对HashMap的一次记录
HashMap的具体学习,认识了解。
前言
也是最近开始面试才发现,HashMap是问的真多。以前听学长或自己在网上看到过一些面试资料都在说集合、线程这块比较重要,面试的重点。自己也是有那抵触情绪,所以自认为这块不重要,但最终发现自己真的太狭隘了,Map这块的知识真的是对数据存储有一个新的认识。但我现在认识尚浅,所以也真的说不出来什么感悟。只能就是对这块来一个简单的入门吧(主要原因还是自己的不注重基础知识的回顾,和一些重点源码的学习,导致时间一长,啥也不知道!)。
希望写完这篇随笔可以让自己对这块知识有个逻辑层次的认识。
一、回顾复习
1、Hash(哈希)是什么?
Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数 —引自百度百科
2、Map是什么?
首先将它意思翻译过来是“地图”“了解信息”的意思;当然在Java中可以理解为“映射”;
Map它是Java提供的专门用来存放“键值对”这种形式对象的接口;可以把它认为也是一个集合框架。
下面这个图真的见的很多很多,但却是简单明了的了解Java集合的好方法。
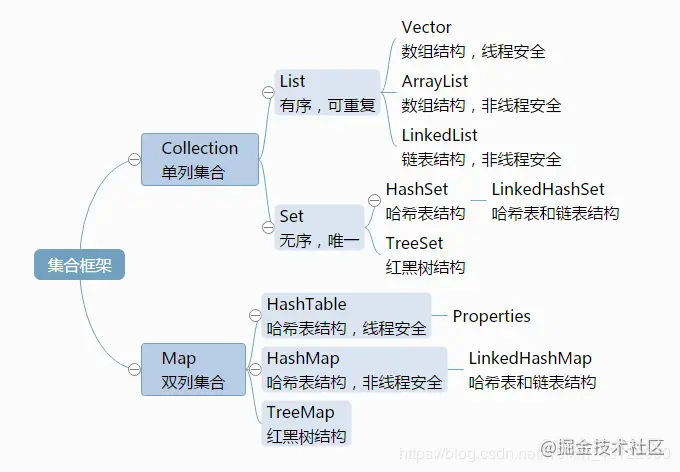
3、HashMap是什么?
Tips:Map接口中的集合都有两个泛型变量<K,V>,在使用时,要为两个泛型变量赋予数据类型。两个泛型变量<K,V>的数据类型可以相同,也可以不同
从维基百科中可以看到(我是直接用的谷歌翻译)
In computing, a hash table (hash map) is a data structure that implements an associative array abstract data type, a structure that can map keys to values. A hash table uses a hash function to compute an index, also called a hash code, into an array of buckets or slots, from which the desired value can be found. During lookup, the key is hashed and the resulting hash indicates where the corresponding value is stored.
Ideally, the hash function will assign each key to a unique bucket, but most hash table designs employ an imperfect hash function, which might cause hash collisions where the hash function generates the same index for more than one key. Such collisions are typically accommodated in some way.
In a well-dimensioned hash table, the average cost (number of instructions) for each lookup is independent of the number of elements stored in the table. Many hash table designs also allow arbitrary insertions and deletions of key–value pairs, at (amortized[2]) constant average cost per operation.[3][4]
In many situations, hash tables turn out to be on average more efficient than search trees or any other table lookup structure. For this reason, they are widely used in many kinds of computer software, particularly for associative arrays, database indexing, caches, and sets.
在计算中,哈希表(哈希映射)是一种实现关联数组抽象数据类型的数据结构,该结构可以将键映射到值。哈希表使用哈希函数将_索引_(也称为_哈希码_)计算到_桶_或_槽_数组中,从中可以找到所需的值。在查找过程中,键被散列,结果散列指示相应值的存储位置。
理想情况下,哈希函数会将每个键分配给一个唯一的桶,但大多数哈希表设计采用不完善的哈希函数,这可能会导致哈希冲突,其中哈希函数为多个键生成相同的索引。这种冲突通常以某种方式适应。
在维度良好的哈希表中,每次查找的平均成本(指令数)与存储在表中的元素数量无关。许多哈希表设计还允许任意插入和删除键值对,每次操作的平均成本为(摊销[2])不变。[3][4]
在许多情况下,哈希表平均比搜索树或任何其他表查找结构更有效。为此,它们被广泛用于多种计算机软件,特别是关联数组、数据库索引、缓存和集合。
看源码的话我们可以知道,HashMap继承了AbstractMap这个抽象类(此类提供Map接口的骨架实现,以最大限度地减少实现此接口所需的工作),然后AbstractMap实现了Map这个接口。
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable{……}
public abstract class AbstractMap<K,V> implements Map<K,V>{……}
public interface Map<K,V> {……}
到这就会发现其实collection中的set也很像HashMap。
4、熟悉的List、Set、Map区别问题
- List(对付顺序的好帮手): 存储的元素是有序的、可重复的。
- Set(注重独一无二的性质): 存储的元素是无序的、不可重复的。
- Map(用 Key 来搜索的专家): 使用键值对(key-value)存储,类似于数学上的函数 y=f(x),“x”代表 key,"y"代表 value,Key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值。
5、HashSet和HashMap的区别
如果你看过 HashSet 源码的话就应该知道:HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 clone()、writeObject()、readObject()是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。 —引自JavaGuide作者文章内容
| HashMap | HashSet |
|---|---|
| 实现了 Map 接口 | 实现 Set 接口 |
| 存储键值对 | 仅存储对象 |
| 调用 put()向 map 中添加元素 | 调用 add()方法向 Set 中添加元素 |
| HashMap 使用键(Key)计算 hashcode | HashSet 使用成员对象来计算 hashcode 值,对于两个对象来说 hashcode 可能相同,所以equals()方法用来判断对象的相等性 |
可以看一下具体继承实现
public class HashSet<E> extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable{……}
public abstract class AbstractSet<E> extends AbstractCollection<E> implements Set<E> {……}
public abstract class AbstractCollection<E> implements Collection<E> {……}
public interface Set<E> extends Collection<E> {……}
public interface Collection<E> extends Iterable<E> {……}
public interface Iterable<T> {……}
HashMap 提供了get方法,通过key值取对应的value值,
但是HashSet只能通过迭代器Iterator来遍历数据,找对象。
二、面试问题
1、HashMap底层实现
JDK1.8 之前:
HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
JDK1.8之后:
相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间
-
jdk8中添加了红黑树,当链表长度大于等于8的时候链表会变成红黑树
-
链表新节点插入链表的顺序不同(jdk7是插入头结点,jdk8因为要把链表变为红 黑树所以采用插入尾节点)
-
hash算法简化 ( jdk8 )(jdk8中直接进行返回)
-
resize的逻辑修改(jdk7会出现死循环,jdk8不会)
-
Jdk1.7:数组 + 链表 ( 当数组下标相同,则会在该下标下使用链表)Jdk1.8:数组 + 链表 + 红黑树 (预值为8 如果链表长度 >=8则会把链表变成红黑树 )
-
Jdk1.7中链表新元素添加到链表的头结点,先加到链表的头节点,再移到数组下标位置
-
Jdk1.8中链表新元素添加到链表的尾结点(数组通过下标索引查询,所以查询效率非常高,链表只能挨个遍历,效率非常低。jdk1.8及以上版本引入了红黑树,当链表的长度大于或等于8的时候则会把链表变成红黑树,以提高查询效率)
2、HashMap负载因子
负载因子:
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
* 使用树而不是列表的容器计数阈值。
* 当向至少有这么多节点的容器中添加元素时,
* 容器被转换为树。该值必须大于2,并且应该至少为8,
* 以与关于在收缩时转换回普通bins的树移除假设相匹配
*/
/**
*默认的负载因子是0.75f,也就是75% 负载因子的作用就是计算扩容阈值用,比如说使用
*无参构造方法创建的HashMap 对象,他初始长度默认是16 阈值 = 当前长度 * 0.75 就
*能算出阈值,当当前长度大于等于阈值的时候HashMap就会进行自动扩容
*/
loadFactor 加载因子是控制数组存放数据的疏密程度,loadFactor 越趋近于 1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor 越小,也就是趋近于 0,数组中存放的数据(entry)也就越少,也就越稀疏。
loadFactor 太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor 的默认值为 0.75f 是官方给出的一个比较好的临界值。(也是为了避免哈希冲突)
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能
3、HashMap默认长度为什么是16
/**
* The default initial capacity - MUST be a power of two.
* 默认的初始容量-必须是2的幂。
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
解释为什么是2的幂次方:
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648 到 2147483647,前后加起来大概 40 亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个 40 亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ (n - 1) & hash”。(n 代表数组长度)。这也就解释了 HashMap 的长度为什么是 2 的幂次方。
这个算法应该如何设计呢?
我们首先可能会想到采用%取余的操作来实现。但是,重点来了:“取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是 2 的 n 次方;)。” 并且 采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方
解释为什么是16:
老问题又来了,为啥HashMap中初始化大小为什么是16呢?
首先我们看hashMap的源码可知当新put一个数据时会进行计算位于table数组(也称为桶)中的下标:
int index =key.hashCode()&(length-1);
hahmap每次扩容都是以 2的整数次幂进行扩容
因为是将二进制进行按位于,(16-1) 是 1111,末位是1,这样也能保证计算后的index既可以是奇数也可以是偶数,并且只要传进来的key足够分散,均匀那么按位于的时候获得的index就会减少重复,这样也就减少了hash的碰撞以及hashMap的查询效率。
那么到了这里你也许会问? 那么就然16可以,是不是只要是2的整数次幂就可以呢?
答案是肯定的。那为什么不是8,4呢? 因为是8或者4的话很容易导致map扩容影响性能,如果分配的太大的话又会浪费资源,所以就使用16作为初始大小。
4、扩容机制
什么场景下会触发扩容?
场景1:哈希table为null或长度为0;
场景2:Map中存储的k-v对数量超过了阈值threshold;
场景3:链表中的长度超过了TREEIFY_THRESHOLD,但表长度却小于MIN_TREEIFY_CAPACITY。
HashMap为了存取高效,要尽量较少碰撞,就是要尽量把数据分配均匀,每个链表长度大致相同,这个实现就在把数据存到哪个链表中的算法;这个算法实际就是取模,hash%length。
但是,大家都知道这种运算不如位移运算快。
因此,源码中做了优化hash&(length-1)。
也就是说hash%length==hash&(length-1)
那为什么是2的n次方呢?
因为2的n次方实际就是1后面n个0,2的n次方-1,实际就是n个1。
例如长度为8时候,3&(8-1)=3 2&(8-1)=2 ,不同位置上,不碰撞。
而长度为5的时候,3&(5-1)=0 2&(5-1)=0,都在0上,出现碰撞了。
所以,保证容积是2的n次方,是为了保证在做(length-1)的时候,每一位都能&1 ,也就是和1111……1111111进行与运算。
写数据之后会可能触发扩容,HashMap结构内,我记得有一个记录当前数据量的字段,这个数据量字段到达扩容阈值的话,它就会触发扩容的操作
阈值(threshold) = 负载因子(loadFactor) x 容量(capacity) 当HashMap中table数组(也称为桶)长度 >= 阈值(threshold) 就会自动进行扩容。
扩容的规则是这样的,因为table数组长度必须是2的次方数,扩容其实每次都是按照上一次tableSize位运算得到的就是做一次左移1位运算,
假设当前tableSize是16的话 16转为二进制再向左移一位就得到了32 即 16 << 1 == 32 即扩容后的容量,也就是说扩容后的容量是当前
容量的两倍,但记住HashMap的扩容是采用当前容量向左位移一位(newtableSize = tableSize << 1),得到的扩容后容量,而不是当前容量x2
三、网上文章
以上部分基本是摘抄的,因为网上对这方面的解释以及分析实在是多的很,想要自己真正的去理解,我感觉看源码是来的比较快的,毕竟源码中也有注释,而且理解的话也不会有较大的偏差。上文一些参考文章如下:
【JavaGuide面试题解】
【HashMap底层实现原理详解】
【HashMap面试必问的6个点,你知道几个?】
【HashMap面试题,看这一篇就够了!】
【Java集合面试题(总结最全面的面试题)】
凡事都有利弊,我们能做的就是尽量趋利避害!
最后
别人的看法
我也称之为:活在他人的期待中。(比如,父母选的,不想让父母失望)
我们终此一生,就是摆脱他人的期待,活出真正的自己!
你可以接受别人的观点,但不是全盘接受,这样你可以加以利用,把它变成属于自己的产物,哪怕是我这篇令你颠覆自我的文章也是。
别人的观点、看法,本质来说是自我的,是自己的三观产物,因此不是完美的,从某种角度来说,甚至和你没关系(比如我学计算机的,你学音乐的,你给我建议,说让我学小提琴,完全没道理啊!和我没关系~)。
事实证明:人们之所以给你建议,是因为自己不安,这是他们给自己设定的目标,这不是你的目标,这是他们想要调节自己的认知
作者:Frank-FuckPPT https://www.bilibili.com/read/cv11220141 出处:bilibili
警言: 无论人生上到哪一层台阶,阶下有人在仰望你,阶上亦有人在俯视你。你抬头自卑,低头自得,唯有平视,才能看见真实的自己。
转载请注明原文链接:https://www.cnblogs.com/yuyueq/p/15119512.html
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢你的支持!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号