


Machine Learning - 15 算法比较
比较不同算法的准确度,选择合适的算法,在处理机器学习的问题时是非常重要的。
本章内容包括:
- 如何设计一个实验来比较不同的机器学习算法
- 一个可以重复利用的,用来评估算法性能的模版
- 如何可视化算法的比较结果
选择最佳的机器学习算法
每种模型都有各自适应处理的数据特征,通过交叉验证等抽样验证方式可以得到每种模型的准确度,并选择合适的算法。通过这种评估方式,可以找到一种或两种最适合问题的算法。
当得到一个新的数据集时,应该通过不同的维度来审查数据,以便于找到数据的特诊,这种方法也适用于算法模型。同样需要从不同的维度,用不同的方法来观察机器学习算法的准确度,并从中选择一种或两种对问题最有效的算法。
一种比较好的方法是通过可视化的方式来展示平均准确度、方差等属性,以便于更方便地选择算法。
最合适的算法比较方法是:使用相同的数据、相同的方法来评估不同的算法,以便得到一个准确的结果。
下面使用同一个数据集来比较六种分类算法:
- 逻辑回归(LR)
- 线性判别回归(LDR)
- K近邻(KNN)
- 分类与回归树(CART)
- 贝叶斯分类器
- 支持向量机(SVM)
继续使用Pima Indians数据集来介绍算法比较。数据集为二分类数据集,结果只有两个分类结果;用来训练算法模型的数据是八种全部由数字构成的属性特征值。采用10折交叉验证类分离数据,并且采用相同的随机数分配方式来确保所有的算法都是用相同的数据集。
为了便于整理结果,给每一种算法设定一个短名字。
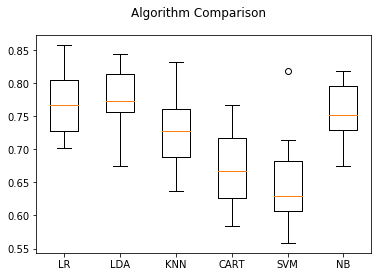
1 #算法比较 2 from pandas import read_csv 3 from sklearn.model_selection import KFold 4 from sklearn.linear_model import LogisticRegression 5 from sklearn.discriminant_analysis import LinearDiscriminantAnalysis 6 from sklearn.neighbors import KNeighborsClassifier 7 from sklearn.tree import DecisionTreeClassifier 8 from sklearn.svm import SVC 9 from sklearn.model_selection import cross_val_score 10 11 from sklearn.naive_bayes import GaussianNB 12 from matplotlib import pyplot 13 14 filename='/home/aistudio/work/pima_data1.csv' 15 names=['preg','plas','pres','skin','test','mass','pedi','age','class'] 16 data=read_csv(filename,names=names) 17 #将数据分为输入数据和输出数据 18 array=data.values 19 x=array[:,0:8] 20 y=array[:,8] 21 num_folds=10 22 seed=7 23 kfold=KFold(n_splits=num_folds,random_state=seed) 24 25 models={} 26 models['LR']=LogisticRegression() 27 models['LDA']=LinearDiscriminantAnalysis() 28 models['KNN']=KNeighborsClassifier() 29 models['CART']=DecisionTreeClassifier() 30 models['SVM']=SVC() 31 models['NB']=GaussianNB() 32 33 results=[] 34 for name in models: 35 result=cross_val_score(models[name],x,y,cv=kfold) 36 results.append(result) 37 msg='%s: %.3f (%.3f)' % (name,result.mean(),result.std()) 38 print(msg) 39 40 #图表显示 41 fig=pyplot.figure() 42 fig.suptitle('Algorithm Comparison') 43 ax=fig.add_subplot(111) 44 pyplot.boxplot(results) 45 ax.set_xticklabels(models.keys()) 46 pyplot.show()
执行结果给出了每种算法的平均准确度和标准方差:
LR: 0.770 (0.048) LDA: 0.773 (0.052) KNN: 0.727 (0.062) CART: 0.674 (0.060) SVM: 0.651 (0.072) NB: 0.755 (0.043)
同时也可以通过箱线图展示算法的准确度,以及10折交叉验证中每次验证的分布状况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号