


pandas基本操作
一、查看数据
1.查看DataFrame前xx行或后xx行
a=DataFrame(data);
a.head(6)表示显示前6行数据,若head()中不带参数则会显示全部数据。
a.tail(6)表示显示后6行数据,若tail()中不带参数则也会显示全部数据。
2.查看DataFrame的index,columns以,dtypes及values
a.index ; a.columns ; a.values;a.dtypes 即可
3.describe()函数对于数据的快速统计汇总
a.describe()对每一列数据进行统计,包括计数,均值,std,各个分位数等。
4.对数据的转置
a.T
5.对轴进行排序
a.sort_index(axis=1,ascending=False);
其中axis=1表示对所有的columns进行排序,下面的数也跟着发生移动。后面的ascending=False表示按降序排列,参数缺失时默认升序。
6.对DataFrame中的值排序
a.sort(columns='x')
即对a中的x这一列,从小到大进行排序。注意仅仅是x这一列,而上面的按轴进行排序时会对所有的columns进行操作。
二、选择对象
1.选择特定列和行的数据
a['x'] 那么将会返回columns为x的列,注意这种方式一次只能返回一个列。a.x与a['x']意思一样。
取行数据,通过切片[]来选择
如:a[0:3] 则会返回前三行的数据。
2.通过标签来选择
a.loc['one']则会默认表示选取行为'one'的行;
a.loc[:,['a','b'] ] 表示选取所有的行以及columns为a,b的列;
a.loc[['one','two'],['a','b']] 表示选取'one'和'two'这两行以及columns为a,b的列;
a.loc['one',''a]与a.loc[['one'],['a']]作用是一样的,不过前者只显示对应的值,而后者会显示对应的行和列标签。
3.通过位置来选择
这与通过标签选择类似
a.iloc[1:2,1:2] 则会显示第一行第一列的数据;(切片后面的值取不到)
a.iloc[1:2] 即后面表示列的值没有时,默认选取行位置为1的数据;
a.iloc[[0,2],[1,2]] 即可以自由选取行位置,和列位置对应的数据。
4.使用条件来选择
使用单独的列来选择数据
a[a.c>0] 表示选择c列中大于0的数据
使用where来选择数据
a[a>0] 表直接选择a中所有大于0的数据
使用isin()选出特定列中包含特定值的行
a1=a.copy()
a1[a1['one'].isin(['2','3'])] 表显示满足条件:列one中的值包含'2','3'的所有行。
三、设置值(赋值)
赋值操作在上述选择操作的基础上直接赋值即可。
例a.loc[:,['a','c']]=9 即将a和c列的所有行中的值设置为9
a.iloc[:,[1,3]]=9 也表示将a和c列的所有行中的值设置为9
同时也依然可以用条件来直接赋值
a[a>0]=-a 表示将a中所有大于0的数转化为负值
四、缺失值处理
在pandas中,使用np.nan来代替缺失值,这些值将默认不会包含在计算中。
1.reindex()方法
用来对指定轴上的索引进行改变/增加/删除操作,这将返回原始数据的一个拷贝。
a.reindex(index=list(a.index)+['five'],columns=list(b.columns)+['d'])
a.reindex(index=['one','five'],columns=list(b.columns)+['d'])
即用index=[]表示对index进行操作,columns表对列进行操作。
2.对缺失值进行填充
a.fillna(value=x)
表示用值为x的数来对缺失值进行填充
3.去掉包含缺失值的行
a.dropna(how='any')
表示去掉所有包含缺失值的行
五、合并
1.contact
contact(a1,axis=0/1,keys=['xx','xx','xx',...]),其中a1表示要进行进行连接的列表数据,axis=1时表横着对数据进行连接。axis=0或不指定时,表将数据竖着进行连接。a1中要连接的数据有几个则对应几个keys,设置keys是为了在数据连接以后区分每一个原始a1中的数据。
例:a1=[b['a'],b['c']]
result=pd.concat(a1,axis=1,keys=['1','2'])
2.Append 将一行或多行数据连接到一个DataFrame上
a.append(a[2:],ignore_index=True)
表示将a中的第三行以后的数据全部添加到a中,若不指定ignore_index参数,则会把添加的数据的index保留下来,若ignore_index=Ture则会对所有的行重新自动建立索引。
3.merge类似于SQL中的join
设a1,a2为两个dataframe,二者中存在相同的键值,两个对象连接的方式有下面几种:
(1)内连接,pd.merge(a1, a2, on='key')
(2)左连接,pd.merge(a1, a2, on='key', how='left')
(3)右连接,pd.merge(a1, a2, on='key', how='right')
(4)外连接, pd.merge(a1, a2, on='key', how='outer')
至于四者的具体差别,具体学习参考sql中相应的语法。
六、分组(groupby)
用pd.date_range函数生成连续指定天数的的日期
pd.date_range('20000101',periods=10)

import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
data={
'date':pd.date_range('20000101',periods=10),
'gender':np.random.randint(0,2,size=10),
'height':np.random.randint(40,50,size=10),
'weight':np.random.randint(150,180,size=10)
}
a=pd.DataFrame(data)
#print(a)
b=a.groupby('gender').size()
c=a.groupby('gender').sum()
print(c)
print(b)
输出的结果为:
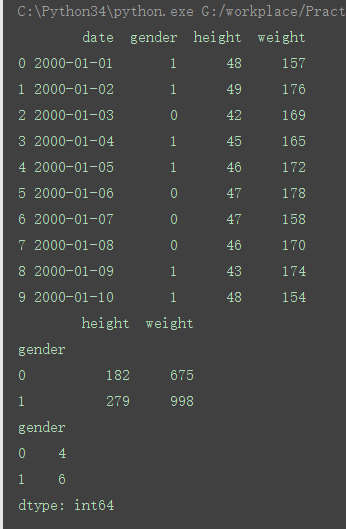
所有grouby是以里面的参数为标准,去分组,然后去统计相对应的数量
比如:
b=a.groupby('gender').size()
是统计以gender类型的个数
而:
c=a.groupby('gender').sum()
是统计以gender类型的其他属性的个数
按gender对gender进行分类,对应为数字的列会自动求和,而为字符串类型的列则不显示;当然也可以同时groupby(['x1','x2',...])多个字段,其作用与上面类似。
b=a.groupby(level=0).size()
c=a.groupby(level=0).sum()
输出结果为:
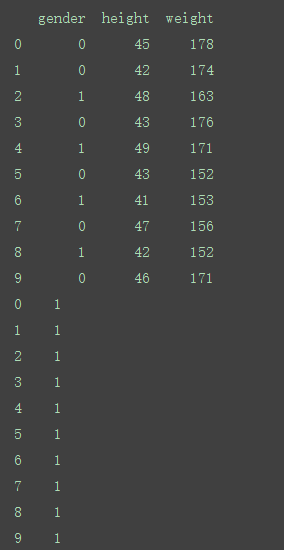
即按index分组并求和,就是根据前面的行号进行分组,得出来的数据
由上图可知:如果是sum的话,就只是列出具有数值型的数据出来,如果是size的话,就是列出每一列的个数出来。
其还有mean()的方法
如果有必要,其实就是原理就是对哪个类型,进行以谁为分组,然后进行统计该数值得和或者是平均值都可以。
如果是对进行分组的类别进行计算大小的话,就是使用.size()的方法。
七、Categorical按某一列重新编码分类
如六中要对a中的gender进行重新编码分类,将对应的0,1转化为male,female,过程如下:
a['gender1']=a['gender'].astype('category')
a['gender1'].cat.categories=['male','female'] #即将0,1先转化为category类型再进行编码。
print(a)得到的结果为:
date gender height weight gender1
0 2000-01-01 1 40 163 female
1 2000-01-02 0 44 177 male
2 2000-01-03 1 40 167 female
3 2000-01-04 0 41 161 male
4 2000-01-05 0 48 177 male
5 2000-01-06 1 46 179 female
6 2000-01-07 1 42 154 female
7 2000-01-08 1 43 170 female
8 2000-01-09 0 46 158 male
9 2000-01-10 1 44 168 female
八、相关操作
描述性统计:
1.a.mean() 默认对每一列的数据求平均值;若加上参数a.mean(1)则对每一行求平均值;
2.统计某一列x中各个值出现的次数:a['x'].value_counts();
3.对数据应用函数
a.apply(lambda x:x.max()-x.min())
表示返回所有列中最大值-最小值的差。
4.字符串相关操作
a['gender1'].str.lower() 将gender1中所有的英文大写转化为小写,注意dataframe没有str属性,只有series有,所以要选取a中的gender1字段。
九、时间序列
在六中用pd.date_range('xxxx',periods=xx,freq='D/M/Y....')函数生成连续指定天数的的日期列表。
例如pd.date_range('20000101',periods=10),其中periods表示持续频数;
pd.date_range('20000201','20000210',freq='D')也可以不指定频数,只指定其实日期。
此外如果不指定freq,则默认从起始日期开始,频率为day。其他频率表示如下:
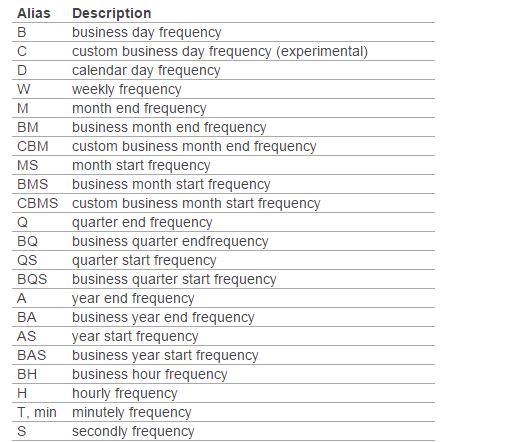

 浙公网安备 33010602011771号
浙公网安备 33010602011771号