mysql-select 学习
http://xuesql.cn/ sql自学网
source /home/shiyanlou/Desktop/MySQL-04-01.sql //在mysql中,执行sql文件
select的基本格式:SELECT 要查询的列名 FROM 表名字 WHERE 限制条件;
SELECT name,age FROM employee;
SELECT name,age FROM employee WHERE age>25;
SELECT name,age FROM employee WHERE age<25 OR age>30;
#筛选出 age 大于 25,且 age 小于 30
SELECT name,age FROM employee WHERE age>25 AND age<30;
SELECT name,age FROM employee WHERE age between 25 and 30 ; // 在25和30之间,包含25和30
#筛选在部门dpt3和dpt4的人员
SELECT name,age,phone,in_dpt FROM employee WHERE in_dpt IN ('dpt3','dpt4');
SELECT name,age,phone,in_dpt FROM employee WHERE in_dpt NOT IN ('dpt1','dpt3'); //不在这两个部门的人员
#通配符
#like 可用于实现模糊查询,常用于搜索功能中。 与like联用的还有通配符,通配符:_和%。其中_代表一个 1101未指定字符,%代表不定个未指定字符
#查找以1101开头的6位数的电话号码
SELECT name,age,phone FROM employee WHERE phone LIKE '1101__';
#比如只记名字的首字母,又不知道名字长度,则用 % 通配符代替不定个字符
SELECT name,age,phone FROM employee WHERE name LIKE 'J%';
#对结果进行排序
#order by:升序 asc 和desc 可以指定升序和降序
#按照salary的降序排列
SELECT name,age,salary,phone FROM employee ORDER BY salary DESC;
# 内置函数和计算,含有5个内置函数, count:计数, sum:求和, avg:求平均值 max:最大值 min:最小值
#计算salary(表里的列)的最大值和最小值
SELECT MAX(salary) AS max_salary,MIN(salary) FROM employee; #as关键词是给此值重新命名
#想要知道名为 "Tom" 的员工所在部门做了几个工程。员工信息储存在 employee 表中,但工程信息储存在 project 表中
SELECT of_dpt,COUNT(proj_name) AS count_project FROM project
GROUP BY of_dpt
HAVING
of_dpt IN
(SELECT in_dpt FROM employee WHERE name='Tom'); #having 关键字的作用和where一样的, having用于对分组后的数据进行筛选
#连接查询 join
#在处理多个表时,子查询只有在结果来自一个表时才有用。但如果需要显示两个表或多个表中的数据,这时就必须使用连接 (join) 操作。 连接的基本思想是把两个或多个表当作一个新的表来操作
SELECT id,name,people_num FROM employee,department WHERE employee.in_dpt = department.dpt_name ORDER BY id; 得到一个新表
SELECT id,name,people_num FROM employee JOIN department ON employee.in_dpt = department.dpt_name ORDER BY id; 同上一个语句的效果是一样的
#使用连接查询的方式,查询出各员工所在部门的人数与工程数,工程数命名为 count_project。(连接 3 个表,并使用 COUNT 内置函数)
SELECT name, people_num, COUNT(proj_name) AS count_project
FROM employee, department, project
WHERE in_dpt = dpt_name AND of_dpt = dpt_name
GROUP BY name, people_num;
#删除数据库
DROP DATABASE test_01; #test_01 数据库名
#对一张表进行修改
RENAME TABLE 原名 TO 新名字; #对表重命名
ALTER TABLE 原名 RENAME 新名;#对表重命名
ALTER TABLE 原名 RENAME TO 新名;#对表重命名
DROP TABLE 表名字; #删除一张表
ALTER TABLE 表名字 ADD COLUMN 列名字 数据类型 约束; #增加一列
或: ALTER TABLE 表名字 ADD 列名字 数据类型 约束; #增加一列
ALTER TABLE employee ADD height INT(4) DEFAULT 170; #default 是指当为空时默认填充170
ALTER TABLE employee ADD weight INT(4) DEFAULT 120 AFTER age; #对插入的列,指定放在age列的后面
ALTER TABLE employee ADD test INT(10) DEFAULT 11 FIRST; #对插入的列,放在首列,用first
ALTER TABLE 表名字 DROP COLUMN 列名字; 或: ALTER TABLE 表名字 DROP 列名字; #删除某一列
ALTER TABLE 表名字 CHANGE 原列名 新列名 数据类型 约束; #重命名一列,准确的说是对一列进行修改 change
ALTER TABLE 表名字 MODIFY 列名字 新数据类型; #该表某一列的数据类型。 修改数据类型可能会导致数据丢失。在尝试修改前,请慎重考虑
UPDATE 表名字 SET 列1=值1,列2=值2 WHERE 条件; #修改表中的某一个字段
DELETE FROM 表名字 WHERE 条件; #删除一行记录
ALTER TABLE 表名字 ADD INDEX 索引名 (列名); CREATE INDEX 索引名 ON 表名字 (列名);#两种创建索引的句式
视图:视图是从一个或多个表中导出来的表,是一种虚拟存在的表。它就像一个窗口,通过这个窗口可以看到系统专门提供的数据,这样,用户可以不用看到整个数据库中的数据,而只关心对自己有用的数据
注意理解视图是虚拟的表:
- 数据库中只存放了视图的定义,而没有存放视图中的数据,这些数据存放在原来的表中;
- 使用视图查询数据时,数据库系统会从原来的表中取出对应的数据;
- 视图中的数据依赖于原来表中的数据,一旦表中数据发生改变,显示在视图中的数据也会发生改变;
- 在使用视图的时候,可以把它当作一张表。
CREATE VIEW 视图名(列a,列b,列c) AS SELECT 列1,列2,列3 FROM 表名字; #创建视图的语句格式
source 目录/xxx.sql #导入sql文件,执行sql语句
load data infile '文件路径和文件名' into table 表名字;#导入数据文件,由于导入导出大量数据都属于敏感操作,根据 mysql 的安全策略,导入导出的文件都必须在指定的路径下进行,在 mysql 终端中查看路径变量,show variables like ‘%secure%’;
注意到 secure_file_priv 变量指定安全路径为 /var/lib/mysql-files/ ,要导入数据文件,需要将该文件移动到安全路径下 sudo cp -a /home/shiyanlou/Desktop/in.txt /var/lib/mysql-files/
SELECT 列1,列2 INTO OUTFILE '文件路径和文件名' FROM 表名字; #导出,注意:语句中 “文件路径” 之下不能已经有同名文件
备份:
mysqldump -u root 数据库名>备份文件名; #备份整个数据库 mysqldump -u root 数据库名 表名字>备份文件名; #备份整个表 ,mysqldump 是一个备份工具,因此该命令是在终端中执行的,而不是在 mysql 交互环境下
恢复:
还有另一种方式恢复数据库,但是在这之前我们先使用命令新建一个空的数据库 test,然后退出mysql, mysql -u root test < bak.sql # bak.sql是备份文件
求唯一值: 两种方法 distinct 和group by
SELECT DISTINCT column, another_column, … FROM mytable WHERE condition(s);
通过Limit选取部分结果
LIMIT 和 OFFSET 子句通常和ORDER BY 语句一起使用,当我们对整个结果集排序之后,我们可以 LIMIT来指定只返回多少行结果 ,用 OFFSET来指定从哪一行开始返回。你可以想象一下从一条长绳子剪下一小段的过程,我们通过 OFFSET 指定从哪里开始剪,用 LIMIT 指定剪下多少长度。
SELECT column, another_column, … FROM mytable WHERE condition(s) ORDER BY column ASC/DESC LIMIT num_limit OFFSET num_offset;SELECT column, another_table_column, … FROM mytable (主表) INNER JOIN another_table (要连接的表) ON mytable.id = another_table.id (想象一下刚才讲的主键连接,两个相同的连成1条) WHERE condition(s) ORDER BY column, … ASC/DESC LIMIT num_limit OFFSET num_offset;SELECT column, another_column, … FROM mytable INNER/LEFT/RIGHT/FULL JOIN another_table ON mytable.id = another_table.matching_id WHERE condition(s) ORDER BY column, … ASC/DESC LIMIT num_limit OFFSET num_offset;INNER JOIN 语法几乎是一样的. 我们看看这三个连接方法的工作原理:在表A 连接 B,
LEFT JOIN保留A的所有行,不管有没有能匹配上B 反过来 RIGHT JOIN则保留所有B里的行。最后FULL JOIN 不管有没有匹配上,同时保留A和B里的所有行 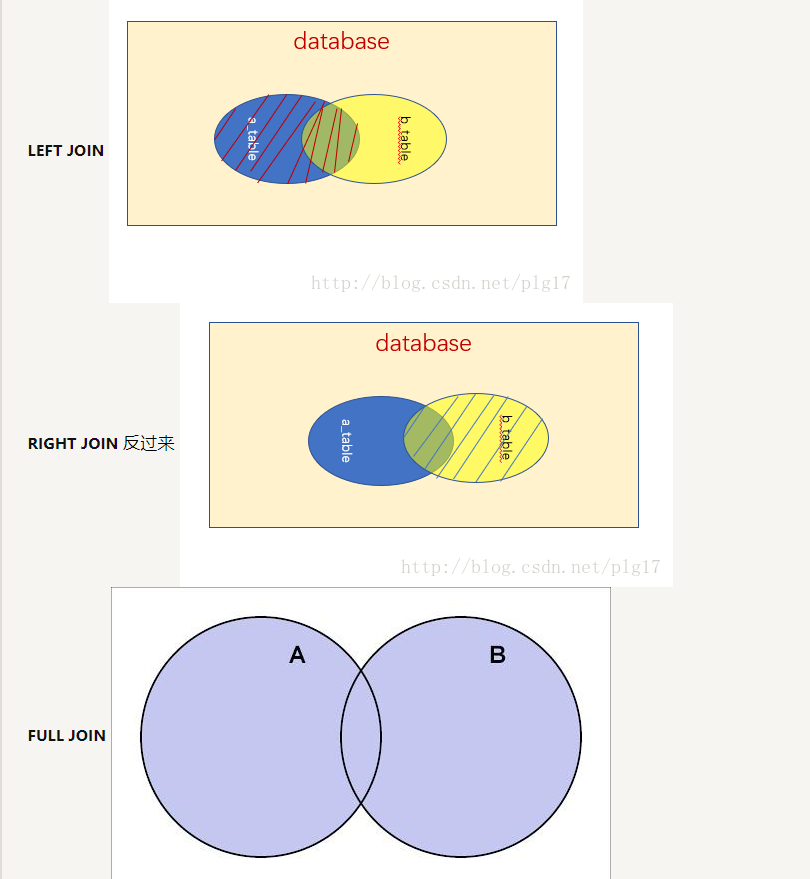

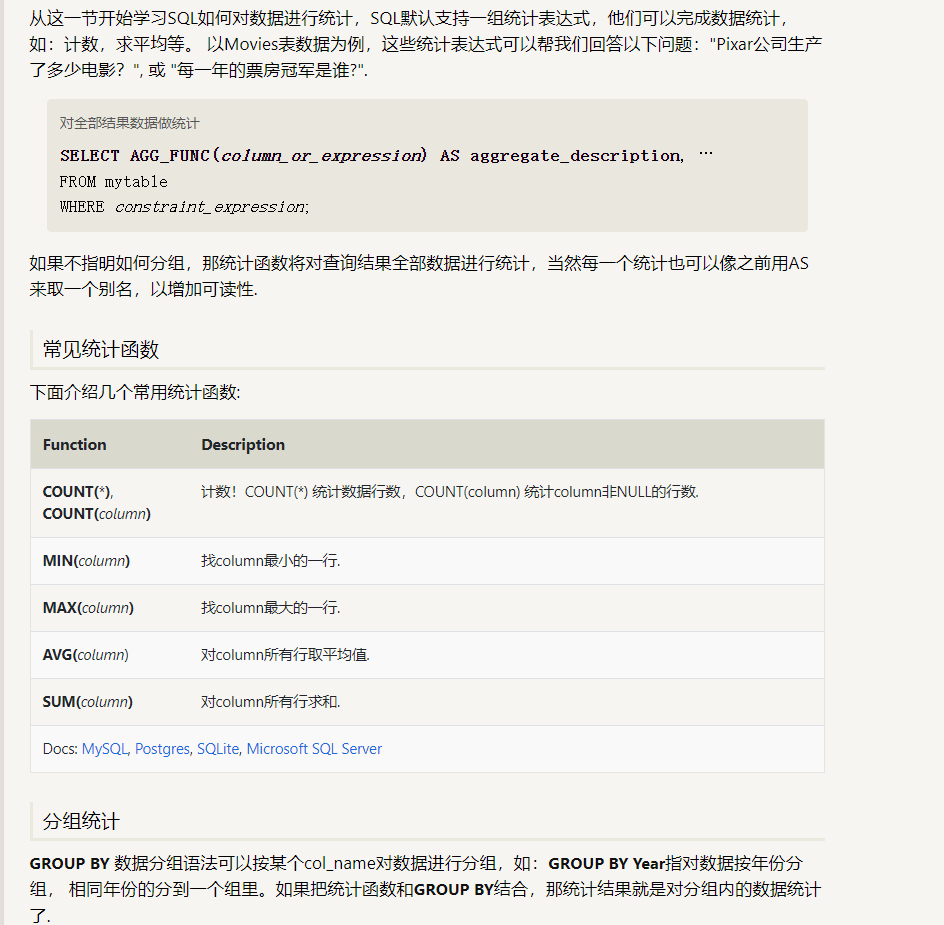
SELECT AGG_FUNC(column_or_expression) AS aggregate_description, … FROM mytable WHERE constraint_expression GROUP BY column;
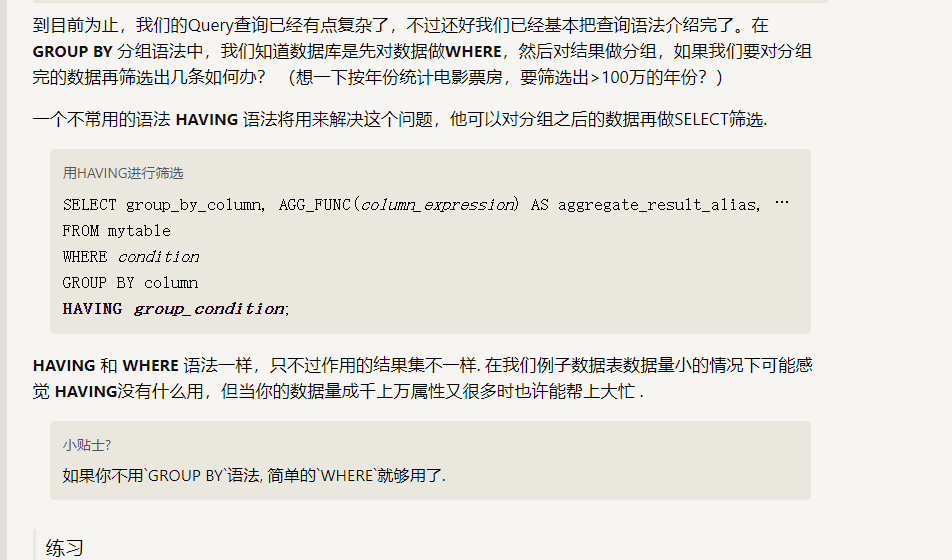
SELECT DISTINCT column, AGG_FUNC(column_or_expression), … FROM mytable JOIN another_table ON mytable.column = another_table.column WHERE constraint_expression GROUP BY column HAVING constraint_expression ORDER BY column ASC/DESC LIMIT count OFFSET COUNT;
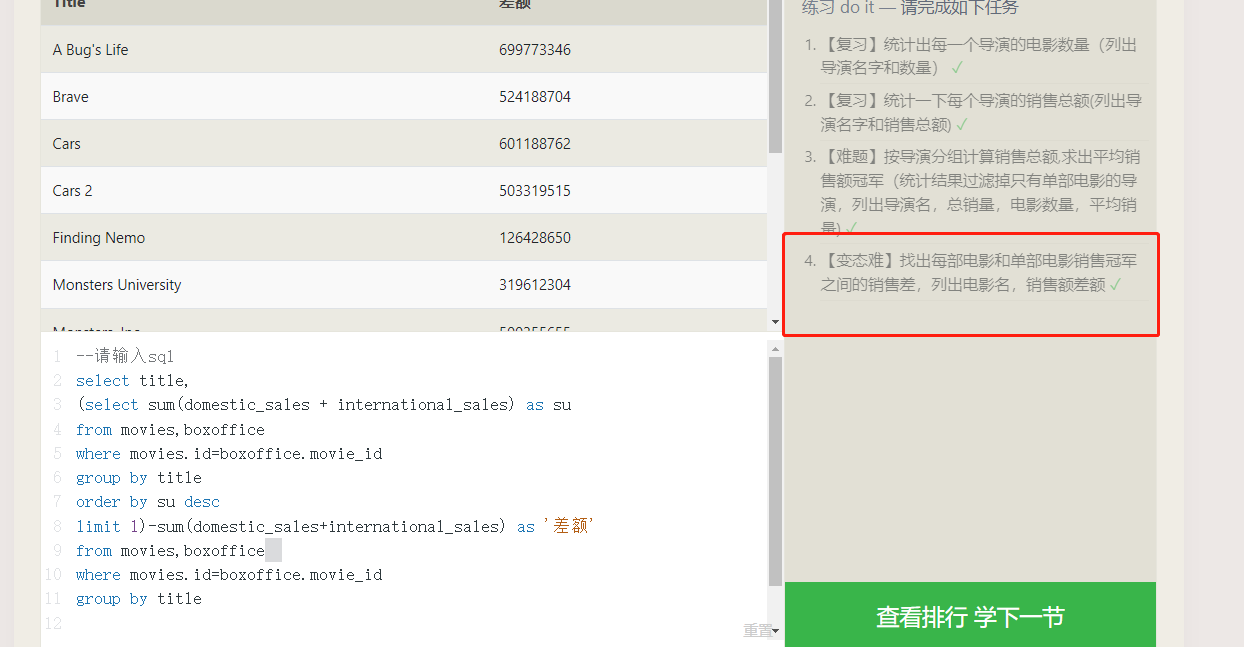

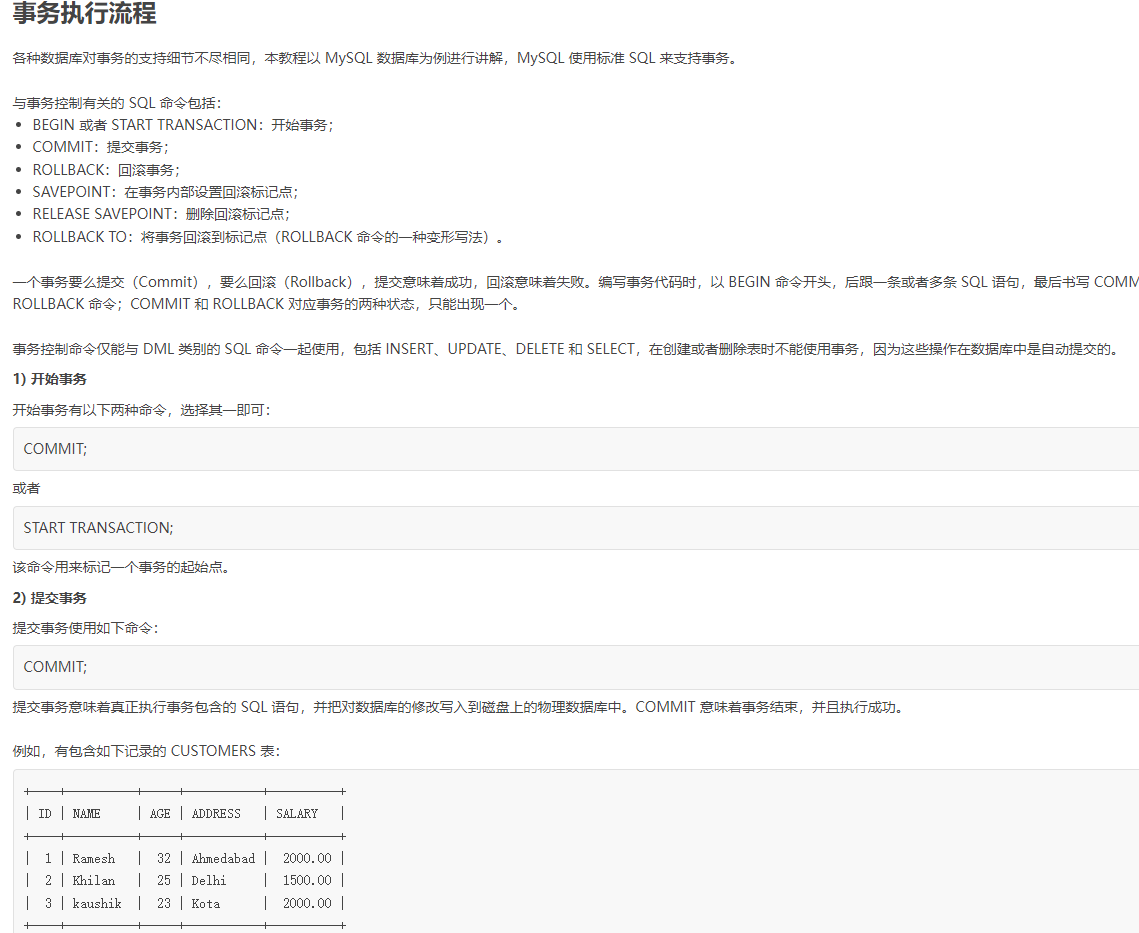
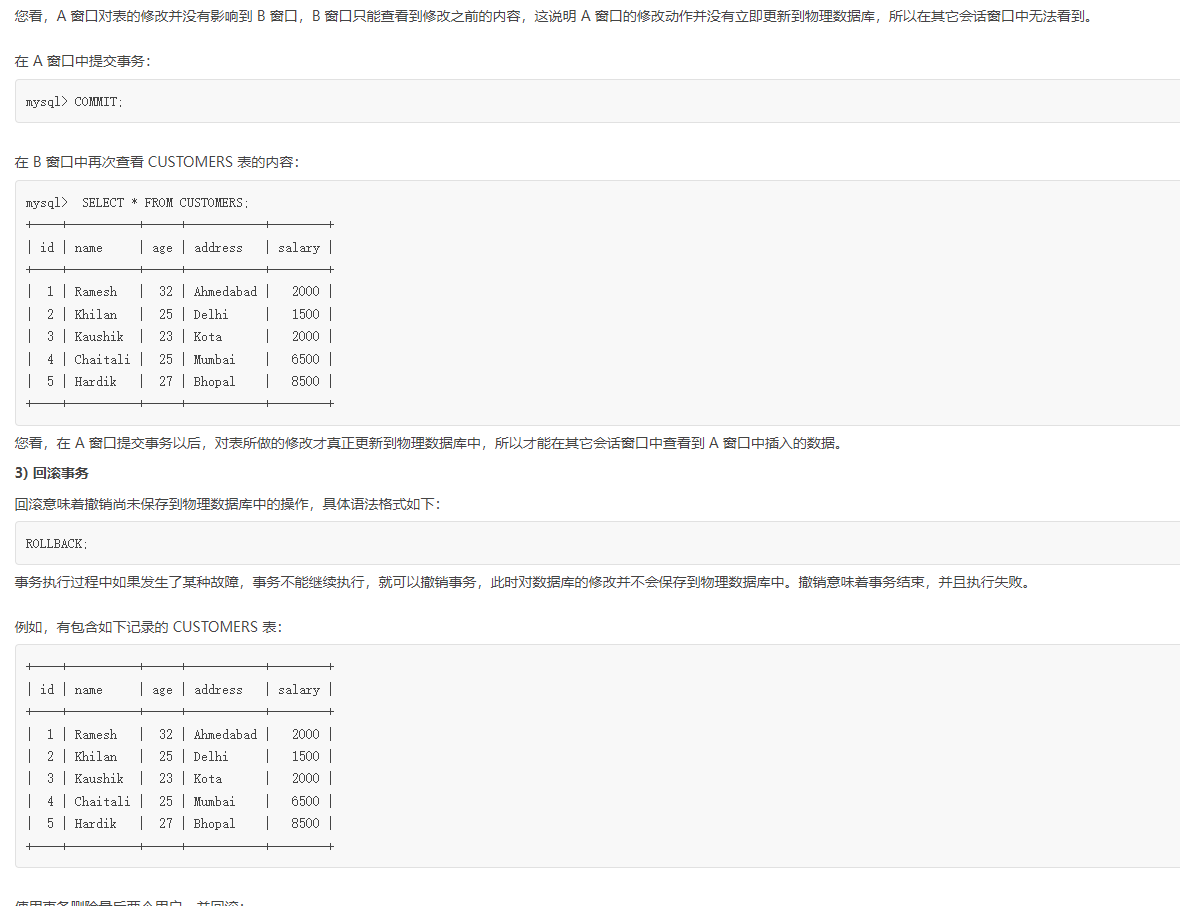
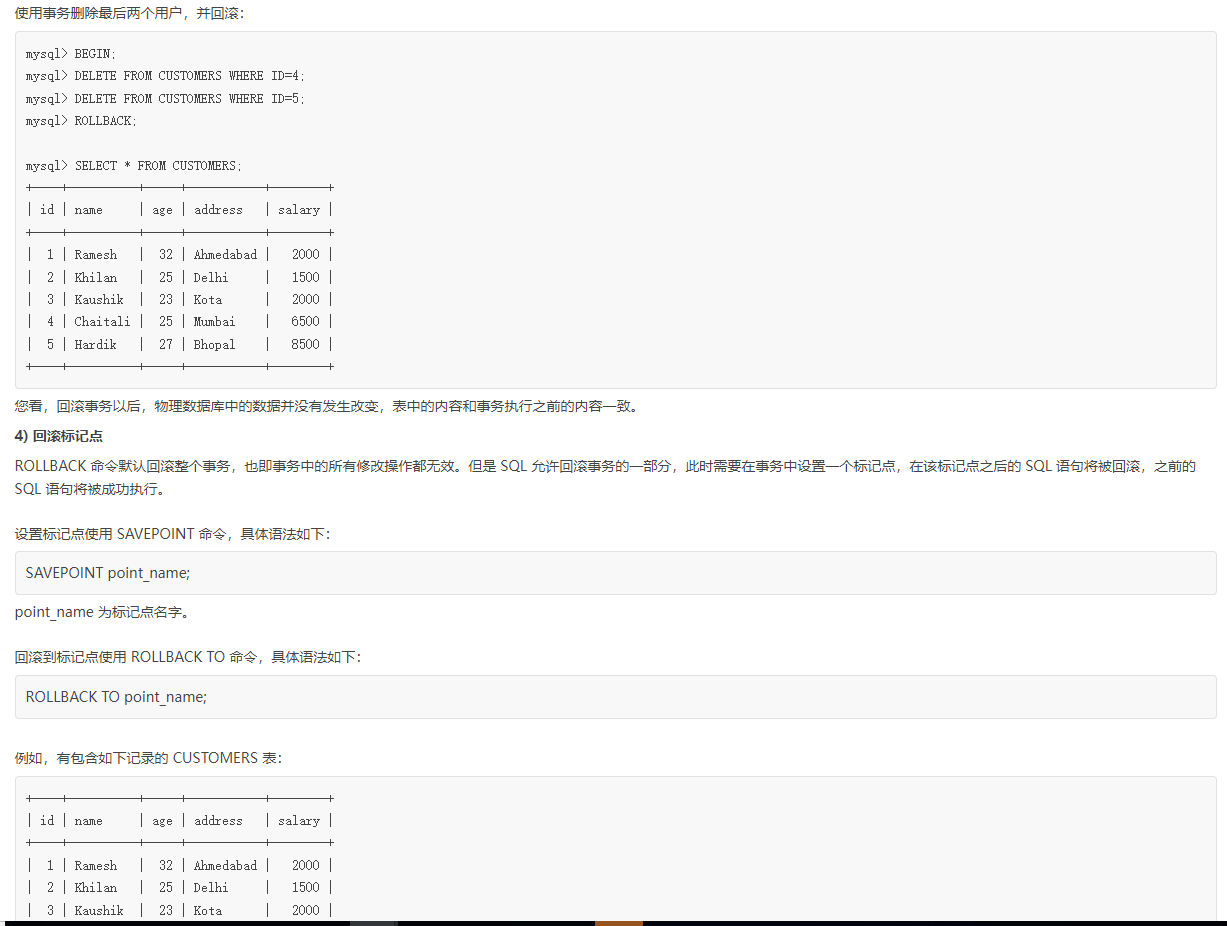

 浙公网安备 33010602011771号
浙公网安备 33010602011771号