

课程论文
题目:网络爬虫及数据分析
|
课 程 名 称 |
Python程序设计 |
|
考 查 学 期 |
2020-2021学年第二学期 |
|
考 查 方 式 |
期末答辩 |
|
姓 名 |
|
|
学 号 |
201906110000 |
|
专 业 |
计算机科学与技术 |
|
成 绩 |
|
|
指 导 教 师 |
|
目录
1、 需求分析
1.1课题分析
1.2题目拟定
1.3设计要求
1.4课题目标
2、总体设计
2.1爬虫部分
2.2连接MySQL数据库
2.3程序流程图
2.4主要问题与分析
3、详细设计
3.1 主文件:dangdang.py。
3.2 myMySQL.py文件
4、程序运行结果测试与分析
4.1爬取数据
4.2 存储数据
4.3异常处理
课程论文(设计)评分表
课程论文(设计)评语表
1、 需求分析
1.1课题分析
课题网络爬虫及数据分析,包括爬虫部分和数据分析部分。网络爬虫是当下比较热门的,通俗地讲爬虫就是编写代码从网页上爬取自己想要的数据;数据分析是将爬取的数据进行可视化的显示,其中可以是直观性地展示原始数据,另外也可以将数据分析通过不同的模式显示,如使用matplotlib库来绘制图。
1.2题目拟定
此次爬虫选取的是当当网图书榜中的图书畅销榜,设定为近24小时,网址为:http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1
1.3设计要求
1)使用requests模块抓取目标网页。
2)使用Beautiful Soup4模块进行网页分析,讲目标网页中感兴趣的内容进行输出。
3)数据输出方式包括写入csv文件、写入数据库。
4)源代码设计要求标准IPO注释,异常处理,异常信息写入日志文件或数据库。
1.4课题目标
通过编程爬取近24小时当当网图书榜中的图书畅销榜排名信息,具体如下:图书名字、图书排行、价钱和作者。通过爬取的数据存入数据库,可直观的查看最近畅销书籍以达到读者购买或者商家及时进货与上架。
2、总体设计
2.1爬虫部分
1)客户端向服务器发送自己设定好的请求。
2)通过requests模块、http将Web服务器上协议站点的整个网页数据源代码提取出来。
3)分析http源码,根据一定的正则表达式提取出所需要的信息。
4)采用深度优先搜索从网页中某个链接出发,访问该链接的网页,并通过递归算法实现依次向下访问(翻页功能)。
2.2连接MySQL数据库
1)创建相应数据库(注意创建表、插入数据的接口,字符类型与数值大小)。
2)获取相应信息,并封装。
3)连接MySQL数据库,写入数据。
2.3程序流程图
图2-1 程序流程图
2.4主要问题与分析
1)读取数据
主要问题:获取数据时出现错误。
分析:看报错提示进行调试;首先看代码逻辑是否合理(合理);再看爬取对象的路径,即是否成功进入爬取网页;观察网页中的类、选择器、元素等是否与获取的对象元素路径相同,是否是遍历失败。
2)写入数据库
主要问题:数据写不进数据库。
分析:获取的数据存入元组item中,是否与数据库表中的列表数相同,可插入。
3)获取异常
主要问题:遇到http源代码中个别标签缺失或不同将获取失败。
分析:进行异常处理。获取失败时,记录异常发生时间、数据类型与地址,写入日志文件。
3、详细设计
3.1 主文件:dangdang.py。
文件dangdang.py作为整个程序的核心,引用BeautifulSoup模块、requests模块、UserAgent模块以及MySQL模块。
1) request_dangdang(url)方法
函数request_dangdang,将目标url作为参数,headers作为请求头将自动生成的UserAgent作为反爬机制。再调用requests类的get方法获取请求url返回的响应内容,通过response.status_code获取响应代码,若为200则成功响应,通过response.status_code获取响应的HTML文本。
主要代码如下:
def request_dangdang(url):
headers = {
'user-agent': user_agent
}
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
except requests.RequestException:
return None
n = 1
2) getResult(soup)方法
定义函数 getResult(),BeautifulSoup 对象作为参数,首先获取所有类选择器为bang_list clearfix bang_list_mode的li标签,每本书对应的 Tag 对象作为列表的元素保存到html变量,定义空列表 resuh 用来存储希望得到的电影信息,包括排名、书名、得分推荐程度、现价等。遍历 html变量,使用 BeautifulSoup 相关方法,结合html分析获取前述图书信息,即item_index、item_name、 item_score,item_price,将四个包含图书信息的字符串存储在元组item 中,最后将item 插人列表result 暂时存储,result 最终作为函数返回值。
主要代码如下:
def getResult(soup):
html = soup.find(class_='bang_list clearfix bang_list_mode').find_all('li')
result = []
for item in html:
item_name = item.find(class_='name').find('a').get('title') # 书名
item_img = item.find('a').find('img').get('src') # 封面
item_index = item.find(class_='list_num').string # 排名
item_score = item.find(class_='tuijian').string # 得分推荐
item_price = item.find(class_='price').find(class_='price_n').string # 现价
item = (item_index, item_name, item_score, item_price)
# 测试是否爬取成功,在控制台输出
# print('爬取图书:' + item_index + ' | ' + item_name +' | ' + item_img +' | ' + item_score +' | ' + item_price )
# print('爬取图书:' + item_index + ' | ' + item_name + ' | ' + item_score + ' | ' + item_price)
result.append(item)
return result
3) onePage(page)方法
定义函数onePage,查看分析网页页数的规律,根据找出遍历网站页数的方法,调用request_dangdang(url)函数获取对应页面的信息,然后html作为参数,实例化beautifulsoup类生成对象soup,调用getResult(soup)函数,将一个页面所要爬取的数据存入result,实现翻页功能。
主要代码如下:
def onePage(page):
url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-' + str(page)
html = request_dangdang(url)
soup = BeautifulSoup(html, 'lxml')
result = getResult(soup)
return result
4) allPage()方法
设置for循环,将变量传给onePage()函数,设置爬取页数。
主要算法如下:
def allPage():
result = []
for i in range(1, 6): # 从第一页开始,到第五页
result = result + onePage(i)
return result
5) saveToMysql(result)方法
创建数据库表,将获取数据插入数据库。
主要代码如下:
def saveToMysql(result):
dbhelper = myMysql.DBHelper()
# 创建数据库的表
sql = """drop table if EXISTS book"""
dbhelper.execute(sql, None)
sql = """create table if not EXISTS book(
id int(11) NOT NULL AUTO_INCREMENT,
ranking char(8) NOT NULL ,
name char(200) NOT NULL,
score char(8) NOT NULL,
price char(20) NOT NULL,
PRIMARY KEY (id))"""
dbhelper.execute(sql, None)
# 插入数据
sql = """INSERT INTO book(ranking,name, score, price)VALUES (%s,%s,%s,%s)"""
dbhelper.executemany(sql, result)
3.2 myMySQL.py文件
在文件myMySQL.py中,定义DBHelper类,class DBHelper,通过构造函数创建数据库函数、连接数据库函数、将错误信息写入异常日志,将获取数据插入数据库、查表等。
1)def __init__()函数
数据结构设计,使用链表作为URL队列,列表的每个结构体是一个数据单元。
主要代码如下:
def __init__(self, host='localhost', user='root',
pwd='123456', port=3306, dd='dangdang'):
self.host = host
self.user = user
self.pwd = pwd
self.port = port
self.dd = dd
self.conn = None
self.cur = None
self.createDatabase() # 创建名为dangdang的数据库
2)createDatabase(self)方法
通过调用连接数据库,创建数据库
3)def connectDatabase(self)函数
# 连接数据库
4)def __del__(self)函数
关闭数据库,释放内存
# 关闭数据库
def __del__(self):
# 如果数据打开,则关闭;否则没有操作
if self.conn and self.cur:
self.cur.close()
self.conn.close()
# print("关闭")
return True
5)def executemany(self, sql, params=None)函数、def execute(self, sql, params=None)函数、def fetchall(self, sql, params=None)函数分别实现数据插入与查询功能
6)异常处理
发生数据异常时将异常的相关信息写入数据库,如异常的发生时间、类型地址等等。
主要代码如图3-1所示:
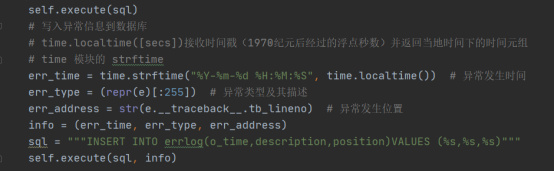
图3-1 异常处理
4、程序运行结果测试与分析
4.1爬取数据
测试:在控制台打印爬取数据,测试设置如图4-1所示,打印验证如图4-2所示。
具体测试代码如下:
# 测试是否爬取成功,在控制台输出
print('爬取图书:' + item_index + ' | ' + item_name +' | ' + item_img +' | ' + item_score +' | ' + item_price )
print('爬取图书:' + item_index + ' | ' + item_name + ' | ' + item_score + ' | ' + item_price)

图4-1 测试代码
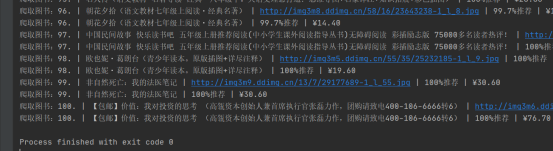
图4-2 控制台打印测试结果
测试结果分析:测试成功,成功访问目标网页,获取源代码,打印相关目标信息。
4.2 存储数据
1)将数据写入csv
利用创建csv文件,将获取的数据组写入文件中,实现写入代码如图4-3,测试文件数据写入成功如图4-4所示。
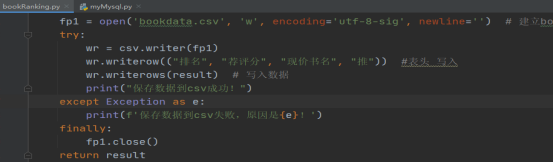
图4-3 数据写入csv文件实现代码

图4-4 csv文件数据
测试结果分析:成功将爬取的网页数据写入到csv文件中。
2)将数据写入到数据库
创建数据库,如图4-5所示。
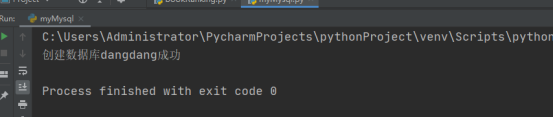
图4-5 创建数据库dangdang成功
将爬取数据写入数据库,在MySQL数据库中查看数据,如图4-6所示。
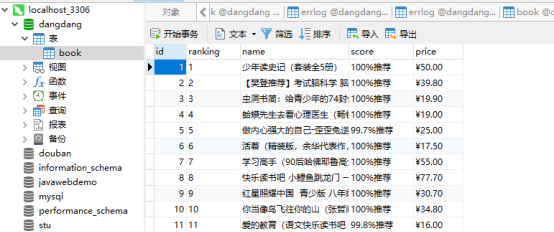
图4-6 MySQL数据库book表中数据
测试结果分析:成功创建数据库、数据库表,将数据写入数据库中。
4.3异常处理
异常处理测试条件:
测试:主动制作异常,如图4-7所示;测试结果,显示数据库异常情况文件,如图4-8所示。

图4-7 异常情况测试
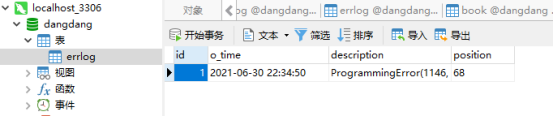
图4-8 数据库异常情况文件
测试结果分析:发生异常,将异常信息成功写入数据库。
5、结论与心得
本次网络爬虫项目主要应用的技术有:在提取网页中链接等功能函数中使用正则表达式。实现的功能有:获取http协议链接的网页,把网页中所需要的信息暂存,将解析出来所需要的放进数据库中。此次实验涵盖的知识较新也是当下比较火热的技术,其中应用了python中许多模块,其中更有数据库方面,不仅要掌握python的基本知识,也要巩固MySQL中的语法等。这让我明白了学习掌握基础知识是第一步,再根据适当的练习实践是第二步,其次是涉及着多个方面的知识,要注意多方面的学习,最后再应用到综合实验中不同的情况。其中在调试代码时出现自己解决不了的要及时与老师或者同学一起讨论交流,因为自己的经验不足,所以要尽量避免时间效率的应用。
其中因为自身技术与时间的问题,异常处理方面只是在数据库中进行了测试,可能在实际应用时遇到不同的异常有不同的失败风险。
参考文献
[1] 张长海,赵海霞,崔娟等.python程序设计语言项目化教程[M].清华大学出版社:北京,2020.
课程论文(设计)评分表
|
评分项目 |
得分 |
|
创新性、合理性(5分) 5:表明设计具有创新性、合理性; 3:表明设计具有新意、合理性; 1:表明设计具有合理性。 |
|
|
选题难度、实现复杂性(10分) 9-10: 难度系数高,设计实现功能复杂; 7-8:难度系数低,设计实现功能较复杂; 6分以下:难度系数很低,设计实现功能一般。 |
|
|
完成情况包括功能完整性、工作量、界面美观友好(50分) 40-50:按要求完成课题的全部功能,有完整的符合标准的文档,文档有条理、文笔通顺,格式正确,其中有总体设计思想的论述,有正确的流程图,程序完全实现设计方案,设计方案先进,软件可靠性好; 30-39:完成课题规定的功能,有完整的符合标准的文档,文档有条理、文笔通顺,格式正确;有完全实现设计方案的软件,设计方案较先进,无明显错误; 29-20:完成课题规定的功能,有完整的符合标准的文档,有基本实现设计方案的软件,设计方案正确,但有少数失误; 19以下:完成课题规定的大部分功能,有完整的符合标准的文档,有基本实现设计方案的软件,设计方案基本正确,个别功能没有实现。 |
|
|
课程设计报告(15分) 15:优秀表明报告清楚详细地说明了设计的过程,格式规范、内容完整,阐述清晰,层次分明; 12:良好表明报告说明了设计的过程,格式较规范、内容比较完整,阐述清晰,有层次; 9:中表明报告说明了设计的过程说明不太清晰,格式不规范、内容比较简单; 9以下:差表明报告过于简单。 |
|
|
答辩表现(20分) 16-20:自己的设计阐述清晰,回答问题准确,基本概念非常清楚; 10-15:自己的设计阐述比较清晰,回答问题较准确,基本概念比较清楚; 9分以下:自己的设计阐述不清晰,回答问题不准确,基本概念不清楚。 |
|
|
总得分: |
|
课程论文(设计)评语表
|
指导老师评语:(评语50字左右,对论文选题、资料收集与处理、论证水平、写作能力和规范等进行评定。)
成绩评定:
指导教师签名: 年 月 日 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号