
Cassandra 基础知识
Cassandra的配置文件:cassandra-3.11.4-main/conf/cassandra.yaml
目录相关的文件:
data_file_directories:存储表数据(在SSTables里)。Cassandra将数据均匀的分布在这个位置,受配置的压缩策略粒度的限制。
commitlog_directory:存放commit log 。为了获得最佳的写入性能,将commit log放在单独的磁盘分区,或者(理想情况下)和data文件目录分开的物理设备上。commit log只能append
saved_caches_directory:存放table key和row缓存。默认位置:$CASSANDRA_HOME/dataved_caches
hints_directory:设置hints的存储位置(默认: $CASSANDRA_HOME/data/hints)
数据压缩策略:
SizeTieredCompactionStrategy(STCS)
建议在写密集负载中使用
实际使用中如果内存不是很充裕,容易因为SSTable合并过程占用过多内存,导致内存不足,其他节点的Message无法和当前节点交换,最终导致节点宕机。我们可能在cassandra-env.sh中配置了一些参数控制内存的使用,但是并不能限制数据压缩的时候产生的内存损耗。多数建议是关闭自动SSTable压缩,改用手动在空闲期间进行压缩
当有(默认4个)SSTable的大小相似的时候,STCS便会启动。压缩过程将这些SSTable合并成一个大的SSTable。当大的SSTable积累了足够数量,同样的过程会再次发生,组合成更大的SSTable。在任何时候,一些不同大小的SSTable的存在都是暂时的。这种策略在写密集的负载中工作良好,当需要读数据的时候,需要尝试读取多个SSTable来找到一行中的所有的数据。策略无法保证同一行的数据被限制在一小部分的sstable中。同时可以预测删除的数据是不均匀的,因为SSTable的大小是触发压缩的条件,并且SSTable可能增长的不够快以便合并旧的数据。当最大的那些SSTable达到一定大小,合并需要的内存也会增长为同时容纳新的SSTable+ 旧的SStable,可能会超出一个典型节点的内存总量。
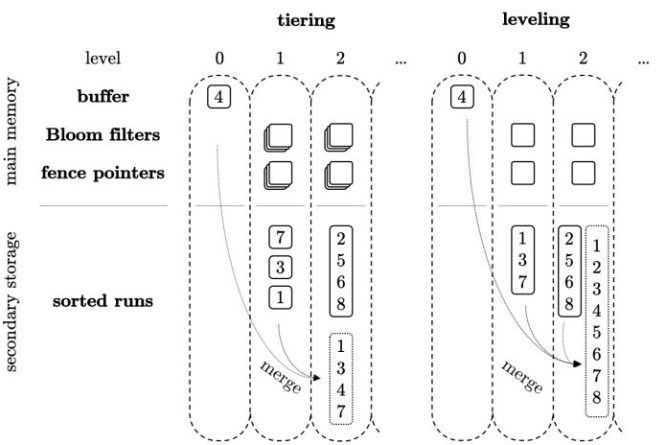
size/Tier compaction里面,每个sstable,也就是每个方框里面数组是sort的,这没问题,但是level2里面,[1,3,4,7], [2,5,6,8]并不能组成一个Run,因为key range是overlap的。所以不能保证每个level只有一个Run。比如我查找5,那么5在两个range<2,8>,<1,7>里面都符合条件,没法一下用Binary search确定在哪个sstable。
leveling compaction 刚好相反,注意在level 1 merge到level 2时候,level 1的数据和本身level2的会再compaction,形成了唯一一个“Run”, 在查找的时候能更快找到。当然付出的代价就是需要更频繁的compaction。
LeveledCompactionStrategy(LCS)
建议用在读占比高的情况。
在Disk 里面维持了多级level的SStable,而且每层维持“唯一一个”Run。run需要满足两个条件:第一sorted,第二non-overlapping key ranges。
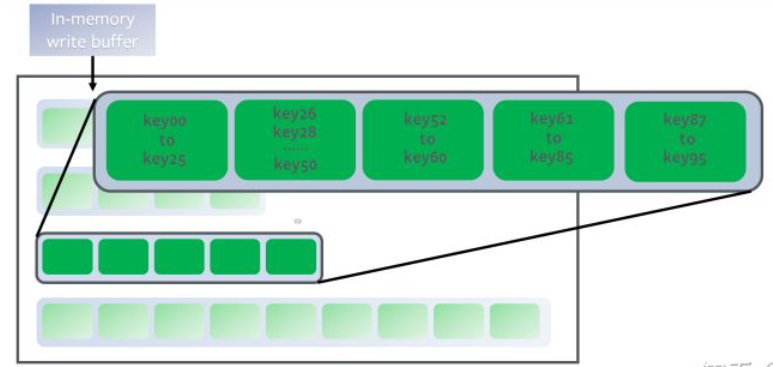
每层维护“唯一一个”run, 注意里面的key不仅仅sort,而且non-overlap
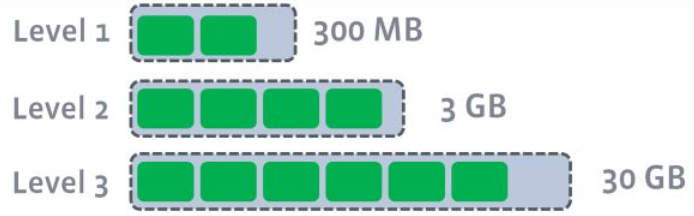
每层的大小是上一级的T(图里是10) 倍,层数越高,data越多但是也越旧.每层都有target size
compaction的过程可以简化成:in memory的table写满了,那么就flush到第一级的Disk SStable并且做compaction,要是第一级又满了,就又开始flush到第二级做compaction,以此类推直到max level,。
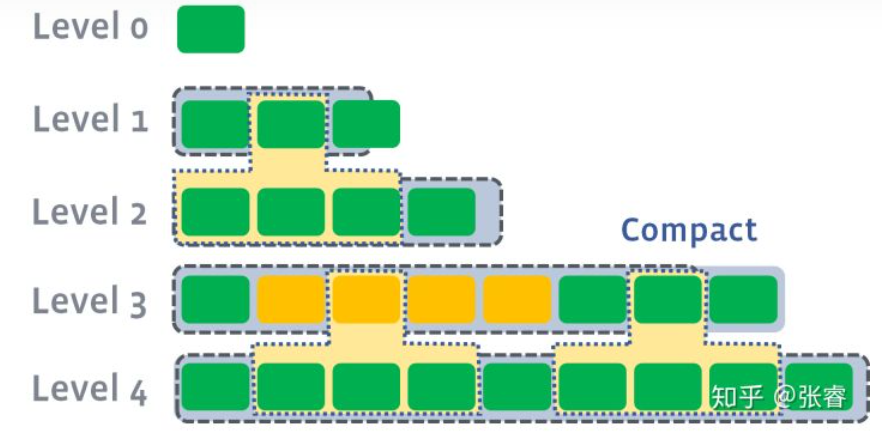
Level compaction目标就是维持每个level都保持住one data sorted run,所以每个level都可以和下一个level做compaction,同时很有可能会被上一个level做compaction。
LSM 写放大和读放大
LSM写放大:Write amplification意味着同一个记录需要被多次写入Disk,数字越大就意味着Disk write越多。显然leveling需要更频繁不停的compaction保证每个level只有一个Run,所以其 Write Amplifier 更大。
LSM读放大:Read amplification意味着查询一个记录,需要读多少次Disk,数字越大意味Disk Read越多(还是用收拾房间理解,就是意味着在房间里面找到需要的东西需要翻箱倒柜多少次)。Leveling compaction相对每次更新compaction更频繁,保证每个level 唯一Run,所以Read Amplifier比Tier的compaction有优势。
LSM空间放大:Space Amplifier意味着要达到最终理想状态,需要多余多少Disk space放临时compaction时候中间结果。数字越大意味着Disk overhead越多(还是用收拾房间理解,就是意味着需要更多杂物间临时堆放东西)收拾更勤快的leveling compaction相对而言space Amplifier更小
value比较大的时候Compaction的问题尤其明显,期间sstable的读写都是将key-value一起进行的,value过大时效率便会很低。这些放大的影响在HDD上抵消磁盘的Seek消耗还是值得的。但是SSD就不一样了,SSD随机读写要快的多,并且可以使用其并行随机读取的特性。LSM适用于小value的场景,在对象场景中不适用,因此就需要把key-value分离存储来适应更多的场景。
参考:BadgerDB源码分析之Wisckey论文 (shimingyah.github.io)
LSM Tree的Leveling 和 Tiering Compaction - 知乎 (zhihu.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号