
数据仓库如何设计维度表
概览
本文主要讨论
- 什么是星型模型
- 事实表举例
- 维度表举例
- 如何设计维度表
- 为什么需要代理键
- 为什么维度表要设计成拉链表
- 用原来的主键+日期作为联合主键能否替代拉链
- 为什么不把聚合指标存到维度表
一、 从星型模型说起
Fact Tables
事实表
用实例说明,例子是交易的场景:
| date | store | item | qty | amount |
|---|---|---|---|---|
| 2021-01-01 | Store 1 | Gloves | 2 | 20 |
| 2021-01-02 | Store 2 | Hammer | 1 | 28 |
这是一个事实表的简单例子,它包含:
- 维度 (Dimension):date , store , item
- 度量 (Measures): qty, amount
维度表
添加一下城市和种类信息,比如这样加:
| date | country | store | item_cat | item | qty | amount |
|---|---|---|---|---|---|---|
| ... | Singapore | Store 1 | Materials | Gloves | 2 | 20 |
| ... | Thailand | Store 2 | Tools | Hammer | 1 | 28 |
遗憾的是,这样的设计无法支撑大量的数据,事实表的记录数量数以百万百亿,这样会需要大量的额外存储的空间
由于这些属性和对应的维度有1对1的映射关系,拆分出一张维度表来进行管理很有意义:
Fact Table
| date | store | item | qty | amount |
|---|---|---|---|---|
| 2021-01-01 | Store 1 | Gloves | 2 | 20 |
| 2021-01-02 | Store 2 | Hammer | 1 | 28 |
Dimension Tables
| store | country |
|---|---|
| Store 1 | Singapore |
| Store 2 | Thailand |
| item | item_cat |
|---|---|
| Gloves | Materials |
| Hammer | Tools |
这便是鼎鼎大名的星型模型
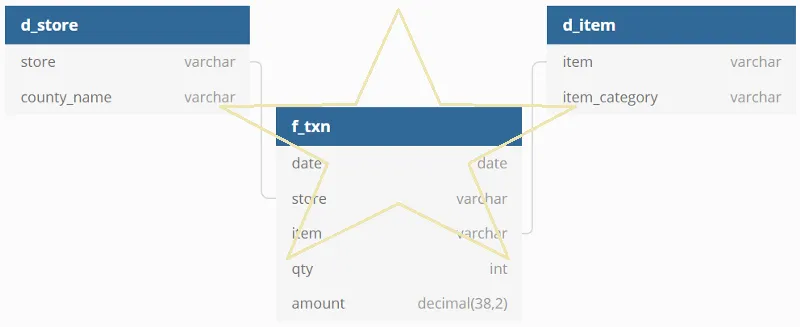
二、维度表怎么设计
上面的设计看起来已经进行了很大的优化设计了,但是这样其实并不足以解决所有的问题,请接着看:
什么是代理键
- 代理键是数据仓库中的维度表中的一种重要的概念。维度表中的代理键是一个用于替代原始主键的虚拟主键,用于关联事实表和维度表。代理键的主要作用是为了减少维度表中主键的编号变更所造成的影响,因为编号变更将导致外键变更,进而影响到所有与该维度表相关的数据。
为什么需要代理键surrogate key
- 假设我们的业务数据库来自于不同的系统,对这些数据进行整合的时候有可能出现相同的 Business Key,这时通过 Surrogate Key 就可以解决这个问题。
- 一般来自业务数据库中的 Business Key 可能字段较长,比如 GUID,长字符串标识等,使用Surrogate Key 可以直接设置成整形的。事实表本身体积就很大,关联 Surrogate Key 与关联 Business Key 相比,Surrogate Key 效率更高,并且节省事实表体积。
- 最重要的一点,使用 Surrogate Key 可以更好的解决这种缓慢渐变维度,维护历史信息记录
那么什么是缓慢渐变维度(Slowly Changing Dimension)?
连接到事实表的所有其他维度,包括客户、产品、服务、条款、位置和员工等基本实体,不是一成不变的, 这些变化是意外地、零星地发生的,而且比事实表新增记录的频率要低得多,所以我们称这个主题为缓慢变化的维度 (SCD)。
例子:
雇员的部门更替
假定有一个雇员叫李华,他最早是负责运营的——此时他的title是"商品运营助理";但因为某些原因,他转组成为数据组的一员,这时title就变成了"数据分析专员"。
这是缓慢变化维的一种常见可能
那么怎么处理缓慢变化维度?
常见处理方法有3种:
Type 1:
与业务数据保持一致,直接update为最新的数据。
这种方法主要应用于以下两种情况:
数据必须正确——例如用户的身份证号,如需要更新则说明之前录入错误。
无需考虑历史变化的维度——例如用户的头像url,这种数据往往并没有分析的价值。因此不做保留。
这种处理方式的优缺点:
优点:
简化ETL——直接update即可。
节省存储空间——其他存储方法都占用更多空间。
缺点:
无法保留历史痕迹——万一有天想分析呢?
Type 2:
更新历史数据时间戳,新增新行记录新值。落到实操层面,就是增加代理键,维度表使用拉链表
- 这样一来,因为事实表存储的是维度表的代理键而非自然键,因此在历史数据的查询中会以历史的维度值进行计算。同时在维度值更新后的相关数据自然使用的是新的代理键。完美的解决了大部分缓慢变化维情况
Type 3及其他
其实Kimball定义的缓慢维度变化解决办法总共7种,其余的类型用的不是很多,本文不展开讨论。
微软的推荐做法
- 实践中推荐使用代理键
– 尽管业务的主键可以用来做唯一标识,还是推荐使用代理键
- 力求数据仓库能从变化中隔离
– 使用尽量小的int类型
– 不要赋予代理键任何业务含义
- 并不一定从0开始
- 总是储存原来的业务主键
– 这有助于追溯到原系统
如果不用代理键会怎么样
- 如果不使用代理键,当维度表中的主键编号发生变更时,所有与该维度表相关的数据都将受到影响。这将导致数据仓库中的数据不一致,并且可能导致分析结果不准确。
为什么设计成拉链表
- 拉链表是一种使用拉链技术维护维度表数据历史的方法。拉链表的主要优点是能够保存维度表数据的历史变更信息,这对于维护数据的一致性和审计功能非常有帮助。如果不使用拉链表,维度表的数据变更将只能被最新的数据覆盖,将无法获取历史变更信息
如果采用业务主键+日期的方式来确定维度表的唯一主键会怎么样,这样也不会覆盖数据了
- 数据完整性问题:由于主键的更改,我们需要对数据仓库中的所有相关数据进行更新,这将需要大量的处理时间和系统资源
- 无法提前预知问题:假设是维度表的属性改变,这样会导致提前写好的sql无法得到和之前一样的结果,数据分布会发生变化
- 性能问题:代理键int类型,速度最快,业务主键+日期大概率不会用int存储,效率不如int关联
- 如果有多个日期的数据需要查询,那么就需要重复进行多次查询,这不仅浪费时间,而且可能导致数据不一致的问题。假设有要按类别查询产品一年内的销售额合计,但是产品类别每个月都发生变化,其中包含了每一次的销售记录,每一次的销售记录都要去关联维度表,同时关联售日期。如果你想查询每一个月的销售额,你就需要重复进行 12 次查询。使用代理键和拉链表是一种更好的选择。
三、为什么维度表不储存聚合的指标
- 有违维度表的设计理念,维度表的属性应该具有如下属性:
- 详尽(用完整的词汇来表达)
- 描述性
- 完整(没有缺失值)
- 离散值
- 质量保证(没有拼写错误和不可能的值)
- 如果聚合指标储存在维度表,维度表就会频繁更新,新增的记录过多,拖慢关联速度
- 需要聚合指标可以通过事实表经过简单计算获得,不是很有必要储存在维度表中
- 维度表的主要目的是维护数据仓库中的维度数据,而不是聚合数据。如果把聚合的属性放在维度表中,将导致数据重复和存储空间浪费,并且将增加数据的复杂度,从而影响数据的查询和分析效率。因此,聚合的属性应该放在事实表中。
参考资料
https://zhuanlan.zhihu.com/p/336501748
https://www.cnblogs.com/xqzt/p/4472005.html
https://en.wikipedia.org/wiki/Dimension_(data_warehouse)
https://www.kimballgroup.com/2008/08/slowly-changing-dimensions/
https://medium.com/analytics-vidhya/data-warehouse-tips-and-best-practices-i-wish-i-knew-earlier-51740bedb4b6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号