
L4 可靠性
L4 可靠性
事故 vs 事件
定义
航空器事故(accident)指:
- 和航空器运行相关的事件;
- 时间:任何人(一定有人)以飞行为目的登机,到所有此类人员下机,即地勤是不算的。
- 标准:事故中有人死亡或重伤,或航空器遭受重大损坏。
航空器事件(incident)指:
- 和航空器运行相关;
- 标准:已经影响或可能影响运行安全,但没有严重到事故级别的情况。
而对于无人机,定义适用的时间段为:系统以飞行为目的启动时起(如果只是地面试车之类的不算),到任务结束后系统关闭为止。
案例分析
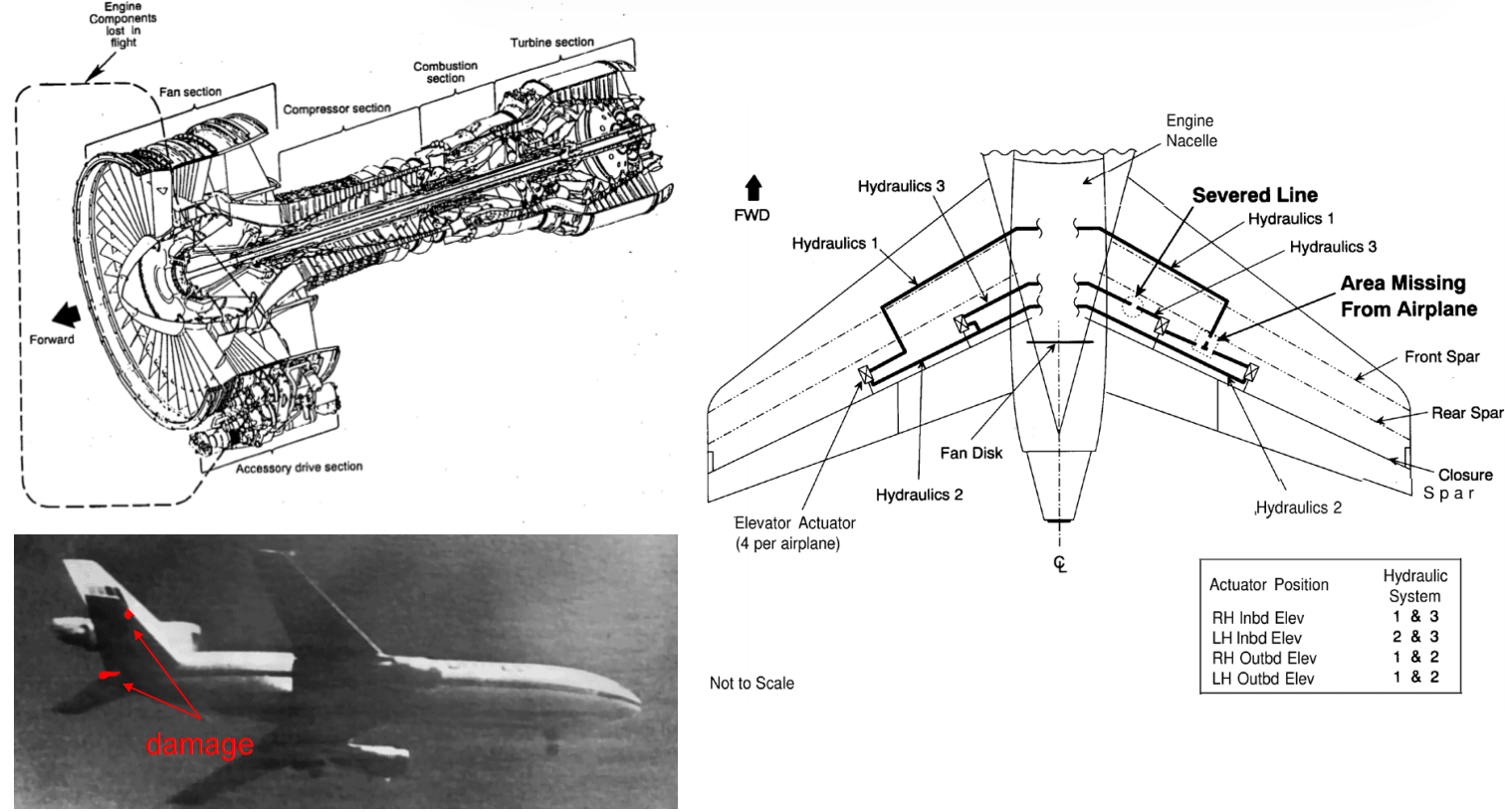
以美联航232航班事故为例。
失效顺序(或故障序列,英文failure sequence):
- 发动机初始故障:尾部发动机风扇盘上,存在由制造缺陷导致的疲劳裂纹,该裂纹导致发动机解体。
- 失去液压:该解体事故切断了所有用于控制舵面的液压管线,它们在飞机尾部汇集在相邻位置。
- 飞机控制受限:没有控制面,只能通过差动发动机推力(differential engine thrust),控制飞机俯仰、横滚、偏航。
- 对飞行稳定性的影响:受限的控制严重影响飞行稳定性和飞行性能,使得难以维持飞机控制。
- 迫降事故:飞机硬着陆坠毁,造成重大损伤和人员伤亡。
经验教训:对关键系统进行冗余设计,并加强机组人员处理紧急状况的培训。
It highlighted the importance of redundancy in critical systems, and the need for better crew training to handle emergencies.
事故文档
如何撰写一份关于事故中故障模式和影响的文档?
-
撰写关于完整的事故/事件的报告(elaborate a report of the complete incident/accident),并对整个系统进行描述。
- 对整个事件的来龙去脉,包括背景、过程、后果以及相关的各种因素进行全面、深入、详尽的描述和分析;
- 把飞行器事故放在更广阔的系统背景下,包括人员(如飞行员的生理和心理状态)、硬件(如飞机本身、地面支持设备)、软件(如飞控程序、飞行手册)、环境(如天气、地形、光照)、信息(如飞行计划、气象预报、航行通告)。
-
在分析事故时,要严格基于已查证的事实,避免争论、草率归因或沉迷于未经证实的假设。
- 草率归因:例如,如果某飞机在坠毁之前突然大角度俯冲,调查人员立刻认为“一定是飞行员故意操作飞机俯冲”,这就陷入了草率归因的误区,因为只有当证据链完整(例如考虑机械故障、传感器错误、飞行员失去意识等所有因素)之后,才能提出因果关系。
- 争论:例如A认为一定是发动机故障,B认为是飞行员操作失误,大家在争吵当中浪费时间。
正确做法是,在收集并整理呈现出所有相关事实之前,避免就哪个原因更可能进行辩论。 - 未经证实的假设:C怀疑是风切变导致飞机失事,于是花费大量时间寻找相关证据,即使获取的数据不支持该观点,仍然坚持意见,导致忽略了其他线索。
正确做法是,如果事实、数据不支持当前假设,立即转换方向,考虑其他可能性并收集证据。 - 解释已记录的事实:事故分析应建立在已经记录、经过验证、有据可查的事实上。
例如,D从目击者处得知“看到飞机冒烟”,于是在报告中写“发动机起火导致飞机失控”,这是错误的,因为这是一个未经证实的推断。
正确做法是,记录“目击者看到飞机尾部冒出烟雾”这个事实,不能主观臆断其原因或后果,而是结合其他调查结果进行分析。
-
识别并记录故障序列,可能涉及多重故障、多重因果序列;
并为故障序列及其影响添加可视化呈现,如飞机故障部位示意图,加以文字描述故障点及其后果。
![image]()
可靠性与风险建模
流程
接下来,以一个家用电水壶的可靠性分析为例子进行说明。
-
系统定义:明确界定需要建模的系统或流程。这可能是一个产品、一套软件系统、一整个制造和运输的流程。注意,被排除在系统外的部分同样重要。
- 电水壶包含什么:水壶本体、加热管、温控器、开关、电源线、指示灯。
- 不包含什么,或系统边界在哪里:用户操作是否规范?电网电压是否稳定?电源插座是否有故障?系统以外的部分可能作为外部因素,和系统产生互动。
- 系统边界的定义直接影响后续的分析,太窄的边界会忽略外部因素或相关组件故障对核心系统影响,太宽的边界使得分析过于复杂。
-
故障模式识别:识别系统中可能发生的,所有潜在的故障模式,包括硬件故障、软件故障、人为错误,以及其他可能影响系统的外部因素。
- 电水壶可能的故障:硬件故障,如加热管损坏导致无法加热,温控器失灵导致水开了还不跳闸;
人为错误,例如忘记加水就通电,导致加热管损坏;
外部因素,例如插座坏了导致无法加热。
- 电水壶可能的故障:硬件故障,如加热管损坏导致无法加热,温控器失灵导致水开了还不跳闸;
-
数据收集:获取关于系统内各个独立组件可靠性和数据,如历史记录、制造商规格说明(manufacturer specifications),行业标准,或测试和模拟。
- 例如,参考供应商提供的加热管平均寿命数据;电水壶制造商的相同型号售后维修记录,查找温控器和开关的年均故障次数;行业内关于电源线弯折寿命的标准;对开关进行一万次按压测试,以了解其寿命。
-
选择建模方法:根据系统复杂度和可用数据情况,选取合适的建模技术。在后文将讲到。
-
模型构建:基于所选方法,建立可靠性与风险的模型,可能设计绘制图表、定义故障模式和概率、使用专业软件开发仿真模型。
-
模型验证和确认(model validation and verification):验证(validate)模型,通过将模型的预测结果,和实际数据/已知结果进行比对;确认(verify)模型准确性,通过审查假设、输入数据和建模技术。
- 验证:我们构建的模型是否正确反映了真实系统?比如我们的模型预测,电水壶的整体一年故障率是5%,如果实际返修率是20%,就表明我们的模型不准确 ,比如简化掉了某个关键变量。
- 校验/确认正确性:我们是否正确构建了模型?比如公式是不是对的、单位是否正确、假设是否成立。
例如,若初始假设各个组件的故障是独立的,但开关故障会导致温控器过载,那么该假设不成立。
-
分析:对于通过验证后的模型,用它进行可靠性和风险分析,目的是评估系统性能、识别关键故障模式、评估潜在风险。涉及计算平均故障间隔时间(mean time between failures, MTBF)、故障率(failure rate, $\lambda$)、失效概率(probability of failure, PoF)等。
-
风险缓解措施(mitigation of risks):根据分析结果,制定并实施风险缓解策略,以降低关键故障模式的发生概率和影响。可能包括设计改进、添加冗余配置、改进维护程序和应急预案。
- 例如,对于电水壶的加热管,换用更耐用、抗水垢能力更强的材料和设计,并在说明书中指导用户定期除水垢;增加干烧检测和自动断电保护功能。
-
监测与更新(monitoring and updating):持续地监控系统性能,并在获得新数据/系统发生变更时,更新可靠和风险模型,确保模型始终保持准确性和相关性。
- 例如,如果实际故障率高于模型预测,应当回头检查模型(验证 validate 和校验 verify);如果换用了新设计的加热管,应当为这个加热管收集可靠性数据,并更新电热水壶系统的可靠性模型。
模型
-
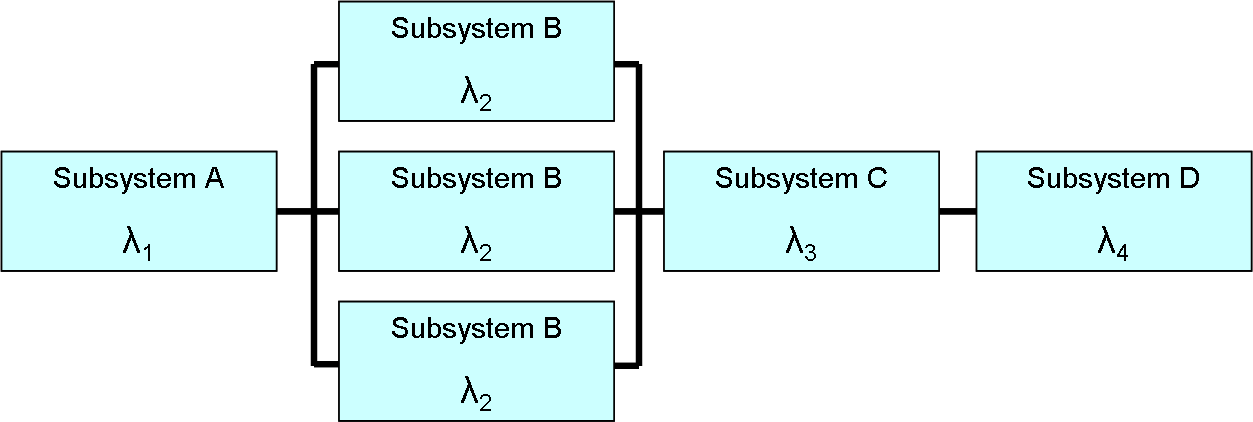
可靠性框图(reliability block diagrams, RBD):把系统表示为一系列相互连接的模块,每个模块代表一个组件或子系统,用于分析系统可靠性。
这种方式的好处是,便于整合到严格的物理模型中。
![image]()
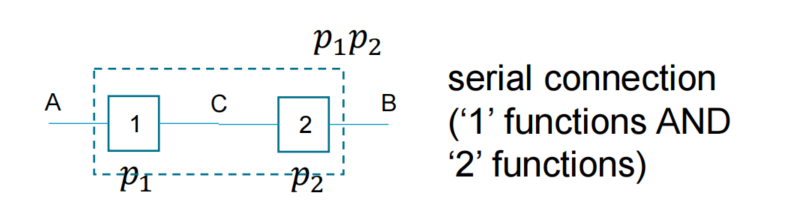
如图,A,B,C,D系统是串联路径,串联路径中的任何故障都会导致整个路径失效;
B系统由三个并联组件构成,一组并联框可能需要三个中的一个或两个成功,系统才能成功。
再比如,还是热水壶的例子:
![image]()
对于串联系统,总的系统可靠性 (R_sys) 是所有组件可靠性 (R_i) 的乘积;
对于两个并联组件A和B,其组成的子系统可靠性 (R_parallel_subsystem) 计算公式为:
R_parallel_subsystem = 1 - (1 - R_heaterA) * (1 - R_heaterB)。 -
故障树分析(fault tree analysis):一种自上而下的方法,最顶端是我们不希望出现的事情,底层是不希望出现的状态。
符号体系:(参见https://zh.wikipedia.org/zh-cn/故障樹分析)
![image]()
![image]()
![image]()
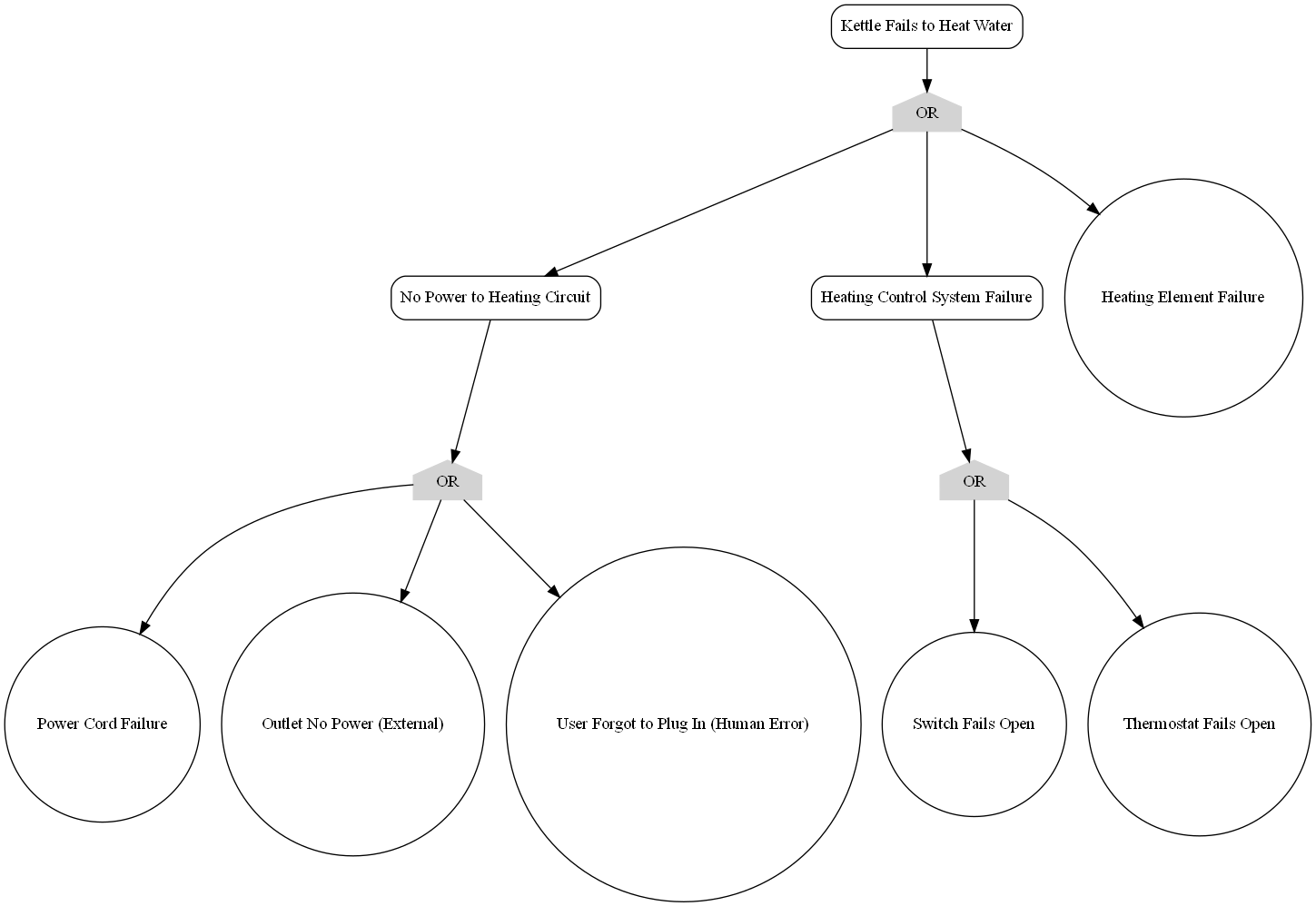
接下来以电热水壶不能加热水为故障案例,做一个极为抽象的故障树:
![electric_kettle_fta]()
-
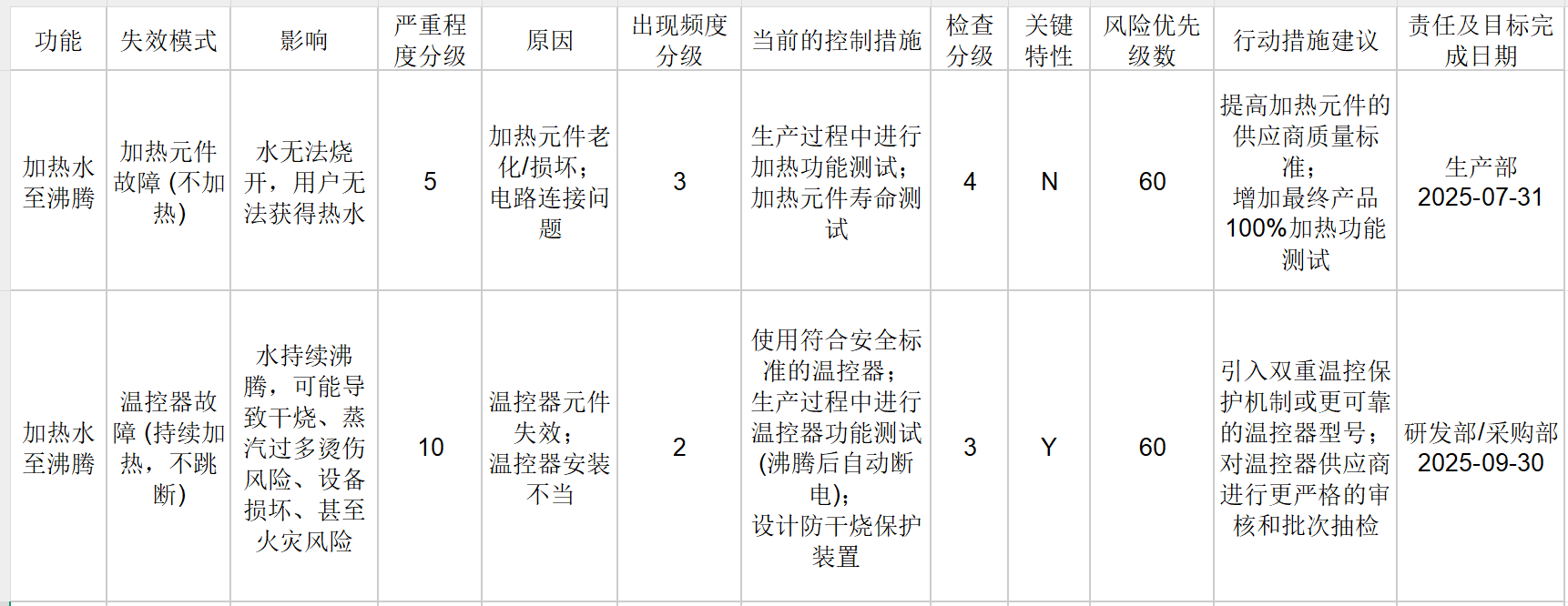
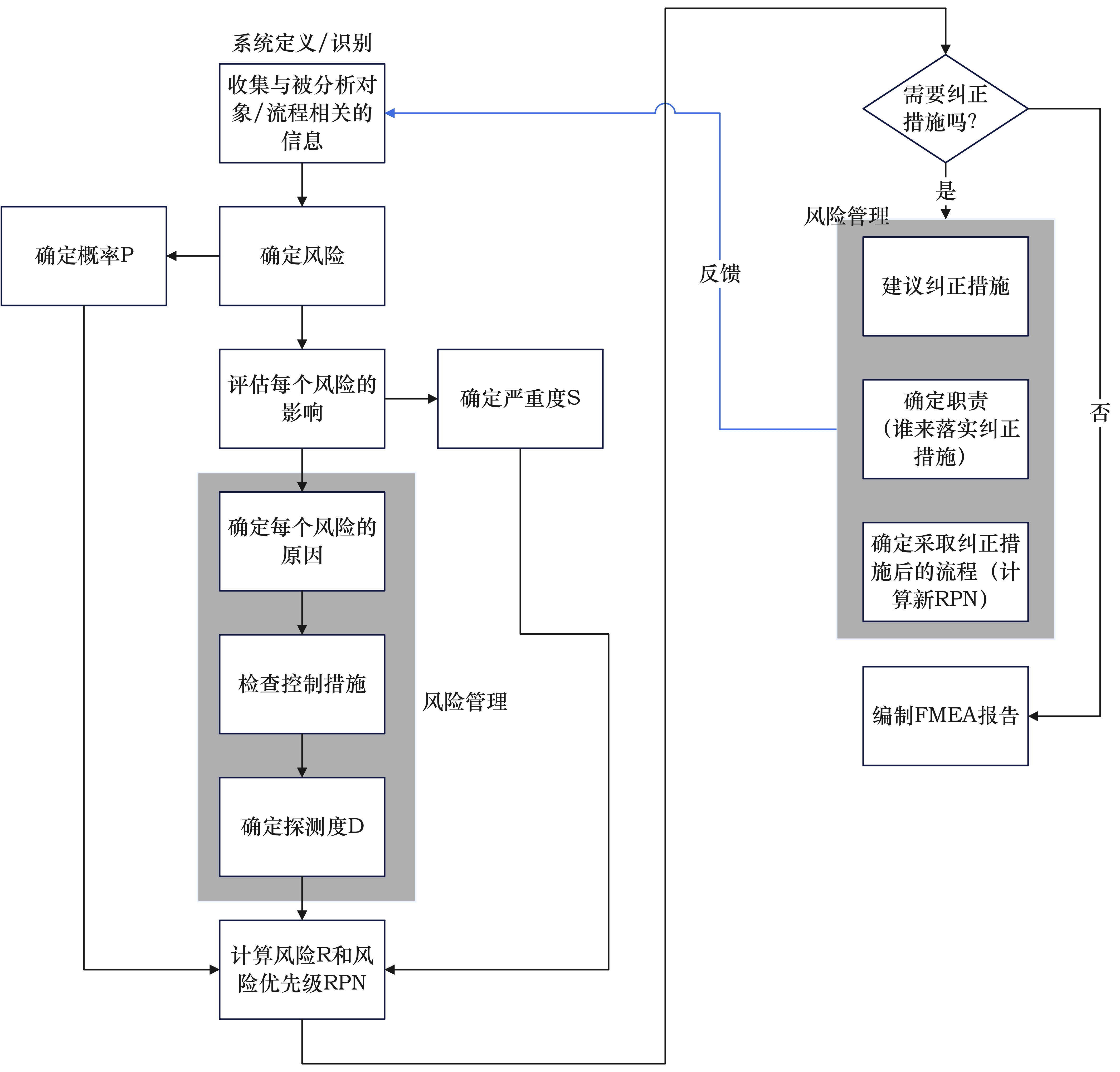
失效模式与影响分析(failure modes and effects analysis,FMEA):
![image]()
创建FMEA表格通常分成3步,参考上述表格从左到右顺序:-
严重程度:首先根据功能需求及其影响,确定所有的失效模式,然后考虑这些模式的影响,接着赋予一个从1(没有危险)到10(危重)之间的严重程度值S,其中9、10一般用于会伤害用户或引发诉讼的影响。
-
出现频率:考虑失效原因、出现频次。失效原因应是设计缺陷。
可以为每种失效模式赋予一个1~10的概率值O。 -
检查:确定适当的行动措施,然后选择可以或已经用户类似系统的测试分析方法,测试这些措施的效能,组合构成一个发现指数D:预定的测试或检查工作,在消除缺陷或发现失效模式方面的能力。
-
风险优先级数:RPN最高的失效模式应当获得最高的优先级别。首先应当处理的可能是那些严重程度相对较低,但更常发生且不太易于发现的失效问题.
$$\begin{equation} RPN=S\times O\times D \end{equation}$$
值得注意的是,FMEA存在一些局限性,如:
- 受到负责调查产品失效问题的人关于既往问题的经验制约,或需要了解不同产品失效问题的顾问提供协助;它需要依托文档记录;
- 它不太擅长系统地识别由多个独立或相互关联的故障同时或接连发生,从而导致的全新或更严重的“组合式”失效模式。
如复杂的失效模式C:温控器失效导致持续加热(失效A发生),并且 同时/紧接着防干烧保护装置也失效未能启动(失效B也发生); - 也无法报告特定失效模式适于上级系统的预期失效间隔(“某个特定部件的某个失效模式,预计会导致整个系统(上级系统)多少年/多少次操作后失效”)。
如由于温控器不跳断特定失效模式,整个电热水壶的“预期失效间隔”(例如,因温控器持续加热问题导致电热水壶报废或需要维修的平均时间)是多少年。
他PPT上展示的框图,实际上就是FMEA的流程。这里放出中文版,请结合前面的表格顺序理解:
![绘图1]()
此外,下面的链接展示了基于电热水壶的FMEA流程解析,供参考:https://docs.google.com/document/d/1eUDZgJspQXxHdzM4mmG9Iec5GgAvi5hTDHZq1iuuZIU/edit?usp=sharing -
-
蒙特卡罗方法(Monte Carlo simulation):一种基于重复随机抽样获得数值结果的计算技术。当问题难以通过解析方法求解时(例如飞机这一整个系统的平均无故障工作时间,分析整个系统过于复杂),可以通过大量随机试验,模拟问题的过程,然后对试验结果进行分析,得到问题的近似解。
其具体流程为:-
定义可能的输入域:识别系统中所有可能影响其可靠性的独立部件,并确定描述这些部件故障行为的参数。
$$\begin{equation} \begin{aligned} \lambda&=\frac{1}{\mathrm{MTBF}}\\ \bar{p}(t)&=e^{-\lambda t} \end{aligned} \end{equation}$$
在这里,取电热水壶的三个关键部件:加热元件、温控开关、电源开关,它们构成了一个串联系统,即三个系统都正常工作,水壶才能正常烧水。
输入通常是各个部件的寿命或故障率,而域(domain)指这些参数的可能取值范围及它们的概率分布。
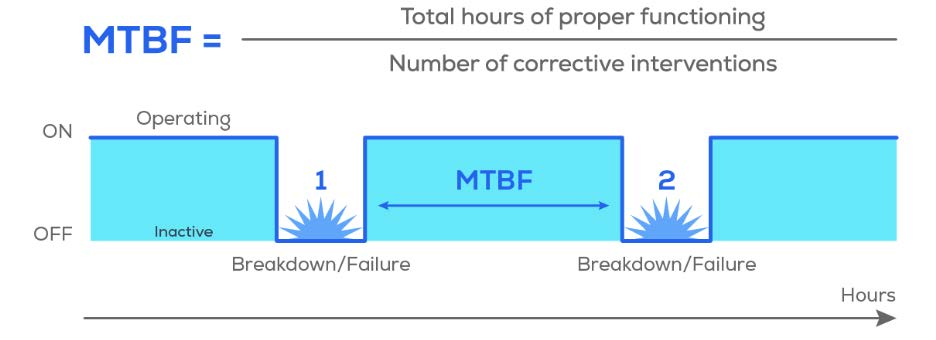
假设上述部件的平均无故障工作时间MTBF分别为2000、5000、10000小时,且它们的寿命服从如下分布:其中,$\lambda$表示整个工作时间内的故障频次,$\bar{p}(t)$表示单个部件在时间t之前的故障发生概率,这里认为它服从指数分布。
![image]()
这张图是对MTBF的解释,即两次故障1和2发生之间的间隔时间。 -
从域上的概率分布中,随机生成输入:为每个部件的每个模拟试验,随机生成具体的输入值,如加热元件的MTBF是2000小时,那么在单次模拟中,该部件可能在2000小时或2200小时工作后失效。
$$\begin{equation} TTF=-MTBF\cdot ln(U) \end{equation}$$
这些值使用随机数生成算法,结合概率分布进行。
例如:为加热元件生成一个随机寿命$TTF_{H_i}$,使用公式:这里U是(0,1)之间的均匀分布随机数,当然也可以用正态分布或其他方法。
-
对输入执行确定性计算(deterministic computation):为单次模拟生成了所有部件的随机输入之后,根据系统结构逻辑(比如之前讨论的可靠性框图或故障树),计算整个系统的寿命。
$$\begin{equation}1-p_1=\bar{p_1}\end{equation}$$$$\begin{equation} p_{total}=p1*p2*p3 \end{equation}$$
在给定时间t内保持功能正常的概率定义为p,对于电热水壶这个串联系统的计算如下:
![image]()
如果是并联系统,比如p1和p2并联,那么计算公式为:
$$\begin{equation}p= 1-(1-p_1)(1-p_2) \end{equation}$$ -
汇总结果(aggregate the result):重复步骤2和3,然后对所有结果进行统计,关注:
- 系统可靠度R(t),在t时间系统仍然工作的次数÷总模拟次数;
- 系统MTBF;
- 寿命分布直方图,结果的置信区间等。
-




风险
风险的定义:不良事件发生的概率p,乘以该事件的后果或影响C,即R=pC。
其中,事件概率即事件发生的可能性,定义于[0, 1]区间;
事件后果(consequences of event)指不良事件发生后,造成的严重性或影响,可以用经济损失、损害或伤害(damage, injury)等指标量化。
应用可靠性、取证分析、测试、状态监测与维护
取证分析
在航空事故的法医调查规程(forensic invetigation protocol)中,采取了一种全面、系统的方式,来收集证据、分析证据、确定事故原因和促成因素。
一共分为11步,不过我感觉应该...不会考吧?考起来也没意思。所以就列在这里吧,当故事看看得了。
同样,本章的补充文档里面有一个案例,也可以没事的时候看看《空中浩劫》了解空难调查:https://docs.google.com/document/d/1eUDZgJspQXxHdzM4mmG9Iec5GgAvi5hTDHZq1iuuZIU/edit?usp=sharing
- 通知与启动(notification and activation):收到飞机事故通知后,启动调查组,包括来自相关机构的调查员(如美国的NTSB或他国的同等机构)。建立指定的调查指挥中心,并封锁事故现场以保护证据。
- 文件记录和初步评估(documentation and initial assessment):通过摄影、摄像和草图记录事故现场,捕捉残骸分布、撞击痕迹和周围环境。对事故现场进行初步评估,注意任何危险或安全隐患。如果可用,获取驾驶舱语音记录器 (CVR) 和飞行数据记录器 (FDR),并为这些关键证据建立监管链。
- 证人访谈(witness interviews):访谈目击者、空中交通管制员和参与空中交通服务的人员,以收集关于事故序列和相关信息的第一手资料。
- 残骸回收和检查(Wreckage recovery and examination):系统地记录和回收残骸碎片,注意任何显示损坏或故障迹象的部件。将残骸运至指定设施,由法医专家进行详细检查和分析。
- 数据分析:分析CVR和FDR的数据,以重建飞行剖面,包括高度、空速、发动机参数、控制输入和通信。使用飞行模拟软件和其他分析工具对事故情景进行建模并验证调查结果。
- 结构和机械检查:对飞机结构、系统和部件进行详细检查,以识别损坏、故障或功能异常的迹象。进行冶金分析、无损检测和其他法医技术,以确定结构故障或部件故障的根本原因。
- 人为因素调查(human factors investigation):调查人为表现因素,包括机组行为、决策过程、培训、疲劳和工作负荷。考虑在事故序列中可能影响机组行为或表现的生理和心理因素。
- 环境因素评估:评估环境条件,如天气、地形、能见度以及可能导致事故的其他外部因素。
- 分析和报告生成:将所有证据、调查结果和分析汇编成一份全面的事故调查报告。清晰阐述导致事故的事件顺序,确定促成因素,并提出安全建议以防止未来发生。
- 审查和发布:与相关利益方(包括监管机构、飞机制造商、运营商和行业组织)在内部和外部审查调查报告。发布调查结果和安全建议,以促进安全改进并防止未来发生类似事故。
- 后续跟踪和实施(follow-up and implementation):监控安全建议的实施情况,并跟踪利益相关方在纠正措施方面的进展。必要时进行后续调查,以解决事故调查中未解决的问题或出现的新的安全隐患。
测试
测试本质上是在实验室或相关环境(包括实际飞行任务)中,在受控、可重复和受监控的条件下,对运行模式和故障模式进行预期和复现。从这个意义上说,它与法医学有许多共同之处。
设计考虑
说实话这个考的概率嘛...倒是可以和前面的联合起来看,但是原课件的ppt只有一页。
所以可能是拿某个视频作为例子,然后进行故障分析啊,可靠性分析啊,之类的。
所以这里就列举部分信息作为参考,复习的时候,没时间的话,浏览一遍,有个印象就行。
以航空安全为例子,它是由一个庞大且相互关联的系统共同决定的。
-
核心要素:飞机,包含所有子系统、乘员、有效载荷。
-
飞机子系统:机翼、发动机、驾驶舱、机身、垂直安定面、水平安定面、襟翼和缝翼、副翼、扰流板、起落架、液压系统、电气系统、燃油系统、飞控系统。
- 机翼:确保足够的升力;具有坚固的、能承受湍流、机动飞行等各种飞行载荷的结构。
选择抗疲劳、抗腐蚀的材料,进行结冰防护,优化结构设计等。 - 发动机:防火、内部损坏的碎片包容性、冗余控制系统等。
- 机翼:确保足够的升力;具有坚固的、能承受湍流、机动飞行等各种飞行载荷的结构。
-
机组:飞机设计应支持机组的态势感知、决策和操作;
自动化系统的设计应与机组协同工作,而不是取代或迷惑他们;
培训大纲和模拟机的设计也是系统安全的一部分。 -
有效载荷:考虑装载和固定货物,在运输危险品时进行特殊工作,设计确保乘客安全的座椅和安全带。
-
-
围绕核心的其他系统要素:
- Society, operational-professional-management context and expectations (社会、运营-专业-管理背景和期望):社会对航空安全有极高期望(零容忍)。法规(由社会期望驱动)设定了最低安全标准。运营压力(成本、准点率)可能与安全投入产生矛盾。管理层的安全文化和决策直接影响资源分配。
设计必须满足甚至超越法规要求。需要进行成本效益分析,但安全不能是可妥协的选项。设计理念应融入“安全第一”的文化。 - Operational (flight) environment – air and ground (运行(飞行)环境——空中和地面):
天气(雷暴、结冰、风切变、火山灰)、地形、鸟击、电磁干扰等都会对飞行安全构成威胁。
飞机必须设计成能在预期的各种环境条件下安全运行。例如,气象雷达、除冰/防冰系统、增强型近地警告系统 (EGPWS)、发动机和机体结构的抗鸟撞设计。 - Inspection, maintenance and supporting operations (检查、维护和支持性运营);
- Aircraft operations and mission planning (飞机运营和任务规划);
- Airport, monitoring systems, ground response systems (机场、监控系统、地面响应系统)。
- Society, operational-professional-management context and expectations (社会、运营-专业-管理背景和期望):社会对航空安全有极高期望(零容忍)。法规(由社会期望驱动)设定了最低安全标准。运营压力(成本、准点率)可能与安全投入产生矛盾。管理层的安全文化和决策直接影响资源分配。
-
总结:
- 整体性 (Holistic Approach): 不能孤立地看待飞机本身的设计。必须将其置于整个航空运输系统中进行考虑。一个在实验室里看起来很安全的设计,如果难以在现实操作中正确使用、维护或与外部系统交互,那么它仍然是不安全的。
- 接口管理 (Interface Management): 飞机与飞行员、飞机与维护人员、飞机与空管、飞机与机场之间的接口设计至关重要。误解或不匹配是常见的事故源头。
- 冗余与容错 (Redundancy and Fault Tolerance): 不仅在飞机子系统内部需要冗余,整个大系统也需要多层防御(“瑞士奶酪模型”)。例如,即使飞机某个部件失效,熟练的机组、良好的空管支持和应急程序也可能防止灾难。
- 人为因素 (Human Factors Engineering): 在所有环节的设计中(飞机驾驶舱、维护手册、空管界面、操作程序)都必须深入考虑人的能力、局限性和行为模式。目标是设计出能最大限度减少人为差错,并在差错发生时能被系统捕获或减轻其后果的系统。
- 安全文化 (Safety Culture): 虽然不是直接的“设计”要素,但一个积极的安全文化(从制造商到运营商到监管机构)是确保所有设计安全措施得到正确实施和持续改进的基础。设计过程本身也应包含严格的安全评估和风险分析。
- 持续改进 (Continuous Improvement): 事故调查和日常运行数据是改进设计的重要输入。安全设计是一个不断学习和演进的过程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号