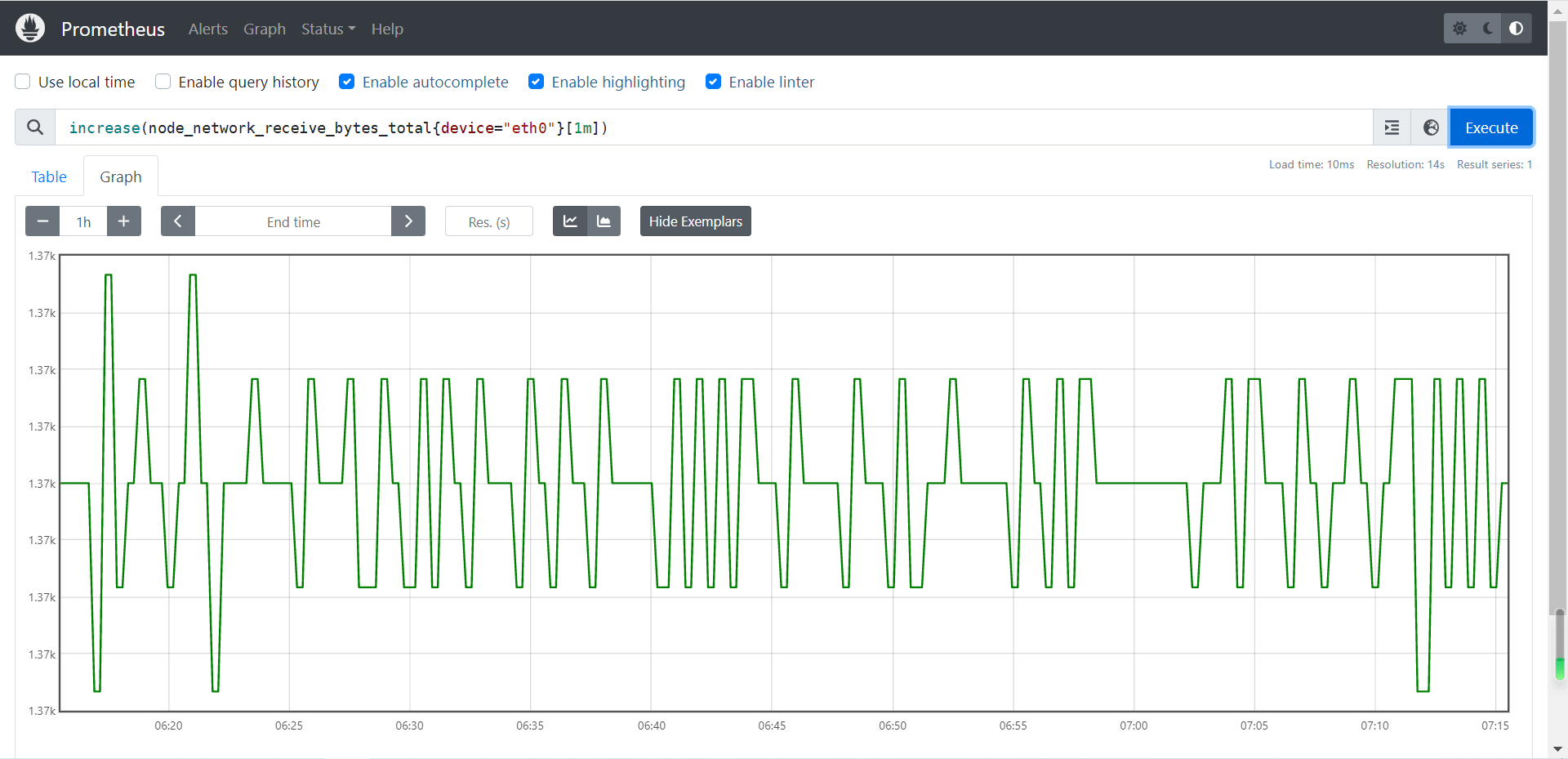
# 获取网卡1m内流量增量
increase(node_network_receive_bytes_total{device="eth0"}[1m])
3.2 sum函数
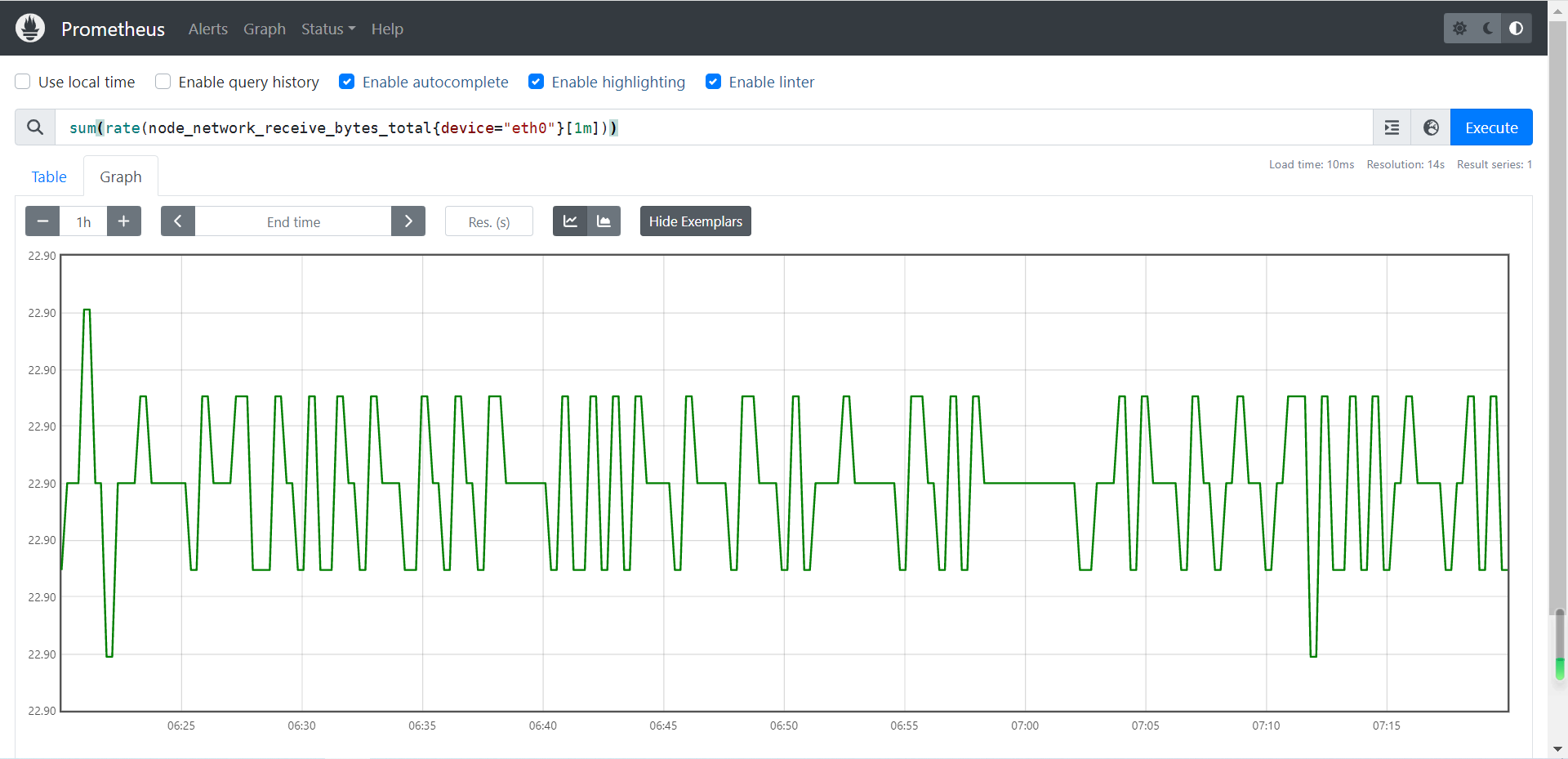
sum()函数就是求和函数前面已经说过,注意点是当你使用sum后是将所有的监控的服务器的值进行取和,所以当我们只看某一台时需要进行拆分
拆分常用方法:
- 1 by increase()
- 2 by (cluster_name) 属于自定义标签不是标准标签,我们可以手动将不痛功能的服务器进行分组展示
表达式示例:
sum(rate(node_network_receive_bytes_total{device="eth0"}[1m]))
3.3 by函数
by函数:将数据进行分组,类似于MySQL的"group by"。
举个例子:
- by (instance):
- 这里的"instance"代表的是机器名称,意思是将数据按照instance标签进行强行拆分。
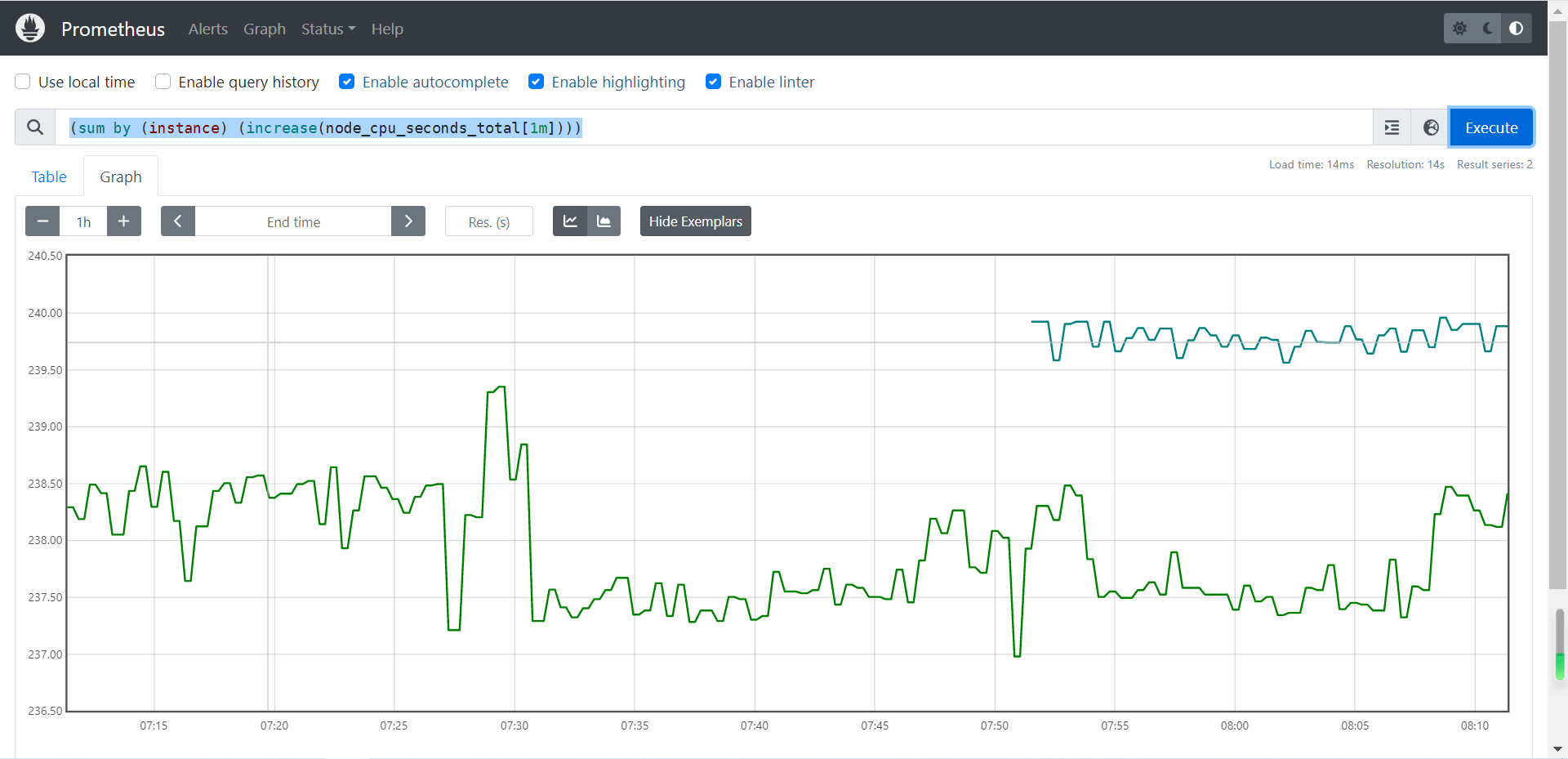
- 该函数通常会和sum函数搭配使用,比如"
(sum(increase(node_cpu_seconds_total[1m])) by (instance))",表示把sum函数中累加和按照"instance"(机器名称)强行拆分成多组数据。当然,如果只有一个机器名称的话,你会发现只有一组数据,因此从结果上可能看不到明显的变化哟。
温馨提示:instance是node_exporter内置的标签,当然,我们也可以自定义标签,比如根据生产环境中不同的集群添加相应的标签。比如基于自定义的"cluster_name"标签进行分组等。
表达式示例:
(sum(increase(node_cpu_seconds_total[1m])) by (instance))
3.4 rate 函数
它的功能是按照设置的一个时间段,取counter在这个时间段中的平均每秒的增量。因此是专门搭配counter类型数据使用的函数。
- increase函数和rate函数如此相似如何选择?
- 对于采集频率较低的数据采用建议使用increase函数,因为使用rate函数可能会出现断点(比如按照5分钟采样数据量较小的场景,以采集硬盘可用容量为例,可能会出现某次采集数据未采集到的情况,因为会按照平均每秒来计算最终的增量)的情况;
- 对于采集频率较高的数据采用建议使用rate函数,比如对CPU,内存,网络流量等都可以基于rate函数来采样,当然,硬盘也是可以用rate函数来采样的哟;
温馨提示:在实际工作中,我们取监控频率为1分钟还是5分钟这取决与我们对于监控数据的敏感程度来挑选。
表达式示例:
# 获取CPU总使用时间在1分钟内的增加的总量并除以60秒,计算的是每秒的增量
rate(node_cpu_seconds_total[1m])
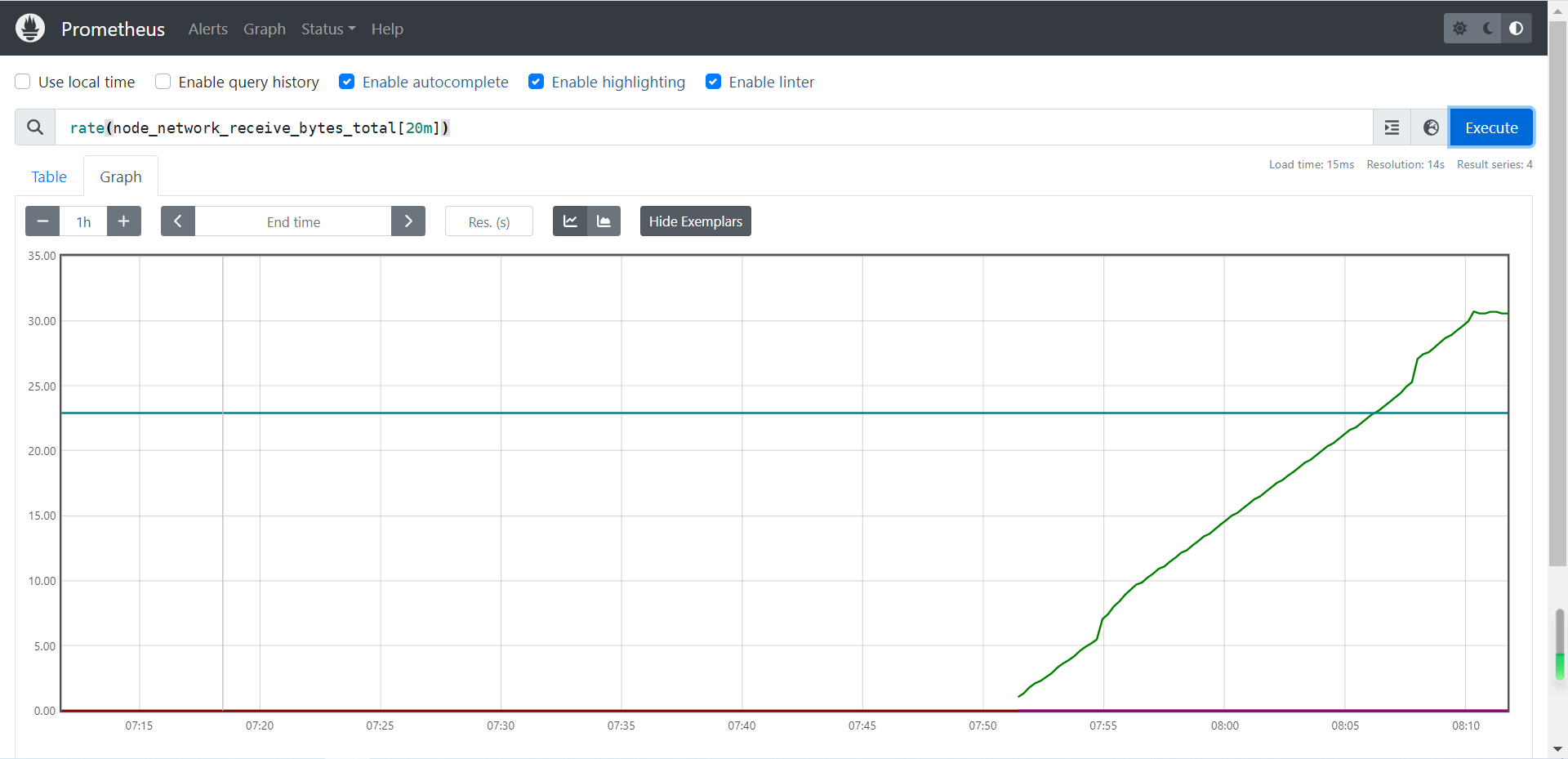
# 获取一分钟内网络接收的总量。查看的时间越短,某一瞬间的突起或降低在成图的时候会体现的更细致,更铭感
rate(node_network_receive_bytes_total[1m])
# 获取二十分钟内网络接收的总量
rate(node_network_receive_bytes_total[20m])
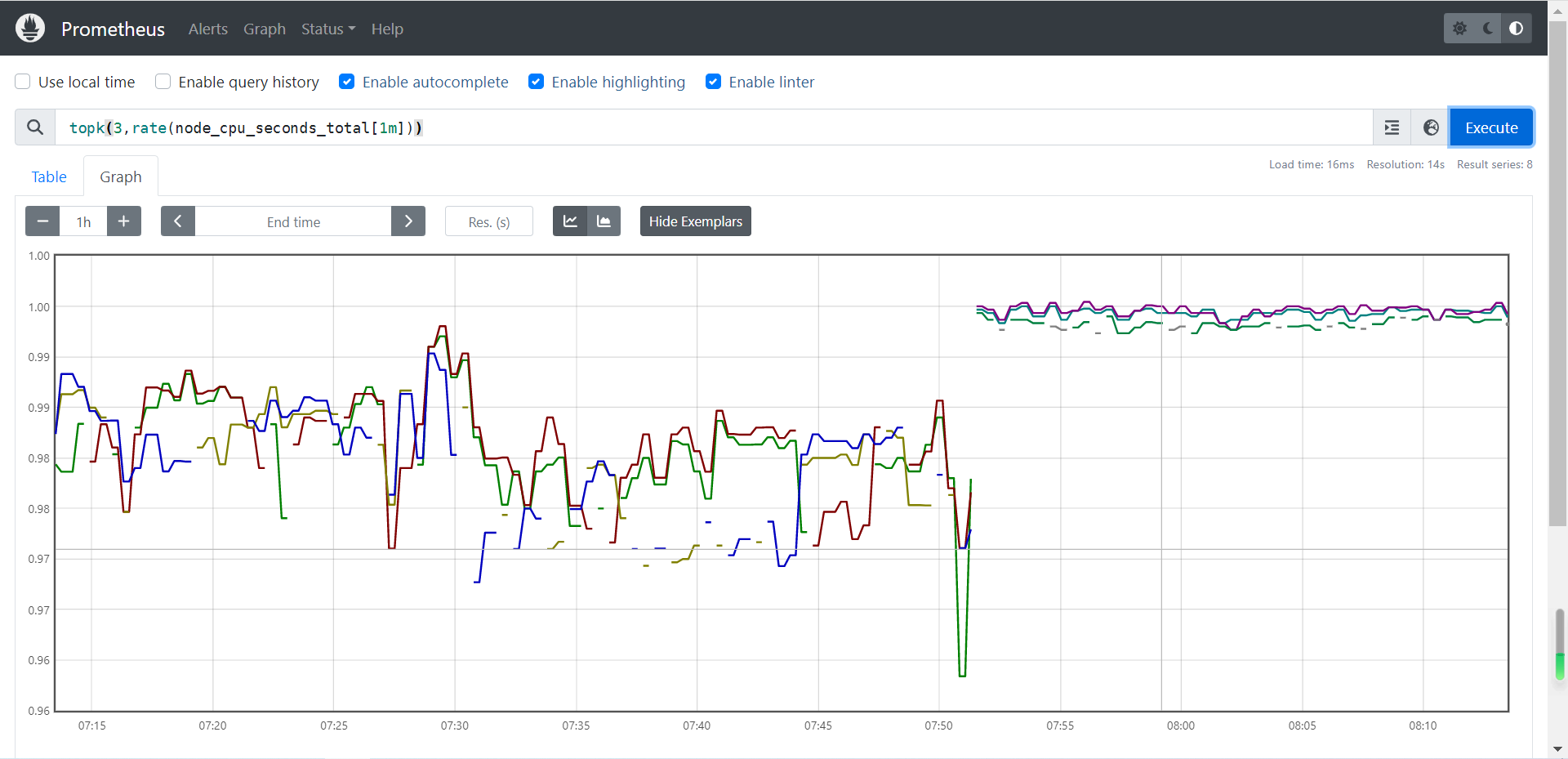
3.5 topk 函数
取前几位的最高值。实际使用的时候一般会用该函数进行瞬时报警,而不是为了观察曲线图。
温馨提示:如下图所示,我们通常使用topk只会关注"Console"中的瞬时结果,不太会关心Graph的出图效果,因为关注他并没有太大意义,存在太多的断点啦!下图之所以会出现中断的情况,是因为在20分钟内这一刻的数据其并没有排进top3,自然就会出现断点的状况。
表达式示例:
topk(3,rate(node_cpu_seconds_total[1m]))
3.6 count 函数
count() 是找出当前或者历史数据中某个key的数值大于或小于某个值的统计
把数值符合条件的,输出数目进行累计加和。一般用它进行一些模糊的监控判断。比如说企业中有100台服务器,那么只有10台服务器CPU使用率高于80%的时候,这个时候不需要报警,当符合80%CPU的服务器数量超过70台的时候那么就触发报警。
表达式示例:
count(oldboyedu_tcp_wait_conn > 500)
我们假设oldboyedu_tcp_wait_conn是咱们自定义的KEY,上述案例是找出当前(或者历史的)当前TCP等待数大于500的机器数量。
更多函数请参考官方文档:https://prometheus.io/docs/prometheus/latest/querying/functions/
4、企业级监控案例
企业基于Prromethues函数及PromQL查询
4.1 CPU相关
详细步骤:
- 我们需要先找到查看CPU的key名称
- node_cpu_seconds_total
- 过滤cpu的空闲("idle")时间和全部CPU时间,使用"{}"做过滤
node_cpu_seconds_total{mode="idle"}:过滤空闲的CPU时间。node_cpu_seconds_total{}:此处是可用省略"{}"的哟,因为里面没有任何参数,代表获取CPU的所有状态时间。- 把1分钟的增量的CPU时间取出来
increase(node_cpu_seconds_total{mode="idle"}[1m]):1分钟内CPU空闲状态的增量。increase(node_cpu_seconds_total[1m]):1分钟内CPU所有状态的增量。- 将结果集进行加和统计
sum(increase(node_cpu_seconds_total{mode="idle"}[1m])):将1分钟内CPU空闲状态的增量数据进行加和计算。sum(increase(node_cpu_seconds_total[1m])):将1分钟内CPU所有状态的增量数据进行加和计算。
温馨提示:细心的小伙伴可能已经发现了,这里会有一个坑,因为它不光把每一台机器的多个核加载一起,还会把所有机器的CPU也全都加到了一起,这意味着变成了集群CPU的平均值了,需要解决该问题。- 按照"instance"(机器名称)强行拆分成多组数据
sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance):将1分钟内CPU空闲状态的增量数据进行加和计算并按照"increase"(机器名称)强行拆分成多组数据。sum(increase(node_cpu_seconds_total[1m])) by (instance):将1分钟内CPU所有状态的增量数据进行加和计算并按照"increase"(机器名称)强行拆分成多组数据。- 计算CPU空闲时间的百分比
sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance)- 计算CPU使用率,计算公式: "(1 - CPU空闲时间的百分比) * 100%"。
(1 - ((sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)) / (sum(increase(node_cpu_seconds_total[1m])) by (instance)))) * 100
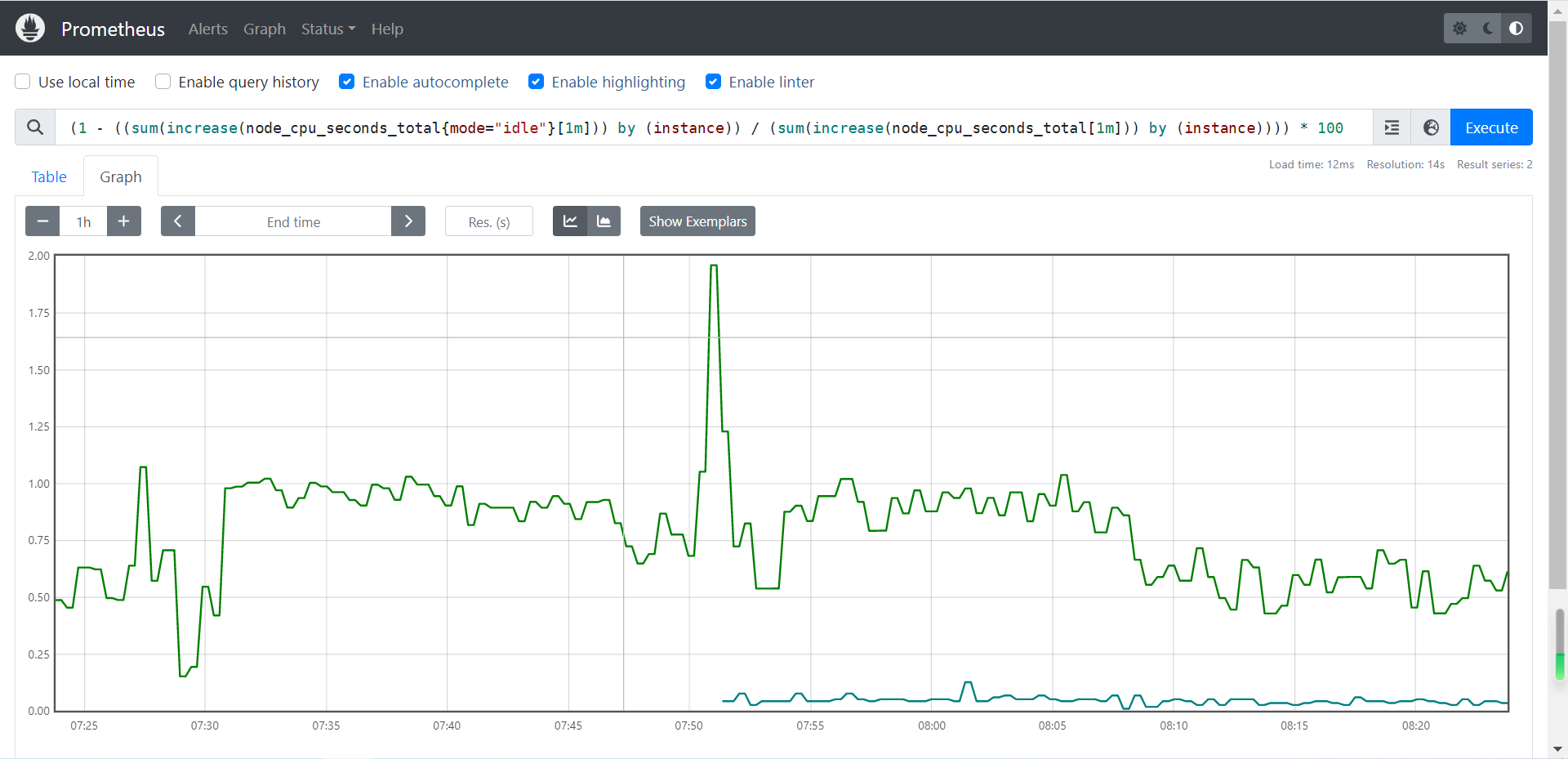
4.1.1 计算各节点的CPU的总使用率
(1 - ((sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)) / (sum(increase(node_cpu_seconds_total[1m])) by (instance)))) * 100
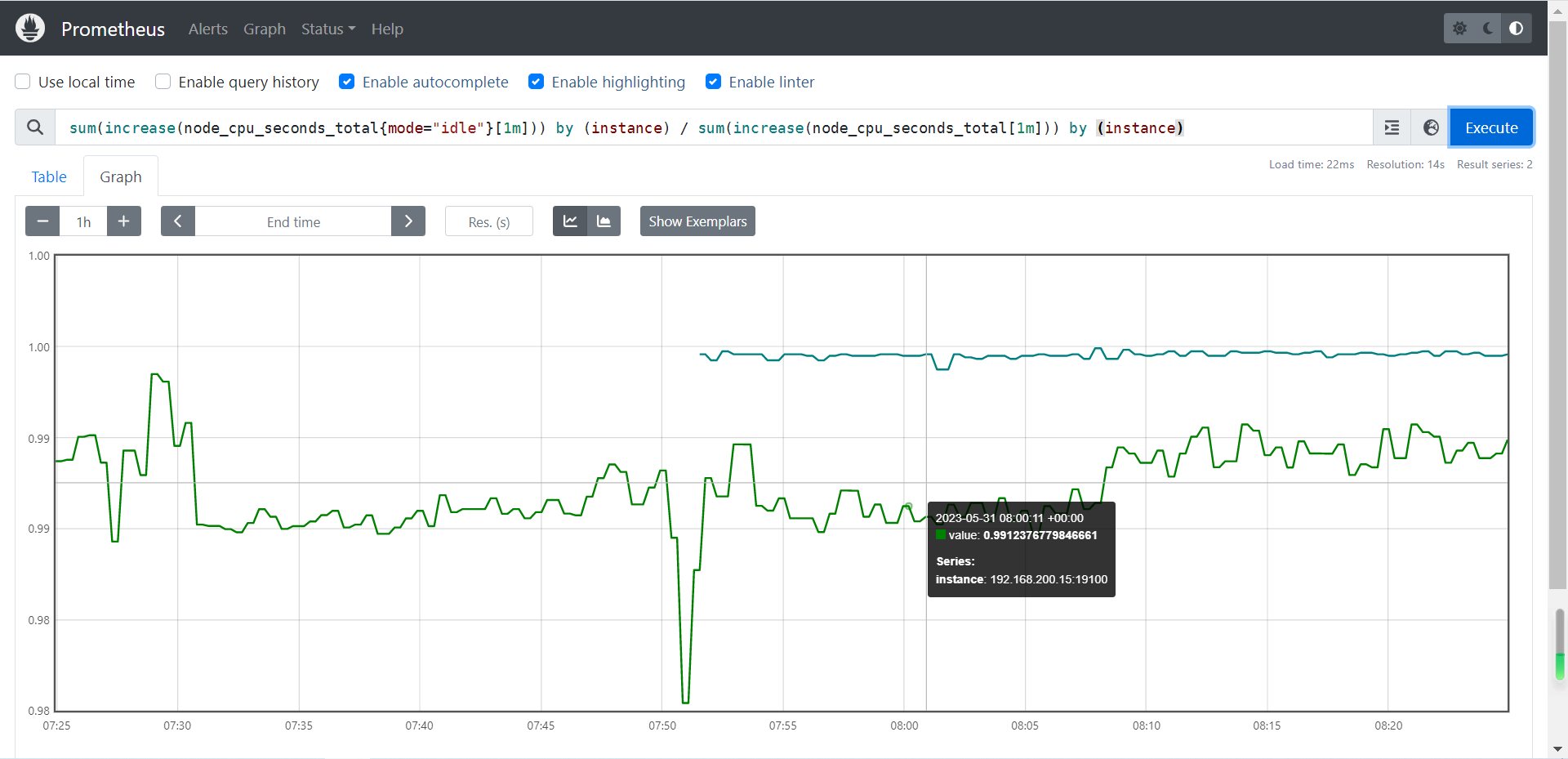
4.1.2 计算CPU空闲时间的百分比
sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance)
4.1.3 计算用户态的CPU使用率
sum(increase(node_cpu_seconds_total{mode="user"}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance) * 100
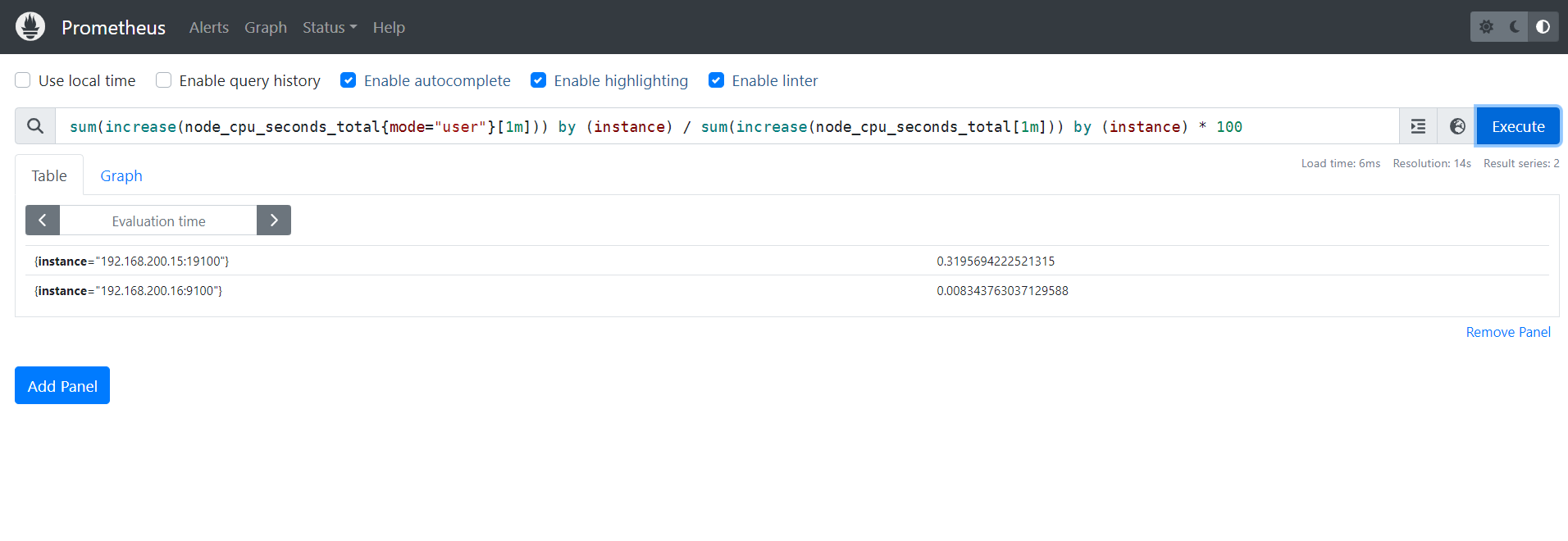
4.1.4 计算内核态的CPU使用率
sum(increase(node_cpu_seconds_total{mode="system"}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance) * 100
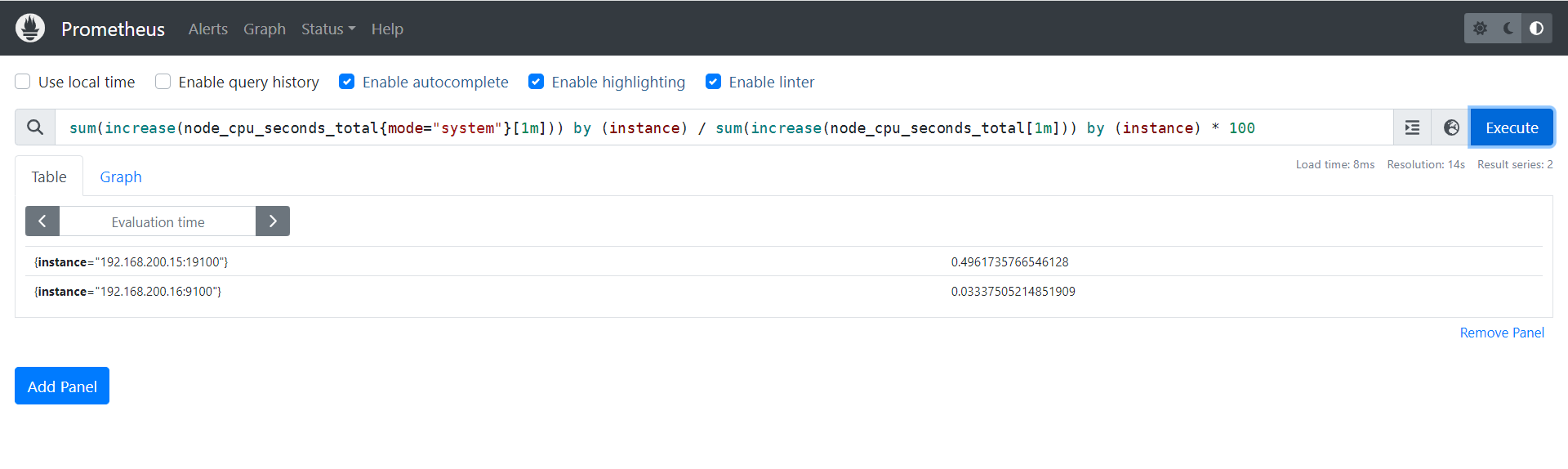
4.1.5 计算IO等待的CPU使用率
sum(increase(node_cpu_seconds_total{mode="iowait"}[1m])) by (instance) / sum(increase(node_cpu_seconds_total[1m])) by (instance) * 100
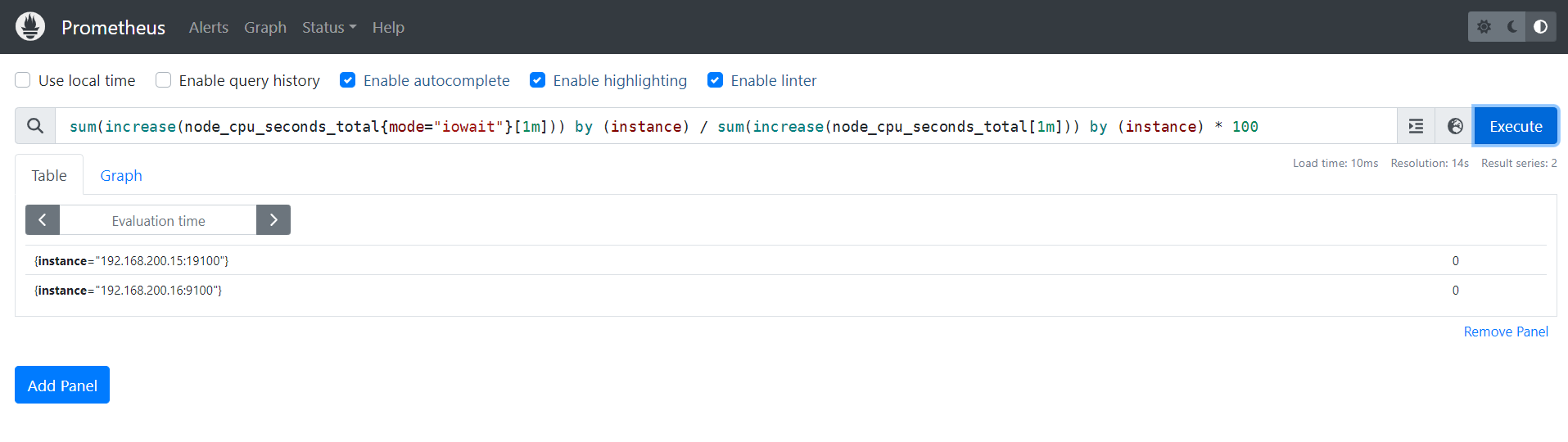
4.2 内存相关
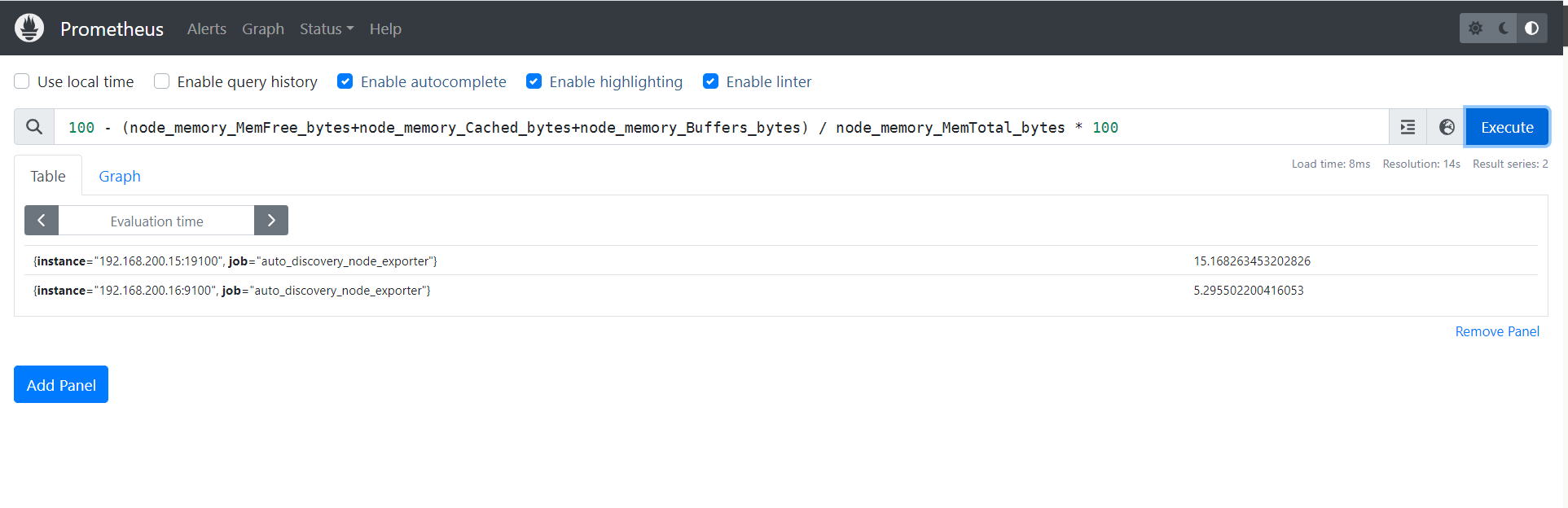
4.2.1 内存使用率
100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100
4.2.2 空闲内存剩余率
(node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100
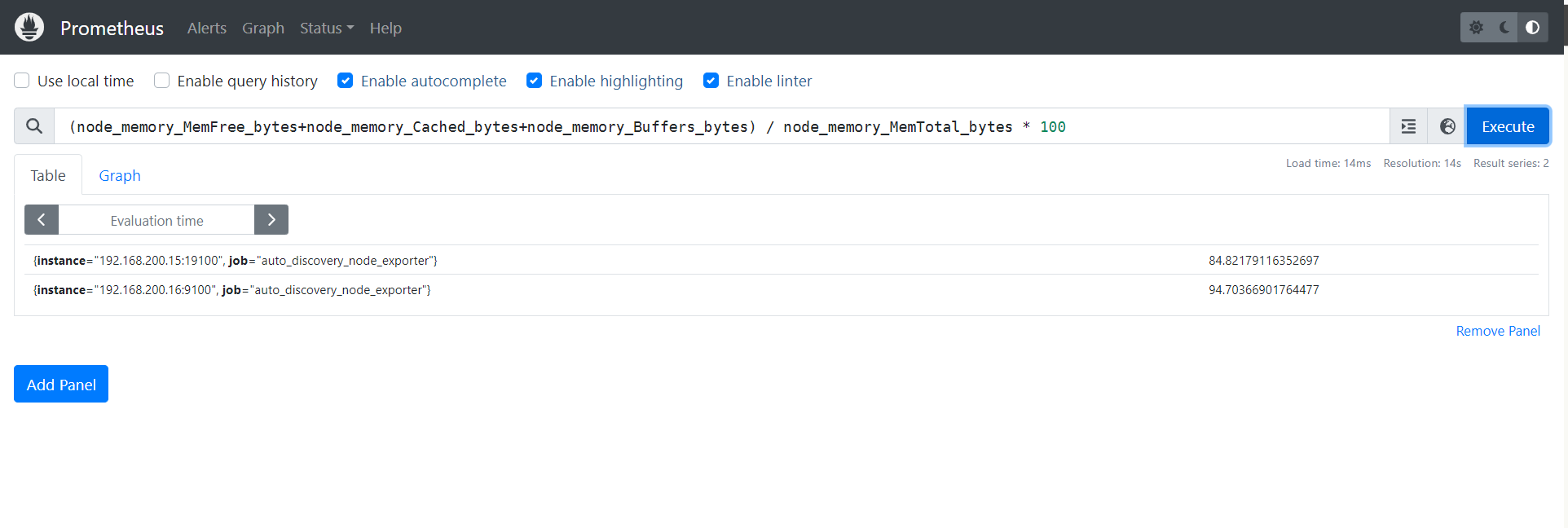
4.3 磁盘相关
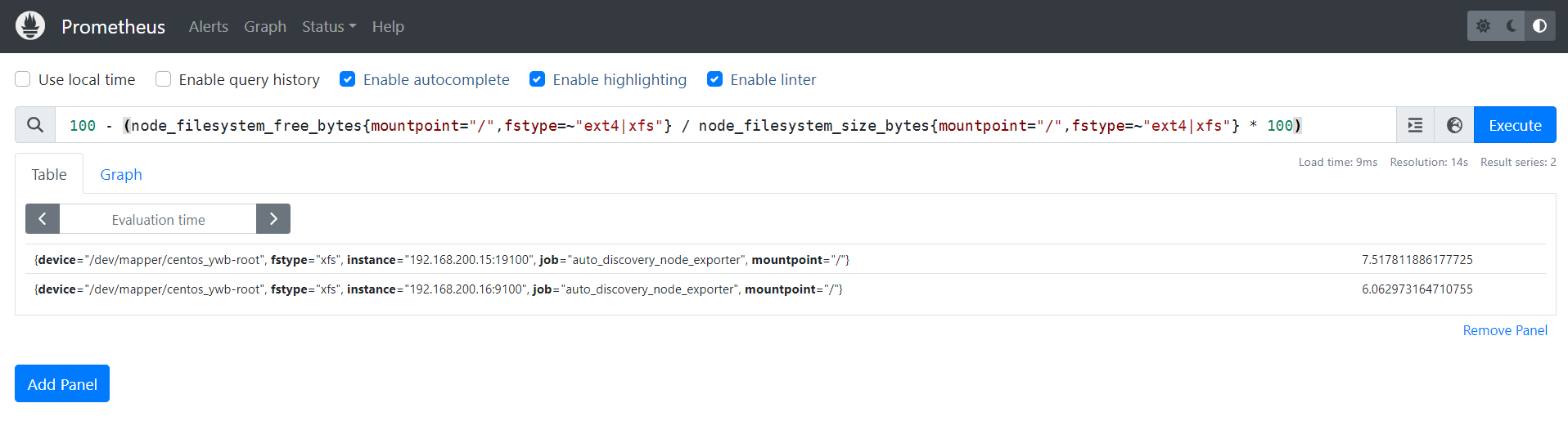
4.3.1 磁盘使用率
100 - (node_filesystem_free_bytes{mountpoint="/",fstype=~"ext4|xfs"} / node_filesystem_size_bytes{mountpoint="/",fstype=~"ext4|xfs"} * 100)
4.3.2 查看磁盘小于90%的系统
(node_filesystem_free_bytes / node_filesystem_size_bytes) < 0.90
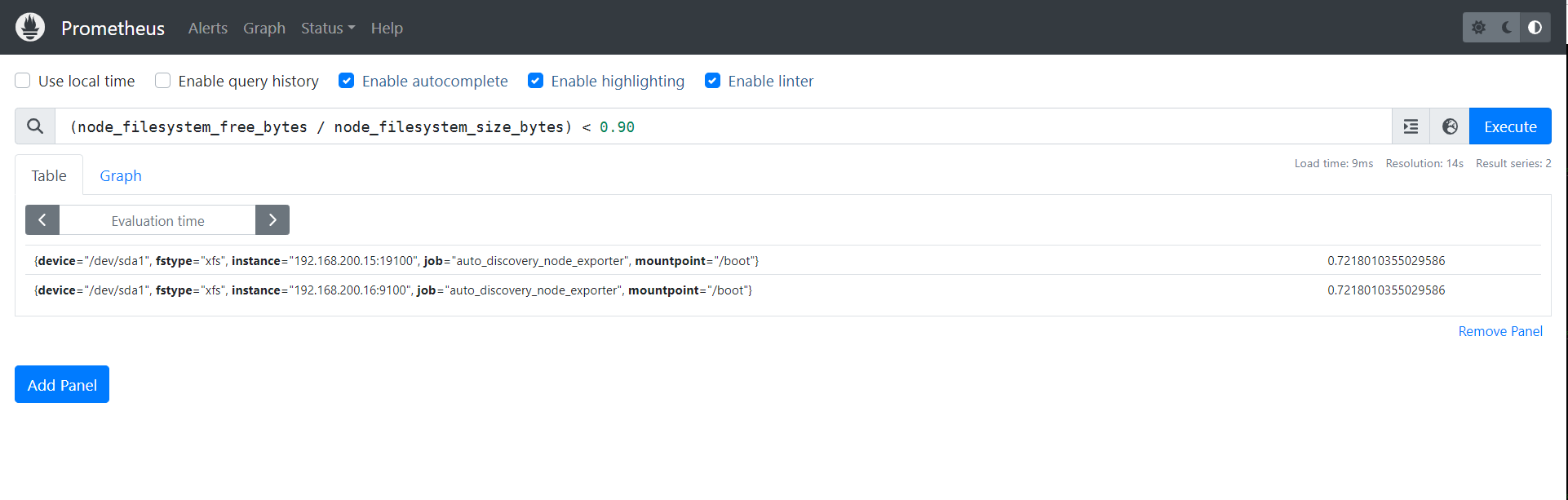
温馨提示:
- 生产环境中建议大家将0.95改为0.20,表示当空闲硬盘小于20%的时候就显示在图上;
- 我之所以些0.95是因为我的空闲硬盘挺大的,为了让大家看到出图的效果而已
4.3.3 监控磁盘IO使用情况
((rate(node_disk_read_bytes_total[1m]) + rate(node_disk_written_bytes_total[1m]))/1024/1024) > 0
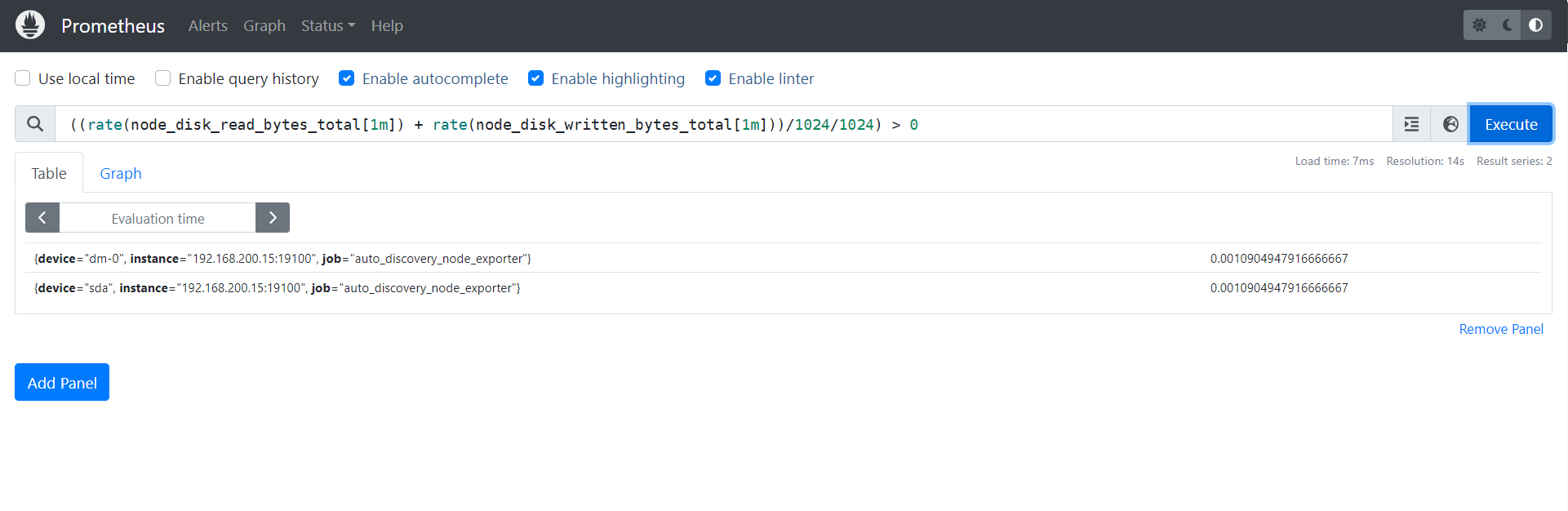
温馨提示:
- 对于硬盘I/O是监控硬盘读写量的监控。上面的公式将默认的Bytes单位转换成MB单位啦。
- 如果磁盘I/O飙高,这意味着CPU的iowait也会飙高,这可能会触发大批量的报警,因此我们要实现一个"真实链路报警",从根源切断无效的报警。
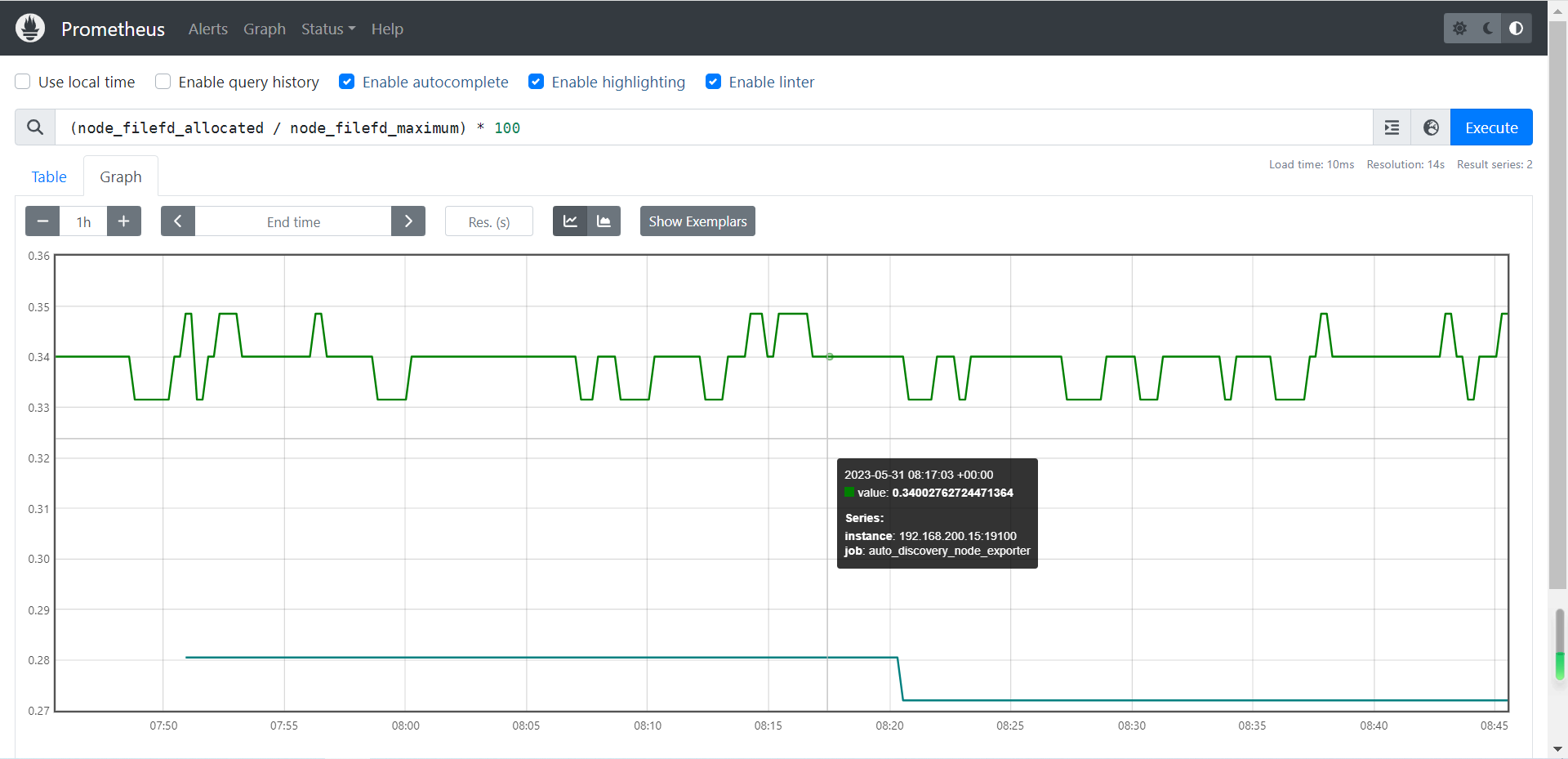
4.4 连接数使用率
参考案例:
(node_filefd_allocated / node_filefd_maximum) * 100
node_filefd_allocated:已分配的文件描述符。
node_filefd_maximum:一个进程运行最大打开文件描述符的总量。
5 安装pushgateway
5.1 安装包下载
pushgateway包 下载链接
[root@prometheus 1]# wget https://github.com/prometheus/pushgateway/releases/download/v1.6.0/pushgateway-1.6.0.linux-amd64.tar.gz
5.2 解压使用
[root@prometheus ~]# tar xf pushgateway-1.6.0.linux-amd64.tar.gz
[root@prometheus ~]# mv pushgateway-1.6.0.linux-amd64 /usr/local/pushgateway
5.3 后台启动
[root@prometheus ~]# cd /usr/local/pushgateway/
[root@prometheus pushgateway]# nohup ./pushgateway &>/var/log/pushgateway.log &
5.4 配置监控的对象
[root@prometheus ~]# vim /usr/local/prometheus/prometheus.yml
[root@prometheus ~]# tail -4 /usr/local/prometheus/prometheus.yml
- job_name: "pushgateway"
file_sd_configs:
- files:
- /usr/local/prometheus/discovery/pushgateway.yml
[root@prometheus ~]# cat /usr/local/prometheus/discovery/pushgateway.yml
[
{
"targets": ["192.168.200.15:9091"]
}
]
5.5 重启prometheus
[root@prometheus ~]# ps -ef|grep prometheus|grep -v grep|awk '{print $2}'|xargs -i kill -9 {}
[root@prometheus ~]# cd /usr/local/prometheus
[root@prometheus prometheus]# nohup ./prometheus &>/var/log/prometheus.log &
6 编写脚本通过pushgateway传递数据
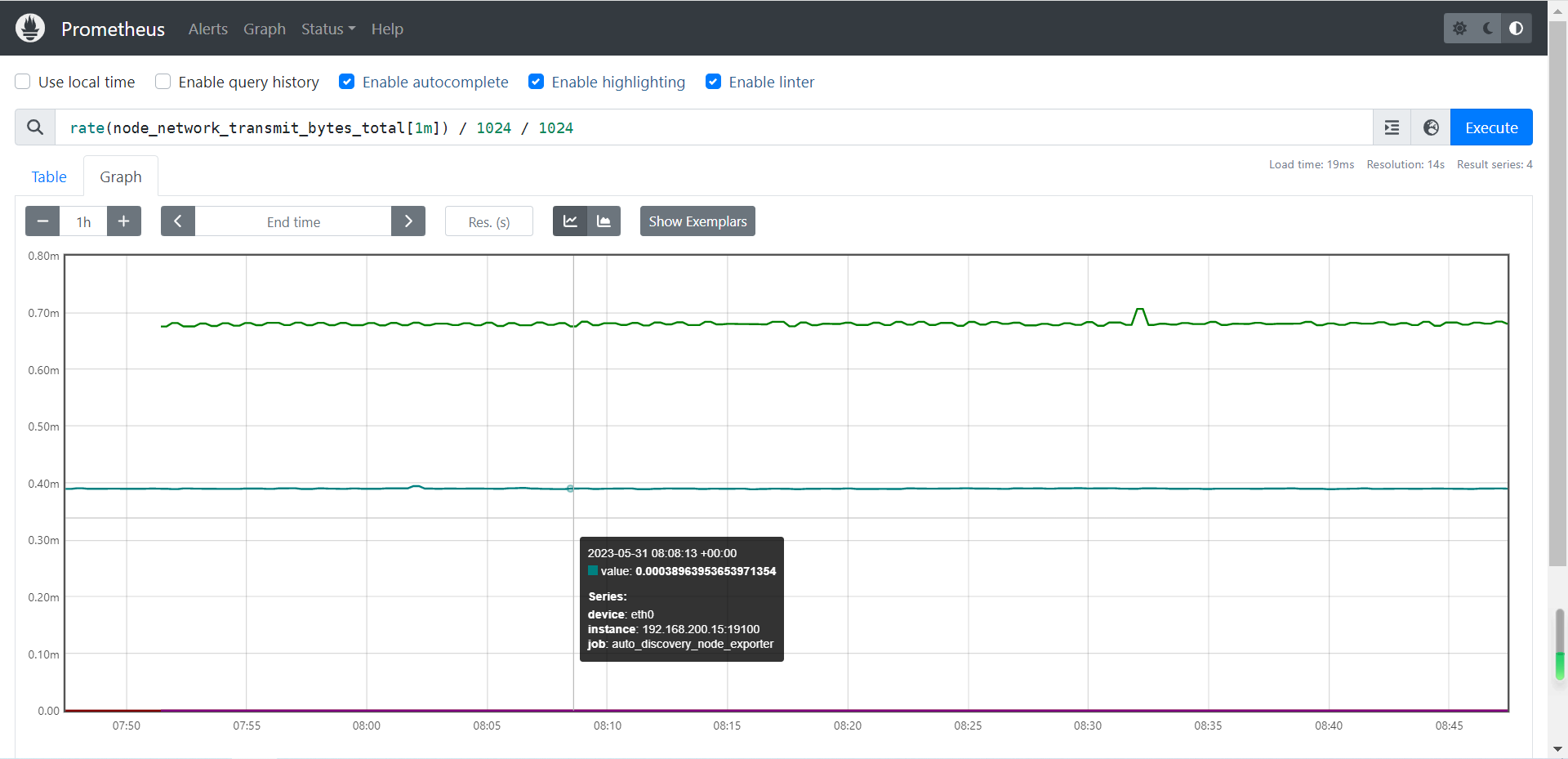
6.1 监控网络I/O
参考案例:
rate(node_network_transmit_bytes_total[1m]) / 1024 / 1024
node_network_transmit_bytes_total:网络传输字节数
6.2 网络延迟及丢包率监控(脚本)
(1)编写脚本
[root@prometheus ~]# mkdir -p /usr/local/node_exporter/script/
[root@prometheus ~]# vim /usr/local/node_exporter/script/network_delay.sh
[root@prometheus ~]# cat /usr/local/node_exporter/script/network_delay.sh
#!/bin/bash
# 以点号作为分割只取第一段作为本机的主机标签
instance_name=`hostname -f | cut -d '.' -f 1`
# 要求机器名不能是"localhost"不然标签就没有区分了
if [ $instance_name == "localhost" ]
then
echo "Must FQDN hostname"
exit
fi
# 指定需要ping的主机
monitoring_site="www.baidu.com"
# 获取丢包率相关字段
package_loss_rate=`timeout 5 ping -q -A -s 500 -W 1000 -c 100 $monitoring_site | grep transmitted | awk '{print $6}'`
# 获取延迟情况的相关字段(本质上是执行ping命令所耗费的时间哟~)
delay_time=`timeout 5 ping -q -A -s 500 -W 1000 -c 100 $monitoring_site | grep transmitted | awk '{print $10}'`
# 获取数字类型
package_loss_rate_number=`echo $package_loss_rate | sed "s/%//g"`
delay_time_number=`echo $delay_time | sed "s/ms//g"`
# 将数据上传到pushgateway
echo "lyly_linux_package_loss_rate_$instance_name $package_loss_rate_number" | curl --data-binary @- http://prometheus:9091/metrics/job/lyly_linux_package_loss_rate_$instance_name/instance/localhost:9092
echo "lyly_linux_delay_time_$instance_name $delay_time_number" | curl --data-binary @- http://prometheus:9091/metrics/job/lyly_linux_package_loss_rate_$instance_name/instance/localhost:9092
(2)为脚本添加执行权限
[root@prometheus ~]# chmod +x /usr/local/node_exporter/script/network_delay.sh
(3)编写周期性任务
[root@prometheus ~]# crontab -l
...
# 网络延迟及丢包率监控
* * * * * /usr/local/node_exporter/script/network_delay.sh
* * * * * (sleep 10;/usr/local/node_exporter/script/network_delay.sh)
* * * * * (sleep 20;/usr/local/node_exporter/script/network_delay.sh)
* * * * * (sleep 30;/usr/local/node_exporter/script/network_delay.sh)
* * * * * (sleep 40;/usr/local/node_exporter/script/network_delay.sh)
* * * * * (sleep 50;/usr/local/node_exporter/script/network_delay.sh)
(4)在Prometheus server中查看KEY
lyly_linux_package_loss_rate_prometheus
lyly_linux_delay_time_prometheus
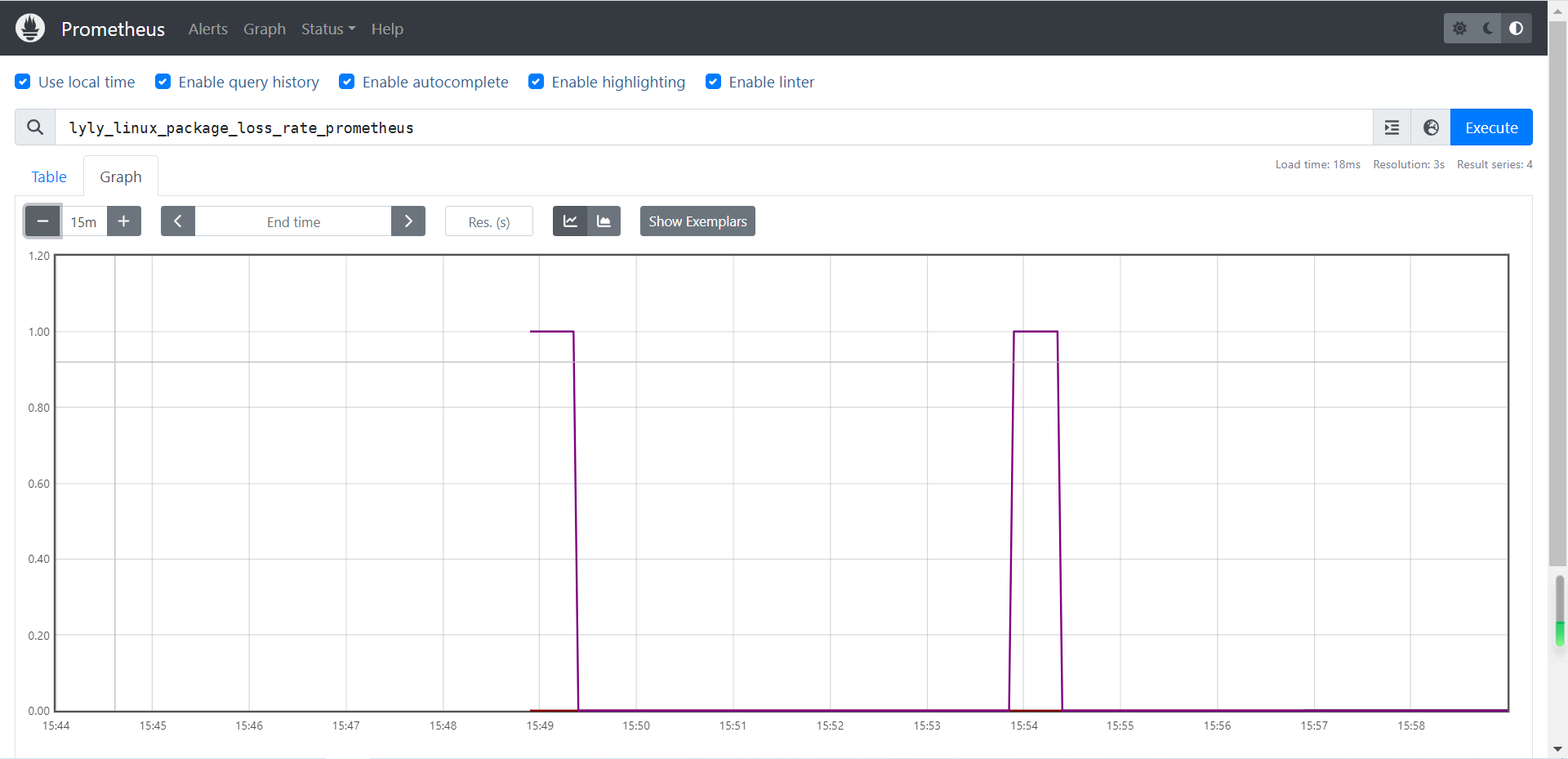
温馨提示:对于较多的网络监控我建议还是使用专业的smokeping监控系统,尤其是在IDC公司,smokeping基本上是必用软件哟。
6.3 监控TCP状态(脚本)
(1)编写采集脚本
[root@prometheus ~]# vim /usr/local/node_exporter/script/node_exporte.sh
[root@prometheus ~]# cat /usr/local/node_exporter/script/node_exporte.sh
#!/bin/bash
# 以点号作为分割只取第一段作为本机的主机标签
instance_name=`hostname -f | cut -d '.' -f 1`
# 要求机器名不能是"localhost"不然标签就没有区分了
if [ $instance_name == "localhost" ]
then
echo "Must FQDN hostname"
exit
fi
# 定义Prometheus抓取的KEY值,用于保存TCP的wait状态相关的连接(connections)
label="lyly_tcp_wait_conn"
# 通过netstat工具抓取wait链接的数量
lyly_tcp_wait_conn=`netstat -an| grep -i wait|wc -l`
echo "$label $lyly_tcp_wait_conn" | curl --data-binary @- http://prometheus:9091/metrics/job/lyly_linux_$instance_name/instance/$instance_name
echo "$label $lyly_tcp_wait_conn":指定KEY和VALUE,注意中间是空格分割,不要尝试用其它字符分割。如果你使用":"分割,可能在Prometheus server端是无法查询到数据的哟;"curl --data-binary":表示发起的是POST请求数据为纯二进制数据。"http://prometheus:9091/metrics":表示pushgateway的服务器地址"job/lyly_linux":表示第一个标签,相当于推送到prometheus server配置文件中"prometheus.yml"中定义的job名称。该名称咱们完全是可以自定义的哟~"instance/$instance_name":推送有关于instance这个变量其对应的主机名。方便后期我们在prometheus server的WebUI界面使用{instance="server"}对主机进行过滤哟~
温馨提示:注意Prometheus server支持的数据类型,如果类型不支持,则无法在Prometheus server的Web UI中进行查看。
(2)为脚本添加执行权限
[root@prometheus ~]# chmod +x /usr/local/node_exporter/script/node_exporte.sh
(3)编写周期性任务
[root@prometheus ~]# crontab -l
...
# 监控TCP状态脚本
* * * * * /usr/local/node_exporter/script/node_exporte.sh
* * * * * (sleep 10;/usr/local/node_exporter/script/node_exporte.sh)
* * * * * (sleep 20;/usr/local/node_exporter/script/node_exporte.sh)
* * * * * (sleep 30;/usr/local/node_exporter/script/node_exporte.sh)
* * * * * (sleep 40;/usr/local/node_exporter/script/node_exporte.sh)
* * * * * (sleep 50;/usr/local/node_exporter/script/node_exporte.sh)
(4)在Prometheus server中查看KEY
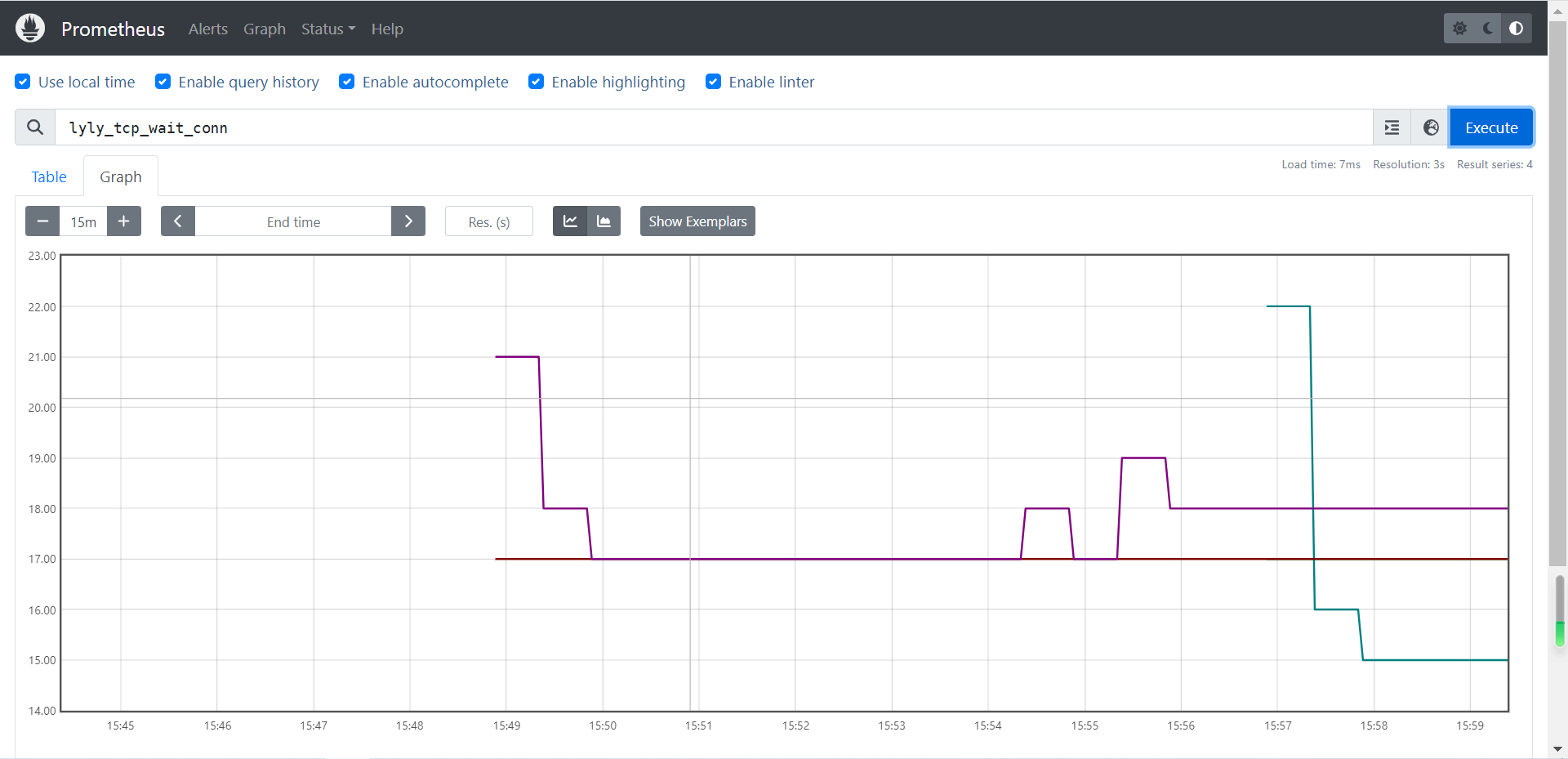
lyly_tcp_wait_conn

 浙公网安备 33010602011771号
浙公网安备 33010602011771号