
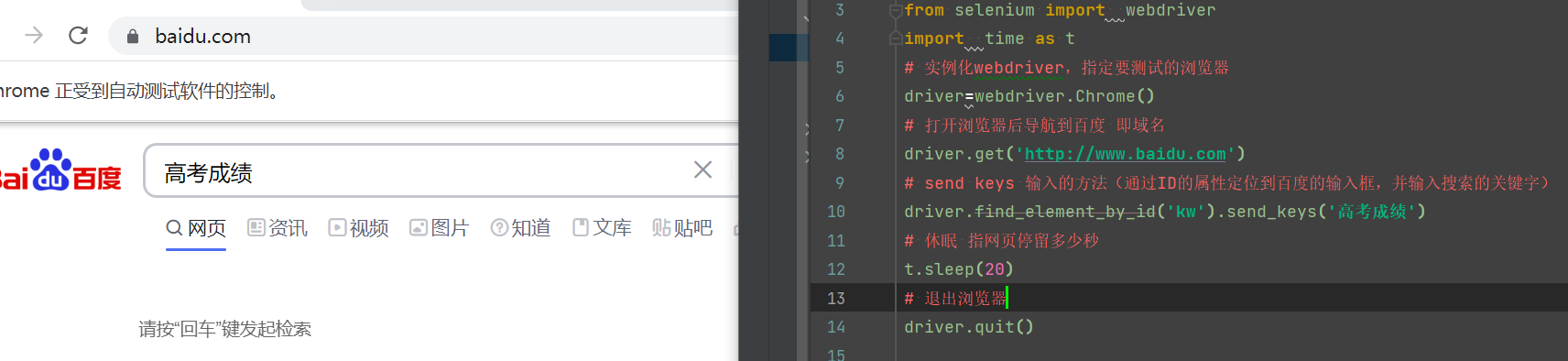
selenium-1
UI自动化测试
一、元素定位
先导入 webdriver
from selenium import webdriver
import time as t
实例化webdriver,指要测试的浏览器
driver=webdriver.Chrome()
打开浏览器后导航到百度 即域名
driver.get('http://www.baidu.com')
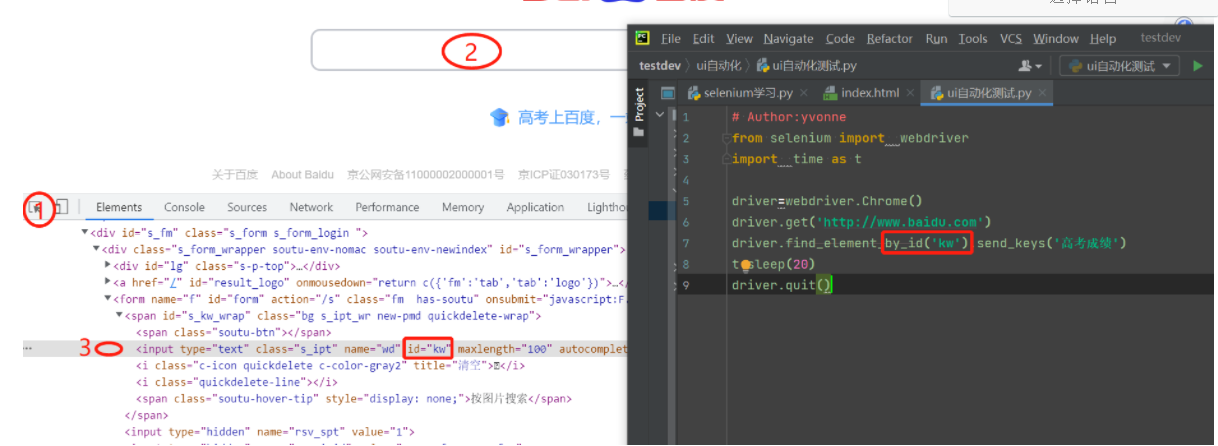
send keys 输入的方法(通过ID的属性定位到百度的输入框,并输入搜索的关键字)
driver.find_element_by_id('kw').send_keys('高考成绩')
休眠 指网页停留多少秒
t.sleep(2)
退出浏览器
driver.quit()
ID = "id" NAME = "name" XPATH = "xpath" LINK_TEXT = "link text" PARTIAL_LINK_TEXT = "partial link text" TAG_NAME = "tag name" CLASS_NAME = "class name" CSS_SELECTOR = "css selector"
方法一:
driver=webdriver.Chrome() driver.get('http://www.baidu.com') driver.find_element_by_id('kw').send_keys('高考成绩') t.sleep(2) driver.quit()
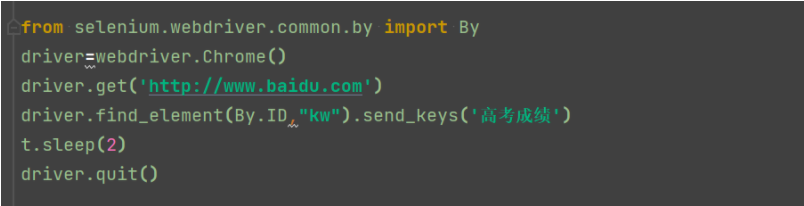
方法二:
from selenium.webdriver.common.by import By 先导入By driver=webdriver.Chrome() driver.get('http://www.baidu.com') driver.find_element(By.ID,"kw").send_keys('高考成绩') t.sleep(2) driver.quit()
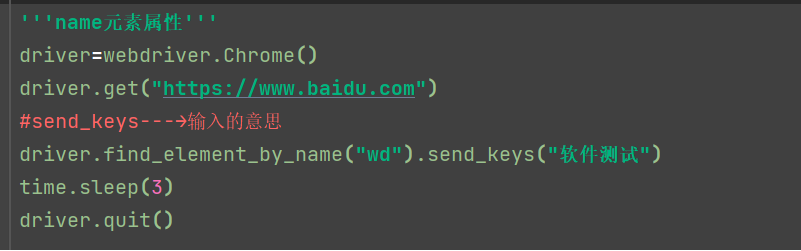
1.2定位元素:name
driver=webdriver.Chrome() driver.get('http://www.baidu.com') driver.find_element_by_name('wd').send_keys('高考成绩') t.sleep(2) driver.quit()
方法二:
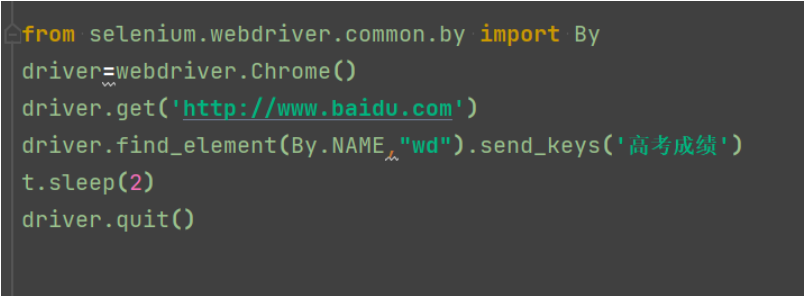
from selenium.webdriver.common.by import By 先导入By driver=webdriver.Chrome() driver.get('http://www.baidu.com') driver.find_element(By.NAME,"wd").send_keys('高考成绩') t.sleep(2) driver.quit()
1.3定位元素 class_name
方法一:
from selenium.webdriver.common.by import By 先导入By driver=webdriver.Chrome() driver.get('http://www.baidu.com') driver.find_element(By.NAME,"wd").send_keys('高考成绩') t.sleep(2) driver.quit()

方法二:
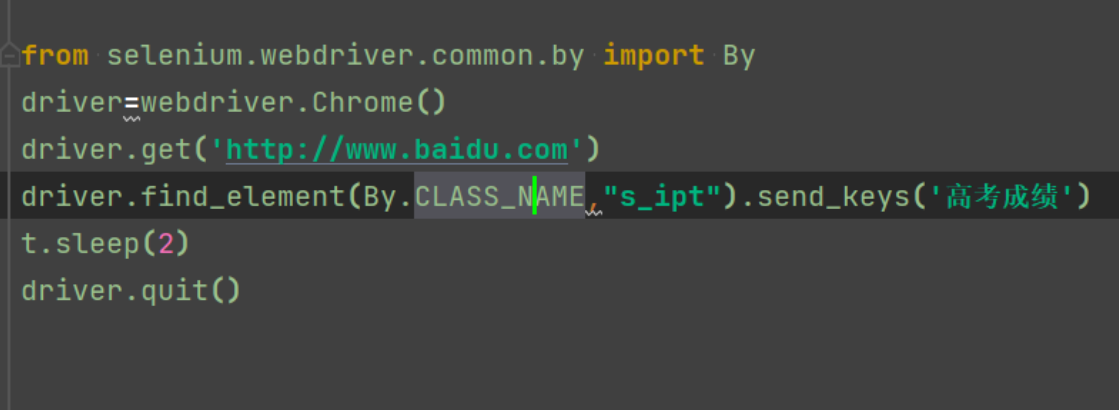
from selenium.webdriver.common.by import By 先导入By driver=webdriver.Chrome() driver.get('http://www.baidu.com') driver.find_element(By.CLASS_NAME,"s_ipt").send_keys('高考成绩') t.sleep(2) driver.quit()
当一个元素使用ID,name,class_name定位不到的时候,使用css(基于样式)和xpath(基于路径)
1.4定位元素 css(css selector) (找css 先点击copy选selector 自动复制)
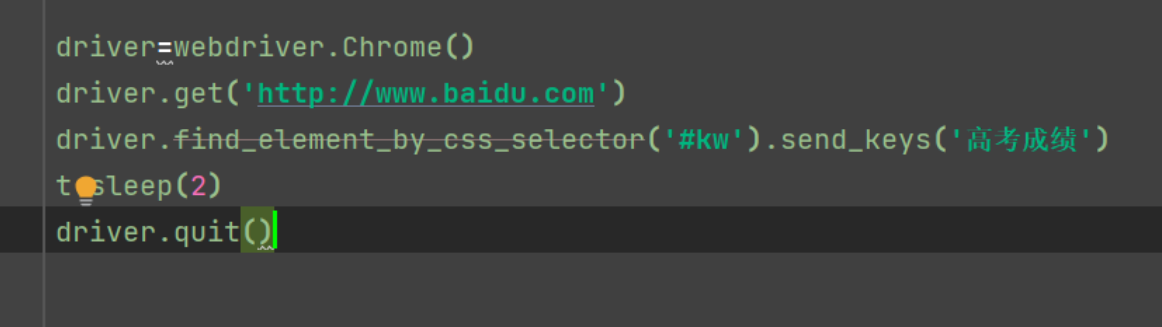
driver=webdriver.Chrome() driver.get('http://www.baidu.com') driver.find_element_by_css_selector("#kw").send_keys('高考成绩') t.sleep(3) driver.quit()
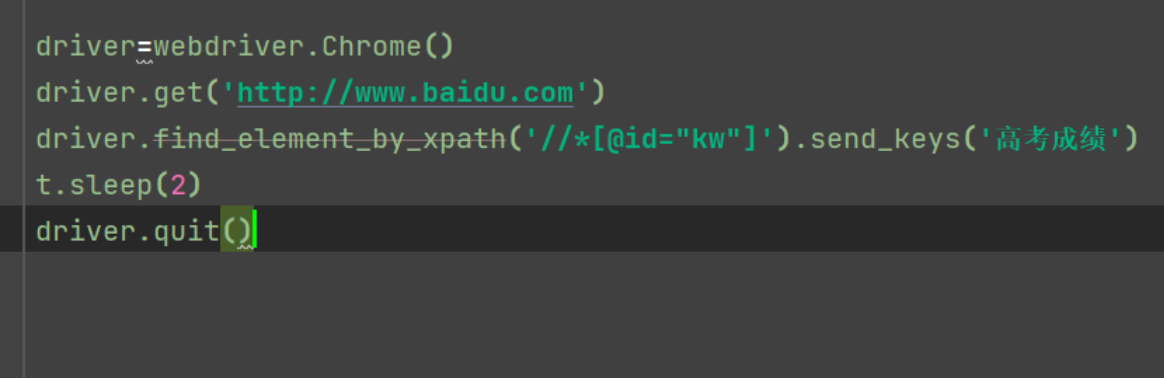
driver=webdriver.Chrome() driver.get('http://www.baidu.com') driver.find_element_by_xpath('//*[@id="kw"]').send_keys('高考成绩') 注意:有双引号的数据要用单引号 t.sleep(3) driver.quit()
driver=webdriver.Chrome() driver.get('http://www.baidu.com') driver.find_element_by_xpath('/html/body/div[1]/div[2]/div[5]/div[1]/div/form/span[1]/input').send_keys('高考成绩') t.sleep(2) driver.quit()
1.7定位元素 超链接(partial link text)
标签里都是超链接。
1.7.1 LINK_TEXT:超链接
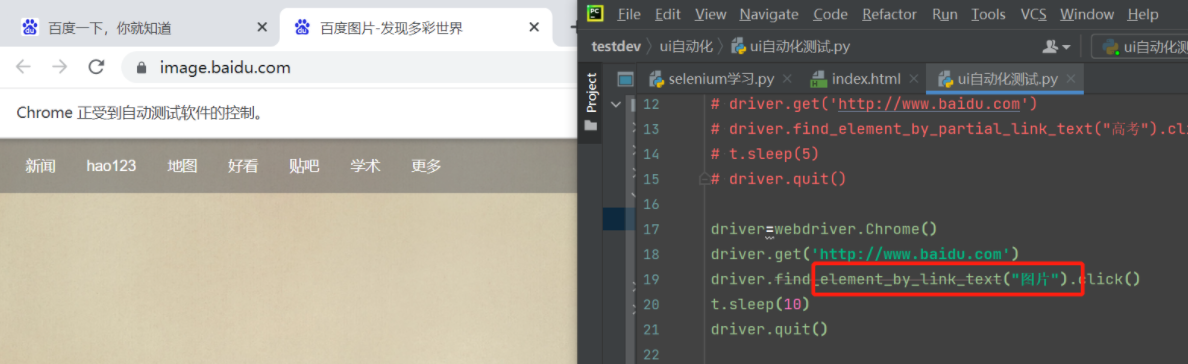
比如点击百度首页图片会调到第二个网页图片
driver=webdriver.Chrome() driver.get('http://www.baidu.com') driver.find_element_by_link_text("图片").click() t.sleep(10) driver.quit()
1.7.2PARTIAL_LINK_TEXT:也是处理超链接,但是是模糊搜索
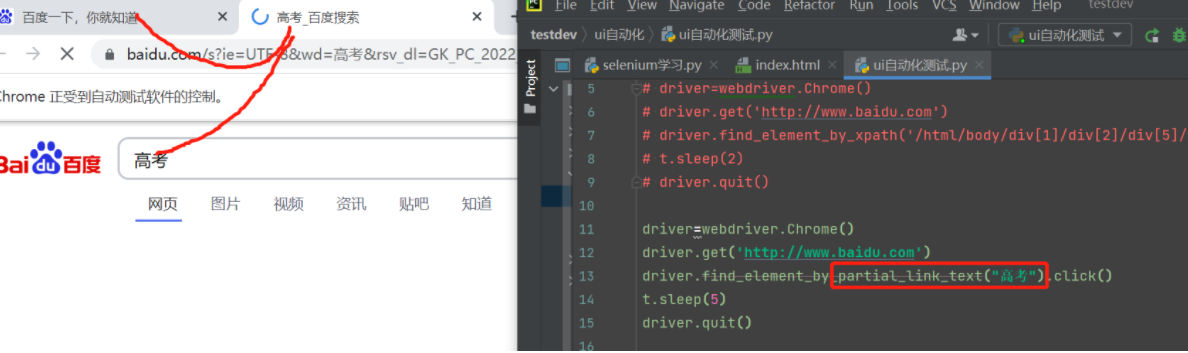
比如超链接搜索高考,会跳到第二个页面显示被搜索的高考页面
driver=webdriver.Chrome() driver.get('http://www.baidu.com') driver.find_element_by_partial_link_text("高考").click() t.sleep(5) driver.quit()
元素定位从分类上而言: 1、单个元素定位 2、多个元素定位(元素属性都一致) A、获取到的元素属性,它是一个列表 B、按照我们需要被定位的元素属性,它在列表中是第几位,那么 就使用它的索引来定位
1.8多元素定位:tag_name
多元素定位的element需要带s,多个元素定位返回的列表,定义为变量tags,然后根据索引tags[ ]来查找列表中我们需要的input元素。(我们定位的百度搜索输入框的input是在第八位,索引就是7)

driver=webdriver.Chrome() driver.get('http://www.baidu.com') input=driver.find_elements_by_tag_name("input") input[7].send_keys("selenium") t.sleep(20) driver.quit()
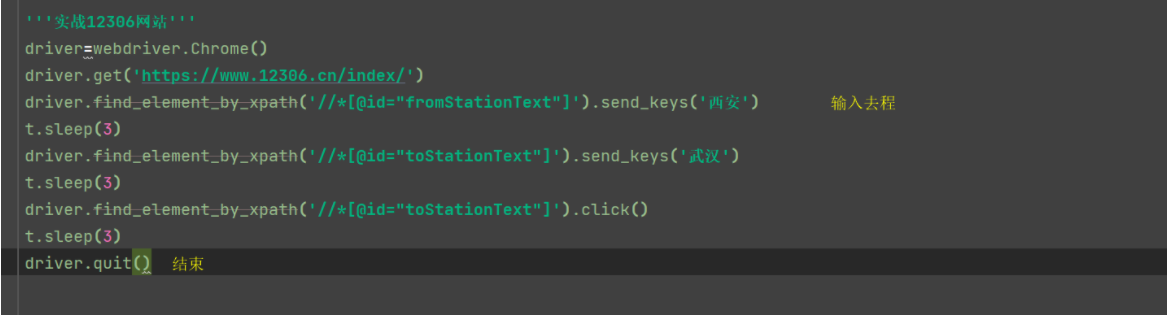
实战12306网站
driver=webdriver.Chrome() driver.get('https://www.12306.cn/index/') driver.find_element_by_xpath('//*[@id="fromStationText"]').send_keys('西安') t.sleep(3) driver.find_element_by_xpath('//*[@id="toStationText"]').send_keys('武汉') t.sleep(3) driver.find_element_by_xpath('//*[@id="toStationText"]').click() t.sleep(3) driver.quit()
二、iframe
遇到iframe解决步骤:
1、先进入到iFrame的框架
(如果frame有多层,需要一层层进入。进入的方法有三种)
2、然后再定位框架里面的元素属性
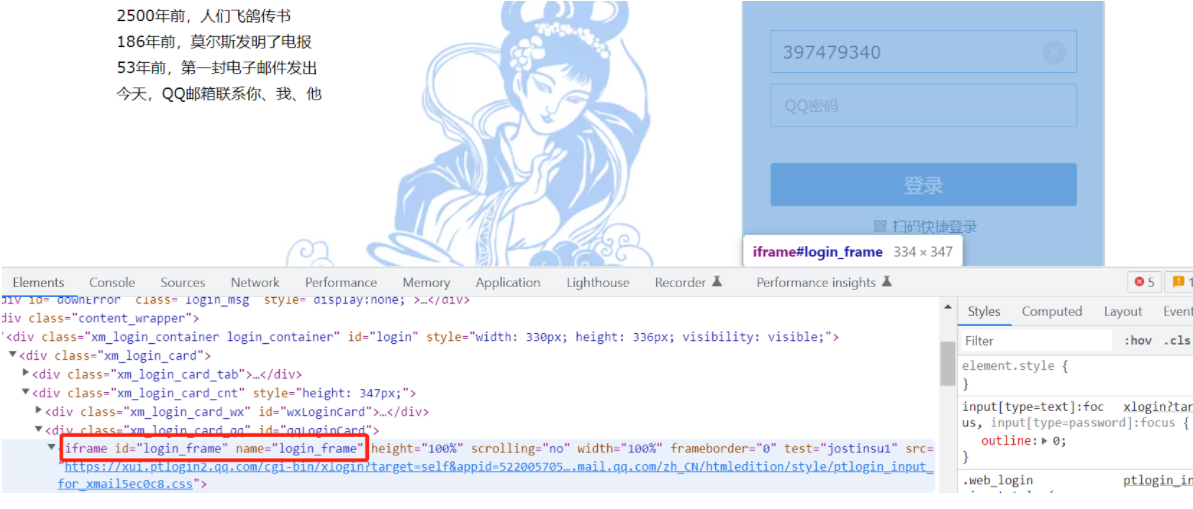
进入iframe框架三种方式:
1、通过ID
2、通过索引 (使用索引进入框架时,需要注意索引是同层级中我们的目标iframe的索引,不要跨级去看索引了)
3、通过name(基本不使用)
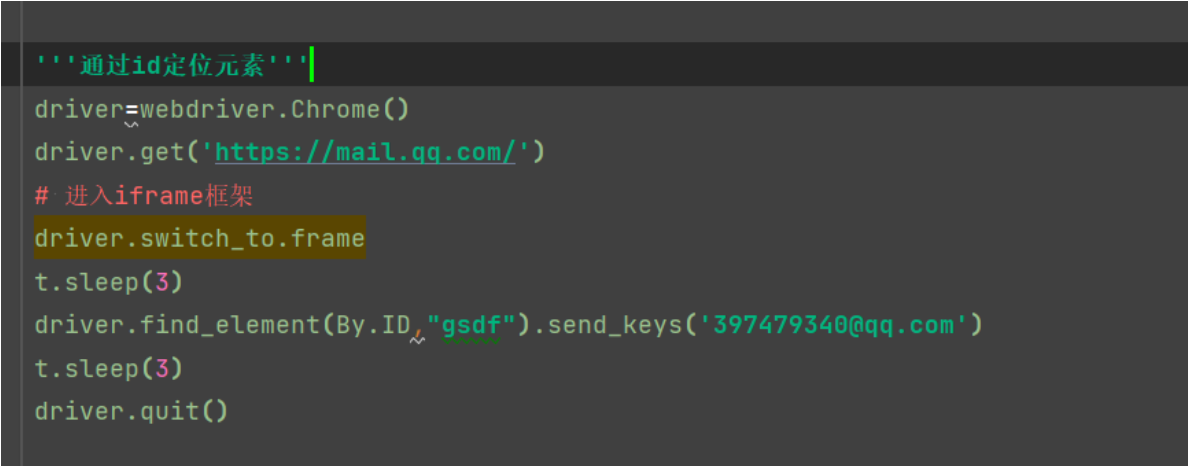
比如进入iframe框架通过ID元素定位
driver=webdriver.Chrome() driver.get('https://mail.qq.com/') # 进入iframe框架 driver.switch_to.frame t.sleep(3) driver.find_element(By.ID,"gsdf").send_keys('397479340@qq.com') t.sleep(3) driver.quit()
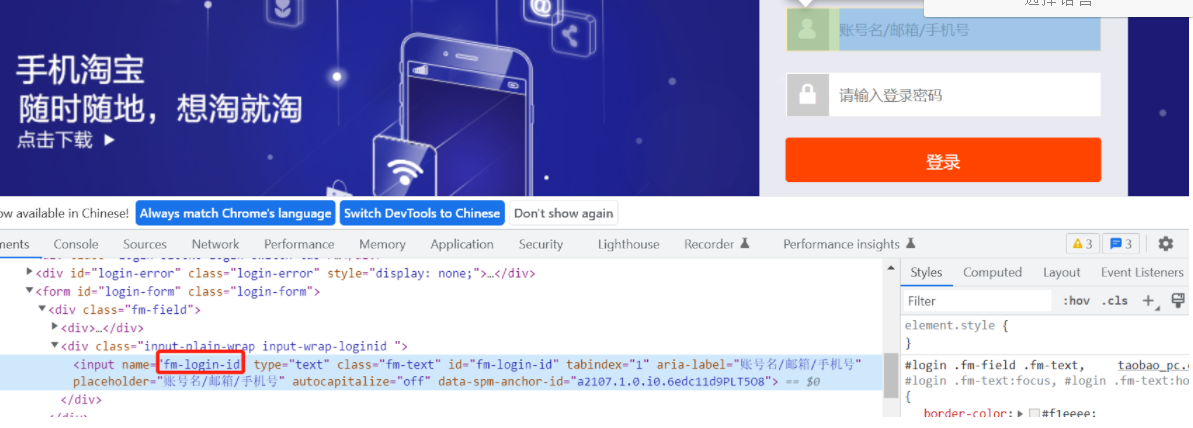
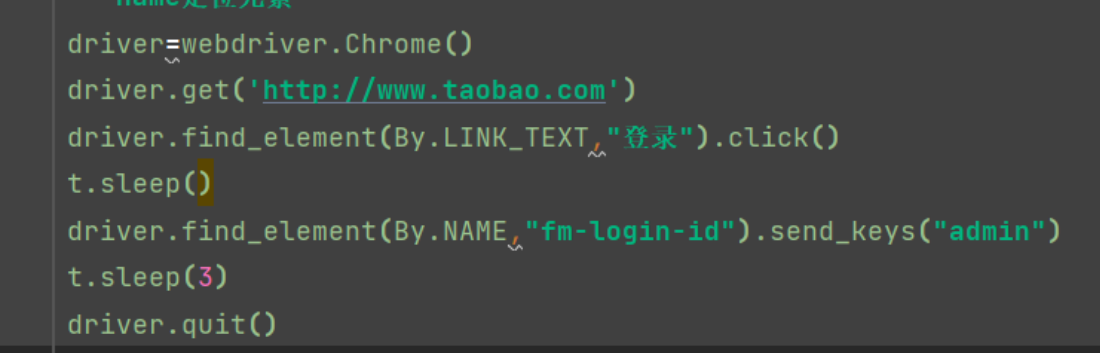
三、超链接名称登录
1.打开淘宝登录网页
2.超链接代码输入登录
3.打开淘宝登录网页 定位name元素
driver=webdriver.Chrome() driver.get('http://www.taobao.com') driver.find_element(By.LINK_TEXT,"登录").click() t.sleep() driver.find_element(By.NAME,"fm-login-id").send_keys("admin") t.sleep(3) driver.quit()
四、获取测试地址
driver=webdriver.Chrome() driver.get('http://www.baidu.com') print(driver.current_url) print(driver.page_source) '''获取当前的title''' print(driver.title) driver.quit()
五、获取前进与后退
driver=webdriver.Chrome() driver.get('http://www.baidu.com') t.sleep(2) driver.get('http://www.baidu.com') t.sleep(2) # .back()后退 driver.back() print(driver.current_url) t.sleep(2) # .forward()前进 driver.forward() print(driver.current_url) driver.quit()
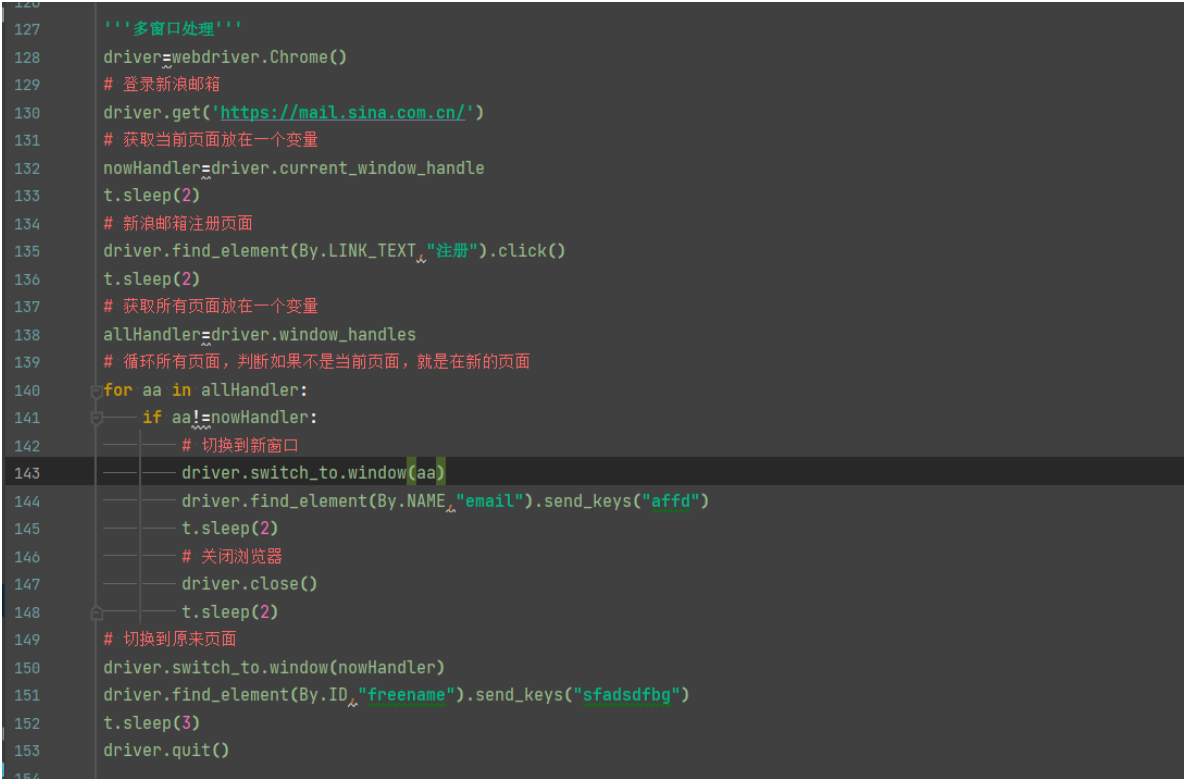
多窗口处理
需要实现从当前页面切换到另外一个新的页面,就需要使用到多窗口的操作和实战。解决步骤:
1、先打开当前页面
2、然后获取当前页面放在一个变量中 current_window_handle
3、打开新的页面
4、获取所有页面并且放在一个变量中 window_handles
5、循环所有页面,判断如果不是当前页面,那么就切换到新的页面 switch_to.window(xxx)
driver=webdriver.Chrome() # 登录新浪邮箱 driver.get('https://mail.sina.com.cn/') # 获取当前页面放在一个变量 nowHandler=driver.current_window_handle t.sleep(2) # 新浪邮箱注册页面 driver.find_element(By.LINK_TEXT,"注册").click() t.sleep(2) # 获取所有页面放在一个变量 allHandler=driver.window_handles # 循环所有页面,判断如果不是当前页面,就是在新的页面 for aa in allHandler: if aa!=nowHandler: # 切换到新窗口 driver.switch_to.window(aa) driver.find_element(By.NAME,"email").send_keys("affd") t.sleep(2) # 关闭浏览器 driver.close() t.sleep(2) # 切换到原来页面 driver.switch_to.window(nowHandler) driver.find_element(By.ID,"freename").send_keys("sfadsdfbg") t.sleep(3) driver.quit()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号