Spark的安装与配置
安装Scala
Spark编程语言可以使用Scala, Python, Java, R等。使用Scala可以用相比其他语言获得更简洁的代码,并且可以在Spark-Shell中调试。Spark的实现也使用了Scala所带来的好处,整个源码大小没有过万。 Scala是一种基于JVM的函数式编程语言。描述问题较Java在WordCount程序上就可看到其简洁性。而Scala同时也支持原生Java函数调用,使用反编译后会发现Scala原来是在编译前期提供语法糖来支持其语言的简洁性。解压到 /usr/local下
配置环境变量SCALA_HOME和PATH
安装Spark
spark依赖hadoop的HDFS和YARN,官网提供了自带hadoop和独立两种tgz包的下载,因hadoop已配置完成,在这里下载独立的spark安装包。
解压到 /hadoop2.6下
配置环境变量SPARK_HOME和PATH
使用which spark-shell检查路径是否正确
复制一份spark的配置脚本
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
加入以下导出变量语句。需要hadoop的bin路径已配好。
export SPARK_DIST_CLASSPATH=$(hadoop classpath)
spark-shell启动spark


Spark启动的欢迎界面信息量很大,咱们可以看到,
开启shell时:SecurityManager修改访问控制列表给当前用户,并且关闭认证和ui的ACLs,当前用户拥有视图权限。开启了一个HTTP类服务器(干吗用的?)。开启log功能。是使用AKKA创建在本地监听Actor。显示内存容量和开启web ui。将本shell作为一个driver作业提交。开启NettyBlockTransferService服务(干吗的?)。注册BlockManager。创建sc和sqlContent。
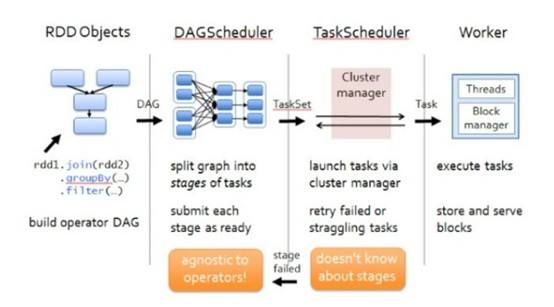
关闭shell时:
以与开启相反的顺序释放内存与关闭服务。

Spark的RDD即弹性分布式数据集合,将分布式的数据集合抽象成统一的界面。可以把本地或者HDFS中的数据通过textFile读入到各节点的内存中,并且经过一系列transformation操作后生成新的内存RDD,spark的app在这些transformation中不会立即求值,当出现action操作时,例如count,collect,take等才会真正开始计算。
提供血统检查点和缓存机制。各transformation转换形成一个有向无环图,两个有转换关系的transformation形成节点的前驱后继关系,这样一张图提供调度信息,同时当集群中有节点宕机,只需根据”血统“关系恢复部分RDD就可以了。缓存就是把某transformation的结果写入磁盘。这两种机制都是Spark提供的数据计算可靠性和性能提升的改进。
另外,Scala的AKKA包提供异步消息通信机制,通过ActorSystem实例化Actor,用树形结构管理层次化actor节点,而每个actor只占用极少内存,actor的关闭和通知是以广播方式传递的。actor支持阻塞和异步future返回两种模式。
没想到快半年了,中间没有看任何spark相关资料,我竟然还能想起来这么多。。。
这下环境都已配好,以后的关注点就在具体的应用上了。比如写个评论分析,日志分析,配合爬虫分析的应用了。此外关注源码分析,只有知道底层实现才能更好的使用这些强大的工具。FIGHT!还有3个月时间了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号