《ElasticSearch6.x实战教程》之简单搜索、Java客户端(上)
第五章-简单搜索
关注公众号:CoderBuff,回复“es”获取《ElasticSearch6.x实战教程》完整版PDF。
众里寻他千百度
搜索是ES的核心,本节讲解一些基本的简单的搜索。
掌握ES搜索查询的RESTful的API犹如掌握关系型数据库的SQL语句,尽管Java客户端API为我们不需要我们去实际编写RESTful的API,但在生产环境中,免不了在线上执行查询语句做数据统计供产品经理等使用。
数据准备
首先创建一个名为user的Index,并创建一个student的Type,Mapping映射一共有如下几个字段:
-
创建名为user的Index
PUT http://localhost:9200/user -
创建名为student的Type,且指定字段name和address的分词器为
ik_smart。POST http://localhost:9200/user/student/_mapping { "properties":{ "name":{ "type":"text", "analyzer":"ik_smart" }, "age":{ "type":"short" } } }
经过上一章分词的学习我们把text类型都指定为ik_smart分词器。
插入以下数据。
POST localhost:9200/user/student
{
"name":"kevin",
"age":25
}
POST localhost:9200/user/student
{
"name":"kangkang",
"age":26
}
POST localhost:9200/user/student
{
"name":"mike",
"age":22
}
POST localhost:9200/user/student
{
"name":"kevin2",
"age":25
}
POST localhost:9200/user/student
{
"name":"kevin yu",
"age":21
}
按查询条件数量维度
无条件搜索
GET http://localhost:9200/user/student/_search?pretty
查看索引user的student类型数据,得到刚刚插入的数据返回:
单条件搜索
ES查询主要分为term精确搜索、match模糊搜索。
term精确搜索
我们用term搜索name为“kevin”的数据。
POST http://localhost:9200/user/student/_search?pretty
{
"query":{
"term":{
"name":"kevin"
}
}
}
既然term是精确搜索,按照非关系型数据库的理解来讲就等同于=,那么搜索结果也应该只包含1条数据。然而出乎意料的是,搜索结果出现了两条数据:name="kevin"和name="keivin yu",这看起来似乎是进行的模糊搜索,但又没有搜索出name="kevin2"的数据。我们先继续观察match的搜索结果。
match模糊搜索
同样,搜索name为“kevin”的数据。
POST http://localhost:9200/user/student/_search?pretty
{
"query":{
"match":{
"name":"kevin"
}
}
}
match的搜索结果竟然仍然是两条数据:name="kevin"和name="keivin yu"。同样,name="kevin2"也没有出现在搜索结果中。
原因在于term和match的精确和模糊针对的是搜索词而言,term搜索不会将搜索词进行分词后再搜索,而match则会将搜索词进行分词后再搜索。例如,我们对name="kevin yu"进行搜索,由于term搜索不会对搜索词进行搜索,所以它进行检索的是"kevin yu"这个整体,而match搜索则会对搜索词进行分词搜索,所以它进行检索的是包含"kevin"和"yu"的数据。而name字段是text类型,且它是按照ik_smart进行分词,就算是"kevin yu"这条数据由于被分词后变成了"kevin"和"yu",所以term搜索不到任何结果。
如果一定要用term搜索name="kevin yu",结果出现"kevin yu",办法就是在定义映射Mapping时就为该字段设置一个keyword类型。
为了下文的顺利进行,删除DELETE http:localhost:9200/user/student重新按照开头创建索引以及插入数据吧。唯一需要修改的是在定义映射Mapping时,name字段修改为如下所示:
{
"properties":{
"name":{
"type":"text",
"analyzer":"ik_smart",
"fields":{
"keyword":{
"type":"keyword",
"ignore_abore":256
}
}
},
"age":{
"type":integer
}
}
}
待我们重新创建好索引并插入数据后,此时再按照term搜索name="kevin yu"。
POST http://localhost:9200/user/student/_search
{
"query":{
"term":{
"name.keyword":"kevin yu"
}
}
}
返回一条name="kevin yu"的数据。按照match搜索同样出现name="kevin yu",因为name.keyword无论如何都不会再分词。
在已经建立索引且定义好映射Mapping的情况下,如果直接修改name字段,此时能修改成功,但是却无法进行查询,这与ES底层实现有关,如果一定要修改要么是新增字段,要么是重建索引。
所以,与其说match是模糊搜索,倒不如说它是分词搜索,因为它会将搜索关键字分词;与其将term称之为模糊搜索,倒不如称之为不分词搜索,因为它不会将搜索关键字分词。
match查询还有很多更为高级的查询方式:match_phrase短语查询,match_phrase_prefix短语匹配查询,multi_match多字段查询等。将在复杂搜索一章中详细介绍。
类似like的模糊搜索
wildcard通配符查询。
POST http://localhost:9200/user/student/_search?pretty
{
"query": {
"wildcard": {
"name": "*kevin*"
}
}
}
ES返回结果包括name="kevin",name="kevin2",name="kevin yu"。
fuzzy更智能的模糊搜索
fuzzy也是一个模糊查询,它看起来更加”智能“。它类似于搜狗输入法中允许语法错误,但仍能搜出你想要的结果。例如,我们查询name等于”kevin“的文档时,不小心输成了”kevon“,它仍然能查询出结构。
POST http://localhost:9200/user/student/_search?pretty
{
"query": {
"fuzzy": {
"name": "kevin"
}
}
}
ES返回结果包括name="kevin",name="kevin yu"。
多条件搜索
上文介绍了单个条件下的简单搜索,并且介绍了相关的精确和模糊搜索(分词与不分词)。这部分将介绍多个条件下的简单搜索。
当搜索需要多个条件时,条件与条件之间的关系有”与“,”或“,“非”,正如非关系型数据库中的”and“,”or“,“not”。
在ES中表示”与“关系的是关键字must,表示”或“关系的是关键字should,还有表示表示”非“的关键字must_not。
must、should、must_not在ES中称为bool查询。当有多个查询条件进行组合查询时,此时需要上述关键字配合上文提到的term,match等。
- 精确查询(
term,搜索关键字不分词)name="kevin"且age="25"的学生。
POST http://localhost:9200/user/student/_search?pretty
{
"query":{
"bool":{
"must":[{
"term":{
"name.keyword":"kevin"
}
},{
"term":{
"age":25
}
}]
}
}
}
返回name="kevin"且age="25"的数据。
- 精确查询(
term,搜索关键字不分词)name="kevin"或age="21"的学生。
POST http://localhost:9200/user/student/_search?pretty
{
"query":{
"bool":{
"should":[{
"term":{
"name.keyword":"kevin"
}
},{
"term":{
"age":21
}
}]
}
}
}
返回name="kevin",age=25和name="kevin yu",age=21的数据
- 精确查询(
term,搜索关键字不分词)name!="kevin"且age="25"的学生。
POST http://localhost:9200/user/student/_search?pretty
{
"query":{
"bool":{
"must":[{
"term":{
"age":25
}
}],
"must_not":[{
"term":{
"name.keyword":"kevin"
}
}]
}
}
}
返回name="kevin2"的数据。
如果查询条件中同时包含must、should、must_not,那么它们三者是"且"的关系
多条件查询中查询逻辑(must、should、must_not)与查询精度(term、match)配合能组合成非常丰富的查询条件。
按等值、范围查询维度
上文中讲到了精确查询、模糊查询,已经"且","或","非"的查询。基本上都是在做等值查询,实际查询中还包括,范围(大于小于)查询(range)、存在查询(exists)、~不存在查询(。missing)
范围查询
范围查询关键字range,它包括大于gt、大于等于gte、小于lt、小于等于lte。
- 查询age>25的学生。
POST http://localhost:9200/user/student/_search?pretty
{
"query":{
"range":{
"age":{
"gt":25
}
}
}
}
返回name="kangkang"的数据。
- 查询age >= 21且age < 26的学生。
POST http://localhost:9200/user/search/_search?pretty
{
"query":{
"range":{
"age":{
"gte":21,
"lt":25
}
}
}
}
查询age >= 21 且 age < 26且name="kevin"的学生
POST http://localhost:9200/user/search/_search?pretty
{
"query":{
"bool":{
"must":[{
"term":{
"name":"kevin"
}
},{
"range":{
"age":{
"gte":21,
"lt":25
}
}
}]
}
}
}
存在查询
存在查询意为查询是否存在某个字段。
查询存在name字段的数据。
POST http://localhost:9200/user/student/_search?pretty
{
"query":{
"exists":{
"field":"name"
}
}
}
不存在查询
不存在查询顾名思义查询不存在某个字段的数据。在以前ES有missing表示查询不存在的字段,后来的版本中由于must not和exists可以组合成missing,故去掉了missing。
查询不存在name字段的数据。
POST http://localhost:9200/user/student/_search?pretty
{
"query":{
"bool":{
"must_not":{
"exists":{
"field":"name"
}
}
}
}
}
分页搜索
谈到ES的分页永远都绕不开深分页的问题。但在本章中暂时避开这个问题,只说明在ES中如何进行分页查询。
ES分页查询包含from和size关键字,from表示起始值,size表示一次查询的数量。
- 查询数据的总数
POST http://localhost:9200/user/student/_search?pretty
返回文档总数。
- 分页(一页包含1条数据)模糊查询(
match,搜索关键字不分词)name="kevin"
POST http://localhost:9200/user/student/_search?pretty
{
"query":{
"match":{
"name":"kevin"
}
},
"from":0,
"size":1
}
结合文档总数即可返回简单的分页查询。
分页查询中往往我们也需要对数据进行排序返回,MySQL中使用order by关键字,ES中使用sort关键字指定排序字段以及降序升序。
- 分页(一页包含1条数据)查询age >= 21且age <=26的学生,按年龄降序排列。
POST http://localhost:9200/user/student/_search?pretty
{
"query":{
"range":{
"age":{
"gte":21,
"lte":26
}
}
},
"from":0,
"size":1,
"sort":{
"age":{
"order":"desc"
}
}
}
ES默认升序排列,如果不指定排序字段的排序),则sort字段可直接写为"sort":"age"。
第六章-Java客户端(上)
ES提供了多种方式使用Java客户端:
- TransportClient,通过Socket方式连接ES集群,传输会对Java进行序列化
- RestClient,通过HTTP方式请求ES集群
目前常用的是TransportClient方式连接ES服务。但ES官方表示,在未来TransportClient会被永久移除,只保留RestClient方式。
同样,Spring Boot官方也提供了操作ES的方式Spring Data ElasticSearch。本章节将首先介绍基于Spring Boot所构建的工程通过Spring Data ElasticSearch操作ES,再介绍同样是基于Spring Boot所构建的工程,但使用ES提供的TransportClient操作ES。
Spring Data ElasticSearch
本节完整代码(配合源码使用更香):https://github.com/yu-linfeng/elasticsearch6.x_tutorial/tree/master/code/spring-data-elasticsearch
使用Spring Data ElasticSearch后,你会发现一切变得如此简单。就连连接ES服务的类都不需要写,只需要配置一条ES服务在哪儿的信息就能开箱即用。
作为简单的API和简单搜索两章节的启下部分,本节示例仍然是基于上一章节的示例。
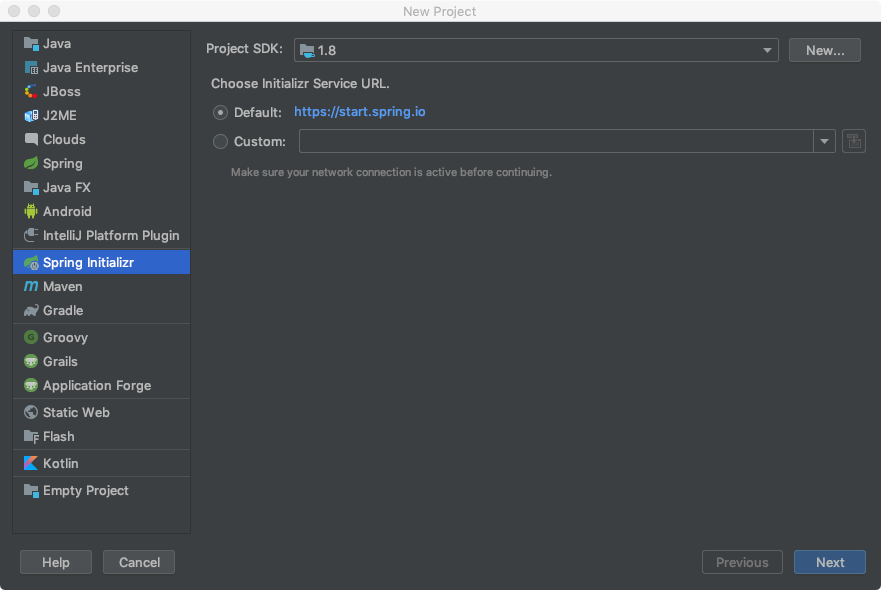
通过IDEA创建Spring Boot工程,并且在创建过程中选择Spring Data ElasticSearch,主要步骤如下图所示:
第一步,创建工程,选择Spring Initializr。
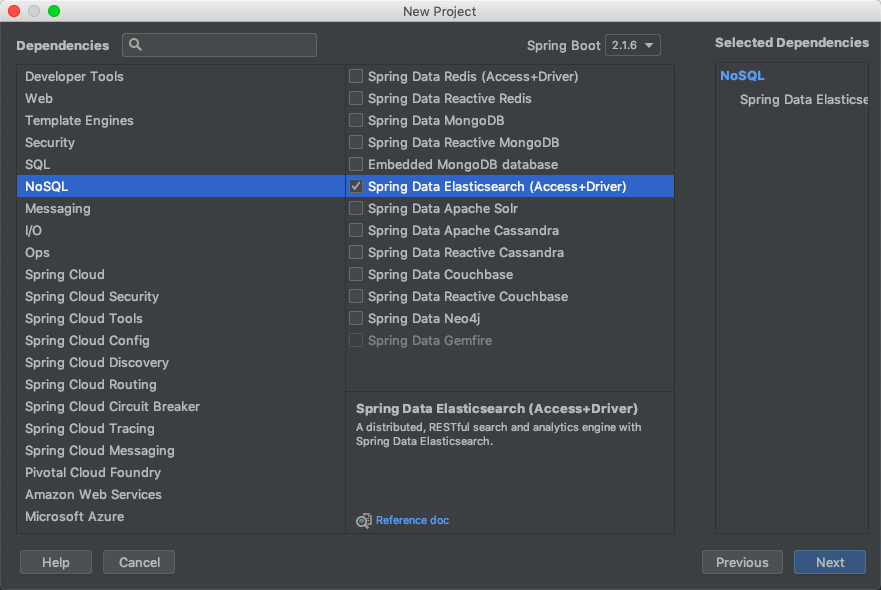
第二步,选择SpringBoot的依赖NoSQL -> Spring Data ElasticSearch。
创建好Spring Data ElasticSearch的Spring Boot工程后,按照ES惯例是定义Index以及Type和Mapping。在Spring Data ElasticSearch中定义Index、Type以及Mapping非常简单。ES文档数据实质上对应的是一个数据结构,也就是在Spring Data ElasticSearch要我们把ES中的文档数据模型与Java对象映射关联。
定义StudentPO对象,对象中定义Index以及Type,Mapping映射我们引入外部json文件(json格式的Mapping就是在简单搜索一章中定义的Mapping数据)。
package com.coderbuff.es.easy.domain;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import org.springframework.data.elasticsearch.annotations.Mapping;
import java.io.Serializable;
/**
* ES mapping映射对应的PO
* Created by OKevin on 2019-06-26 22:52
*/
@Getter
@Setter
@ToString
@Document(indexName = "user", type = "student")
@Mapping(mappingPath = "student_mapping.json")
public class StudentPO implements Serializable {
private String id;
/**
* 姓名
*/
private String name;
/**
* 年龄
*/
private Integer age;
}
Spring Data ElasticSearch为我们屏蔽了操作ES太多的细节,以至于真的就是开箱即用,它操作ES主要是通过ElasticsearchRepository接口,我们在定义自己具体业务时,只需要继承它,扩展自己的方法。
package com.coderbuff.es.easy.dao;
import com.coderbuff.es.easy.domain.StudentPO;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
/**
* Created by OKevin on 2019-06-26 23:45
*/
@Repository
public interface StudentRepository extends ElasticsearchRepository<StudentPO, String> {
}
ElasticsearchTemplate可以说是Spring Data ElasticSearch最为重要的一个类,它对ES的Java API进行了封装,创建索引等都离不开它。在Spring中要使用它,必然是要先注入,也就是实例化一个bean。而Spring Data ElasticSearch早为我们做好了一切,只需要在application.properties中定义spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300,就可大功告成(网上有人的教程还在使用applicationContext.xml定义一个bean,事实证明,受到了Spring多年的“毒害”,Spring Boot远比我们想象的智能)。
单元测试创建Index、Type以及定义Mapping。
package com.coderbuff.es;
import com.coderbuff.es.easy.domain.StudentPO;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringDataElasticsearchApplicationTests {
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
/**
* 测试创建Index,type和Mapping定义
*/
@Test
public void createIndex() {
elasticsearchTemplate.createIndex(StudentPO.class);
elasticsearchTemplate.putMapping(StudentPO.class);
}
}
使用GET http://localhost:9200/user请求命令,可看到通过Spring Data ElasticSearch创建的索引。
索引创建完成后,接下来就是定义操作student文档数据的接口。在StudentService接口的实现中,通过组合StudentRepository类对ES进行操作。StudentRepository类继承了ElasticsearchRepository接口,这个接口的实现已经为我们提供了基本的数据操作,保存、修改、删除只是一句代码的事。就算查询、分页也为我们提供好了builder类。"最难"的实际上不是实现这些方法,而是如何构造查询参数SearchQuery。创建SearchQuery实例,有两种方式:
- 构建
NativeSearchQueryBuilder类,通过链式调用构造查询参数。 - 构建
NativeSearchQuery类,通过构造方法传入查询参数。
这里以"不分页range范围和term查询age>=21且age<26且name=kevin"为例。
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.boolQuery()
.must(QueryBuilders.rangeQuery("age").gte(21).lt(26))
.must(QueryBuilders.termQuery("name", "kevin"))).build();
搜索条件的构造一定要对ES的查询结构有比较清晰的认识,如果是在了解了简单的API和简单搜索两章的前提下,学习如何构造多加练习一定能掌握。这里就不一一验证前面章节的示例,一定要配合代码使用练习(https://github.com/yu-linfeng/elasticsearch6.x_tutorial/tree/master/code/spring-data-elasticsearch)
TransportClient
ES的Java API非常广泛,一种操作可能会有好几种写法。Spring Data ElasticSearch实际上是对ES Java API的再次封装,从使用上将更加简单。
本节请直接对照代码学习使用,如果要讲解ES的Java API那将是一个十分庞大的工作,https://github.com/yu-linfeng/elasticsearch6.x_tutorial/tree/master/code/transportclient-elasticsearch
关注公众号:CoderBuff,回复“es”获取《ElasticSearch6.x实战教程》完整版PDF。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号