当当网图书信息获取
虽然现在是信息时代,大多数人都会选择电子读物,但是纸质图书仍是我们大多数学生不可或缺的.
准备工作:
查看网站允许抓取权限:进行网页抓取时必须遵守网站的robots.txt规则.频繁地请求会给网站服务器带来负担,导致违反服务条款导致IP封禁
https://www.dangdang.com/robots.txt查看哪些页面不允许获取
分析目标页面
- 确定要获取的信息(书籍名称、出版社、价格、评价数量等)
- 使用浏览器开发者工具查看这些信息在
HTML中如何表示 - 查看分页机制,了解如何构建
URL实现分页
分页链接
#首页
https://search.dangdang.com/?key=Java&act=input
key=Java表示该链接是接收关键字搜索后的链接
#第二页
https://search.dangdang.com/?key=Java&act=input&page_index=2
#第三页
https://search.dangdang.com/?key=Java&act=input&page_index=3
通过观察发现.除了首页链接意外,后续链接page_index=页码,这就很方便构建链接了.对于首页链接我们可以尝试输入1也是能够生成的,当然也可以在循环时候判断,如果i=1那么链接为https://search.dangdang.com/?key=Java&act=input
正式分析
通过浏览器开发工具我们可以快速定位到所需的信息都存在于<ul class='bigimg' id='component_59'>下的li标签中.所以我们只需要获取到页面的源码之后通过定位语句获取到所有的li标签即可,之后对其进行循环遍历分别提取出所需的信息清洗,最后写入保存
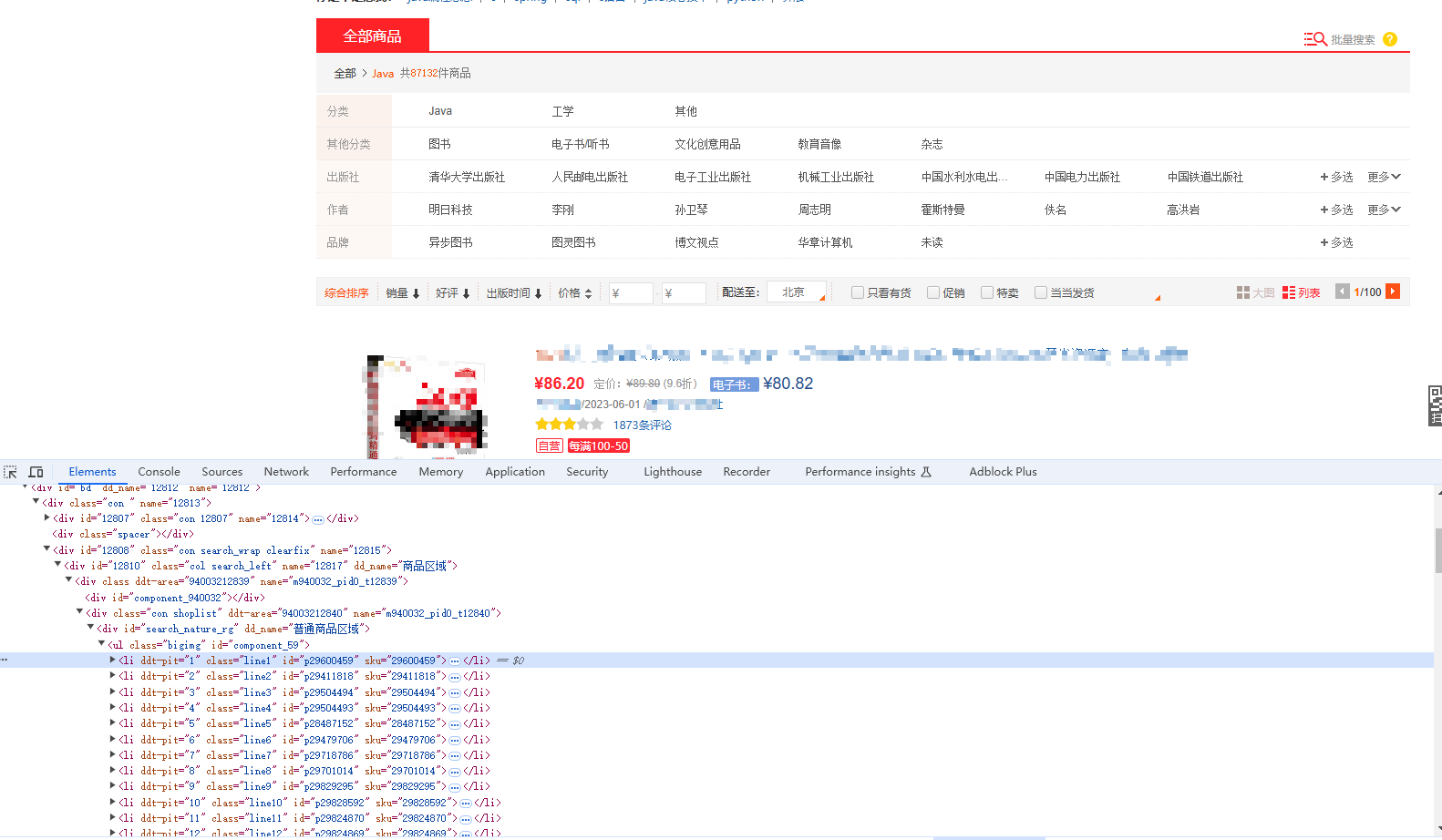
首先是书名,点击开发者工具会发现书名的结构如下图所示:li -> p -> a标签中的title文本即是所需的书名

其次是价格,同样的操作会发现其结构li -> p.price -> span中即是价格

紧接着是出版社,其结构li -> p.search_book_author -> span[3] -> a中
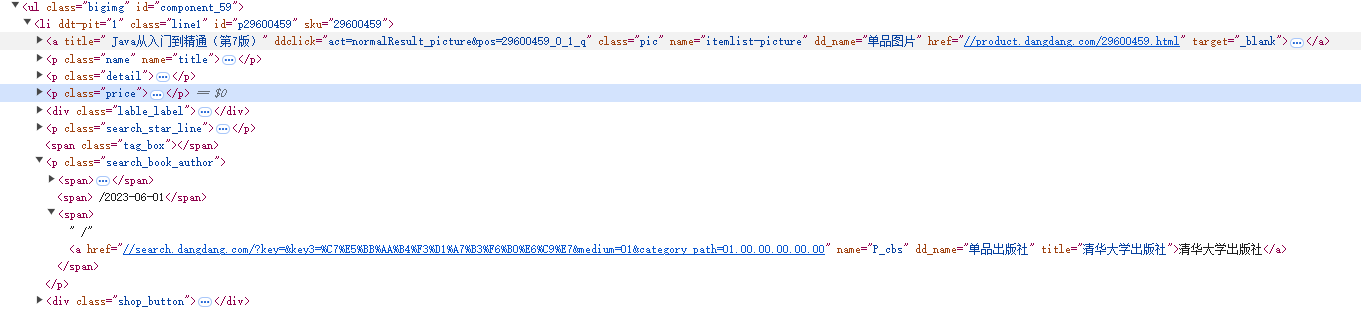
最后是评价数,结构li -> p.search_star_line -> span -> a中

保存数据
将获取数据添加到列表中使用pandas统一进行格式化写入
完整代码
import pandas as pd
import parsel, requests, time
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
book_info = []
B_title = ['书名', '售价', '出版社', '评论']
def get_book_info():
sel = parsel.Selector(get_html(url))
ul_list = sel.css('ul.bigimg > li')
for ul in ul_list:
book_title = ul.css('p.name > a::attr(title)').get()
book_price = ul.css('p.price > span::text').get()
book_publish = ul.css('p.search_book_author span:nth-of-type(3) > a::text').get() # css选择器独特写法,意思是选择第三个span标签
book_review = ul.css('p.search_star_line > a::text').get()
book_info.append([
book_title,
book_price,
book_publish,
book_review
])
for i in range(1, 10):
print('正在爬取第%s页' % i)
url = f"https://search.dangdang.com/?key=python&act=input&page_index={i}"
get_html(url)
get_book_info()
time.sleep(1)
book_info = pd.DataFrame(columns=B_title, data=book_info)
book_info.to_excel('book_info.xlsx', index=False)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号