


利用C++ template进行编译时计算是大家都知道的。这里介绍一种新的C++ template编译时计算。这种方法,据我有限的了解,是头一次在江湖上出现(如果大家知道已经有人实践过这种方法,请告诉我,不过不用到Boost里去找,我已经找过了,没有)。我不练习C++好多年,这个主意是神托梦给我的(当天白天我在搞.net,应该不是“日有所思,夜有所梦”),所以如果大家觉得这种方法很没意思,怪神,不要怪我。
这种方法利用C++ template和C++的类型检查,实现了编译时的SLR(1) parsing。具体的说,有一个用BNF写的语法,把语法中的每个terminal作为一个函数名,我们可以把SLR(1)(或者LL(1),LR(1)都一样,但SLR(1)是最常用的)parsing table编码成几个template定义,使C++在编译时可以检查一串连续的,用“.”分隔的函数调用是否符合这个语法。举个例子,假设有这样一个语法:
A -> 'L' A 'R' |
'x'
那么我们希望以下的C++代码片段能通过编译:
f(){
...
begin().x().end();
begin().L().x().R().end();
begin().L().L().x().R().R().end();
}
因为串x,LxR,LLxRR都是符合A的语法的;而以下的代码在编译时出错:
g(){
...
begin().L().R().end();
begin().L().L().x().R().end();
begin().R().x().L().end();
begin().L().x().R().x().end();
}
因为串LR,LLxR,RxL,LxRx都不符合语法A。
虽然C++ templates的编译时计算虽然是图灵完备的,但这毕竟不是它最初的目的,把它当成一般性的编程语言来进行计算很别扭。好在SLR(1)解析的难点在于构建parsing table,一旦parsing table构建好,只需很简单的操作就可以进行解析了。这里并不涉及parsing table的构建,用C++ template进行语法解析的工作就相对容易了。在进行SLR(1)解析时,需要维持一个解析堆栈,堆栈上的每个元素为解析表中的状态之一。我们怎么用C++的类型系统表示这个堆栈的状态呢?首先我们为每个状态定义一个template class,假设有三个状态0,1,2,那么定义:
template<typename T>
class S0 // representing state 0
{/* ignore members for now*/}
template<typename T>
class S1 // representing state 1
{/* ignore members for now*/}
template<typename T>
class S2 // representing state 2
{/* ignore members for now*/}
我们可以用其中的一个类表示堆栈顶端的元素,用这个类的template parameter表示它后面的元素,这个template paramter的template parameter表示再后面一个元素...以此类推。例如堆栈内容(从底至顶)201可以表示为类型:
S1<S0<S2<void> > >
这里我们将void赋予最底元素的template parameter,意思是它后面就没有东西了。有了表示解析堆栈状态的方法,我们就能勾画出语法解析的基本思路了:每一个函数调用返回一个对象,其类型表示SLR(1)解析器在接受到相应输入后堆栈的状态;这个对象再接受下一个输入(方法调用),返回对象的类型表示新的堆栈状态。按照这个思路开始实施,以此语法为例:
E' -> E 'end'
E -> E 'plus' 'n' | 'n'
它的SLR(1)解析表是这样的:
| State | Input | Goto | ||
|---|---|---|---|---|
| n | plus | end | E | |
| 0 | s2 | 1 | ||
| 1 | s3 | accept | ||
| 2 | r(E->n) | r(E->n) | ||
| 3 | s4 | |||
| 4 | r(E->E plus n) | r(E->E plus n) | ||
表中有两种不同的动作:s后跟数字表示shift,然后往堆栈里压入这个数字表示的状态;r表示reduce,需要从堆栈中pop出一些元素,然后压入Goto一栏里的状态。从表中看出,如果状态0在栈顶,那么下一个输入只能是n而不能是plus或end,且输入n后应该压入状态2,因此这样编码状态0:
template<typename PrevInStack>
struct S0
{
typedef PrevInStack PrevState;
S2<S0<PrevInStack> > n() { return S2<S0<PrevInStack> >(); }
typedef S1<S0<PrevInStack> > GotoEState;
};
当状态0处于堆栈顶端时,堆栈的内容可以由S0<PrevInStack>表示,其中PrevInStack表示除栈顶外的堆栈状态,此时往堆栈压入状态2,堆栈的状态就会变成S2<S0<PrevInStack> >,这就是根据解析表得出的方法n的返回类型。至于GotoEState的作用,马上会出现。
状态1包含accept动作,为此需要定义一个dummy类E:
struct E{};
accept只需返回这个dummy类:
template<typename PrevInStack>
struct S1
{
typedef PrevInStack PrevState;
typedef S3<S1<PrevInStack> > PlusState;
PlusState plus() { return PlusState(); }
typedef E EndState;
EndState end() { return EndState(); }
};
最后我们以状态4为例看reduction动作怎么处理。当解析堆栈的顶部元素是状态4,下一个输入是plus时,需要将堆栈中的三个元素弹出,因为E->E plus n右边有三个符号E,plus和n,然后压入此时堆栈顶部状态对应的Goto状态。Reduction完成后还需输入plus,做shift。在这里我们必须把reduction和shift操作合成一个步骤:
template<typename PrevInStack>
struct S4
{
typedef PrevInStack PrevState;
typename PrevInStack::PrevState::PrevState::GotoEState::PlusState plus()
{ return typename PrevInStack::PrevState::PrevState::GotoEState::PlusState(); }
typename PrevInStack::PrevState::PrevState::GotoEState::EndState end()
{ return typename PrevInStack::PrevState::PrevState::GotoEState::EndState(); }
};
其中PrevInStack::PrevState::PrevState即将三个元素弹出堆栈,然后转到GotoEState,这就是reduction的结果,接着shift,最终的结果就是PrevInStack::PrevState::PrevState::GotoEState::PlusState。至此我们就可以编码整个SLR(1)解析表了。最后,因为SLR解析的初始状态是0,所以这样定义begin函数:
S0<void> begin() { return S0<void>(); }
完整的代码如下:




 typedef PrevInStack PrevState;
typedef PrevInStack PrevState;
 S2
S2 }
}现在可以开始用了,辛苦typing(双关)一阵,吃几颗糖先:
#define n n()
#define plus plus()
#define end end()
#define begin begin()
于是我们可以写这样的语句:
E e1 = begin.n.plus.n.end;
E e2 = begin.n.plus.n.plus.n.end;
而这样的语句,因为不符E的语法,所以编译不了:
E e3 = begin.plus.n.end;
E e4 = begin.n.plus.n.plus.end;
如果在Visual Studio里编辑文件,一个有趣的功能将会出现,Visual Studio的IntelliSense在每一处提示下一个输入可能是什么,只要按照Visual Studio的提示来,写出来的串一定是符合我们定义的语法的:
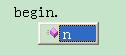
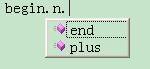
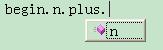
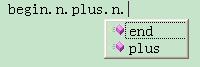
最后也是最关键的问题,这种技术有用吗?我觉得有,这种技术可以用来构建嵌入式DSL。在现有的基础上可以增加生成parse tree或abstract syntax tree的功能,请看下回分解!
谢谢观看!
p.s.写了一通C++,我突然想起C++/CLI来了,有用C++/CLI干事的兄弟吗?


 浙公网安备 33010602011771号
浙公网安备 33010602011771号