MySQL十一:索引基本原理
转载~
在上一篇《索引基础知识回顾》中提到索引按照存储结构划分有B-Tree索引、Hash索引、B+Tree索引类型,接下来就学习一下这几种索引结构以及在实际存储引擎中的使用情况
一、Hash索引
「Hash底层是由Hash表来实现的,存储引擎都会【对所有的索引列计算一个哈希码】(hash code),哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针,根据键值 <key,value> 存储数据的结构存储<哈希码,指针>,非常适合根据key查找value值,也就是等值查询(单个key查询)」。其结构如下所示:
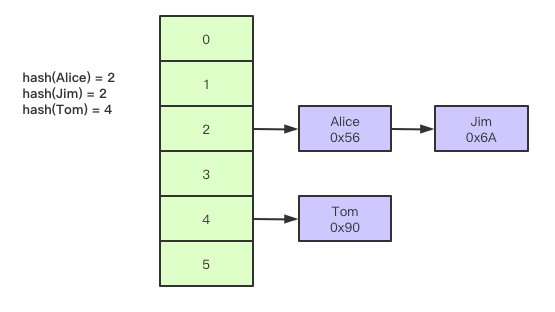
-
「Hash索引优缺点」
-
哈希表按值查询的性能很好,时间复杂度是O(1),在等值查询的时候hash索引要比B+ 树索引更高效,
-
「Hash索引缺点」
这也是为什么用树,而不用哈希表的原因
-
- 存在 hash 冲突问题
- 仅能支持【等值查询】,当查询条件为【范围查找(如:in)】就会全表扫描。
Hash索引在MySQL 中Hash结构主要应用在Memory原生的Hash索引 、InnoDB 自适应哈希索引。在《InnoDB的存储结构》已经介绍过自适应哈希索引,这里不再赘述。
二、B-Tree索引
「平衡多路查找树(B-Tree):是为磁盘等外存储设备设计的一种平衡查找树」。
「我们知道在InnoDB存储引擎中页是其磁盘管理的最小单位,默认是16KB,而系统一个磁盘块的存储空间没有这么大,因此InnoDB每次申请磁盘空间时都会申请若干地址连续磁盘块来达到页的大小16KB。在查询时如果数据都在一个页中,会减少磁盘I/O次数,提高查询效率。」
「B-Tree结构的数据可以让系统高效的找到数据所在的磁盘块」。它每个节点根据实际情况可以包含大量的关键字信息和分支,下图为一个3阶的B-Tree:

由上图中可以看出B-Tree有如下「特征」:
-
每个节点占用一个磁盘块的磁盘空间
-
一个节点上有两个升序排序的关键字和三个指向子树根节点的指针
-
- 指针存储的是子节点所在磁盘块的地址
- 两个关键字划分成的三个范围域对应三个指针指向的子树的数据的范围域
模拟查找关键字29的过程:
-
根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】
关键字为17和35,P1指针指向的子树的数据范围为小于17,P2指针指向的子树的数据范围为17~35,P3指针指向的子树的数据范围为大于35。
-
比较关键字29在区间(17,35),找到磁盘块1的指针P2。
-
根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】
-
比较关键字29在区间(26,30),找到磁盘块3的指针P2。
-
根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】
-
在磁盘块8中的关键字列表中找到关键字29。
通过以上过程,我们查找29,只需要三次IO,「而3阶的B-Tree可以容纳百万级数据,这对查询性能的提升是巨大的」。如果没有索引,每个数据项都要发生一次IO,总共需要百万次的IO,显然成本非常非常高。
三、B+Tree索引
「B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构」。
在上述中提到数据页的存储空间默认是16KB,而B-Tree结构图中可以看到每个节点中不仅包含数据的key值,还有data值。当数据较大时,一个节点(即一个页)能存储的key的数量就会很小,导致B-Tree的深度变大,增大查询时的磁盘I/O次数,进而影响查询效率。
对此,「B+Tree进行了优化,将所有数据都是按照键值大小顺序存放在同一层的叶子节点上,非叶子节点上只存储key值,以此增大每个节点存储的key值数量,降低B+Tree的高度」。下图为一个3阶的B+Tree:
通过示意图可以看出「B+Tree不仅仅将数据存放在叶子结点,而且所有叶子节点(数据节点)之间都有一个链指针,从而方便叶子节点的范围遍历」。特征如下:
- 所有关键字都「有序的」出现在叶子结点的链表中(稠密索引)。
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层。
- 每一个叶子节点都包含指向下一个叶子节点的指针,从而方便叶子节点的范围遍历。
四、MySQL索引实现
「MySQL中索引属于存储引擎级别的概念,MyISAM和InnoDB都是使用B+Tree作为索引结构,但是不同存储引擎对索引的实现方式不同」。
4.1 MyISAM索引实现
在《存储引擎》一文中介绍到MyISAM针对每个表有两个文件:「一个.frm表结构文件,一个MYD表数据文件,一个.MYI索引文件」。数据和索引是分开存储的。
「MyISAM使用B+Tree作为索引结构时,.MYI索引文件的叶节点的data域存放的是数据记录的地址」。
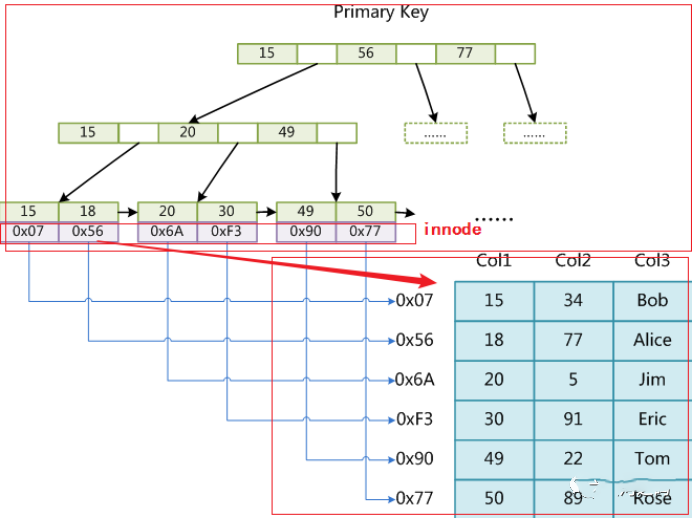
按照示意图:MyISAM在索引检索时首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
「在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复」。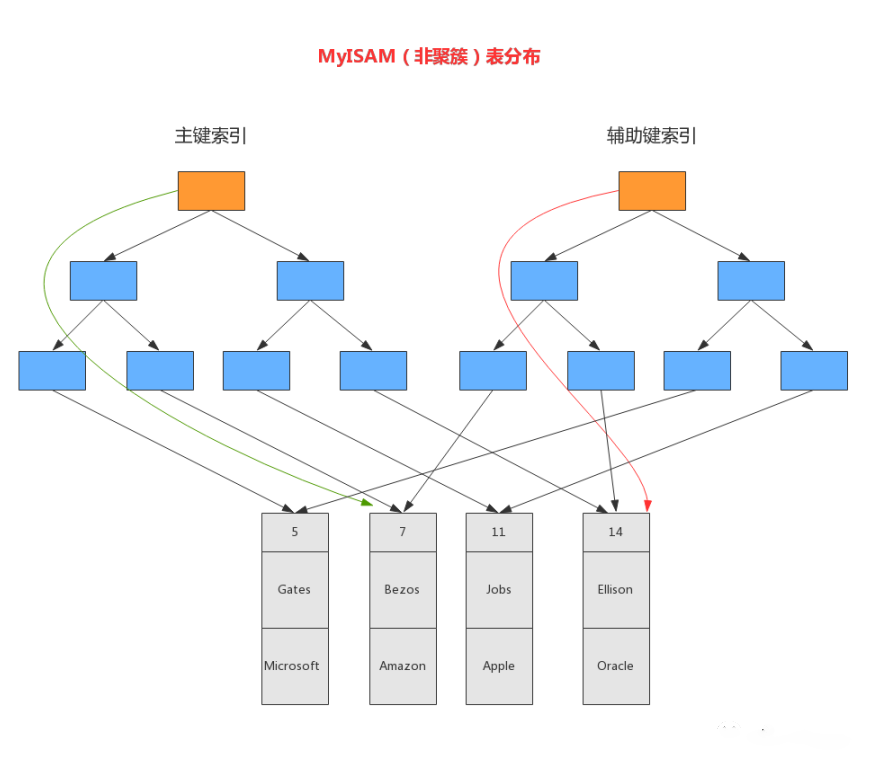
4.2 InnoDB索引实现
在《存储引擎》一文中介绍到InnoDB针对每个表有两个文件:「一个.frm表结构文件,一个.ibd数据文件」,数据和索引是一起存储的,定位到了数据也就找到了数据。
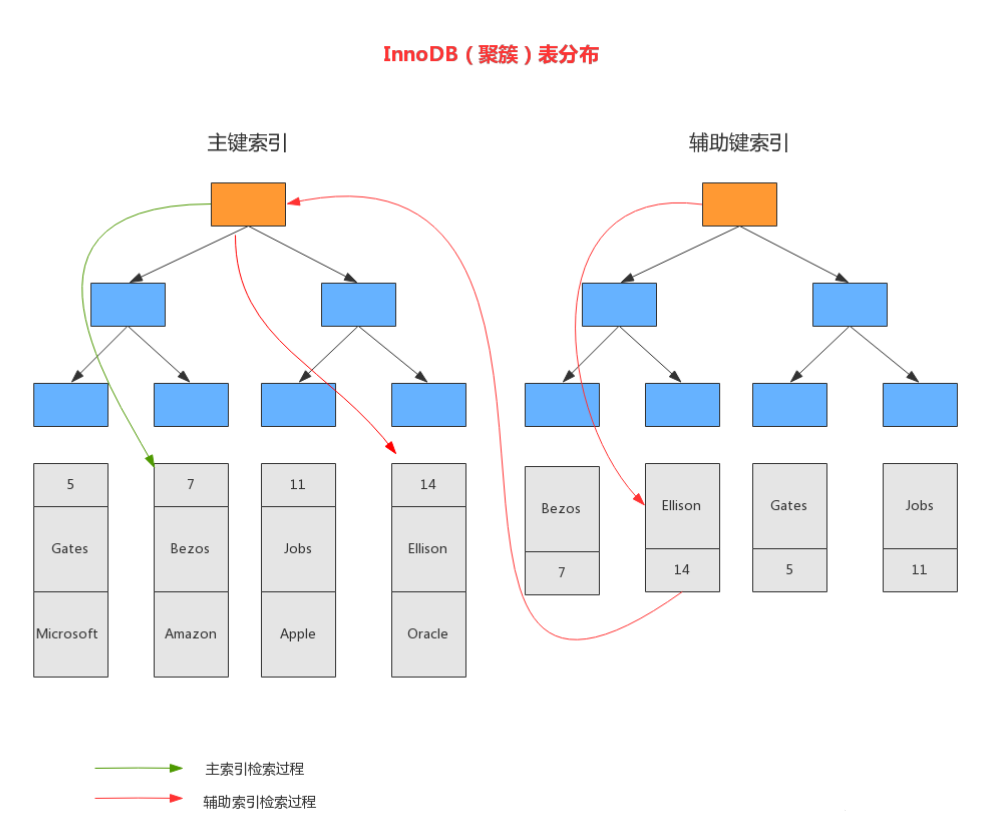
4.2.1聚簇索引(聚集索引)
「InnoDB的聚簇索引就是按照主键顺序构建 B+Tree结构。叶子节点data域存储了完整的数据记录,行记录和主键值紧凑地存储在一起。即 InnoDB 的主键索引就是数据表本身,它按主键顺序存放了整张表的数据,占用的空间就是整个表数据量的大小。」
-
InnoDB的表要求必须要有聚簇索引:
-
- 如果表定义了主键,则主键索引就是聚簇索引
- 如果表没有定义主键,则第一个非空unique列作为聚簇索引
- 都没有InnoDB会从建一个隐藏的row-id作为聚簇索引
-
聚簇索引示意图:
4.2.2辅助索引(二级索引)
「在InnoDB中,主索引和辅助索引(Secondary key)的Data域存储是不同的」,这与MyISAM是不同的。
- 「但在 B+Tree 的叶子节点中只存了【索引列和主键】的信息。二级索引占用的空间会比聚簇索引小很多, 通常创建辅助索引就是为了提升查询效率。一个表InnoDB只能创建一个聚簇索引,但可以创建多个辅助索引」。
如示意图所示,辅助索引索引中data域中存储的是主键,所以辅助索引一般需要两次查找才能查到数据:
- 「第一次通过辅助索引找到主键列的值」
- 「第二次通过主键列的值在聚簇索引中查找数据」

 浙公网安备 33010602011771号
浙公网安备 33010602011771号