MySQL的主从架构
一、MySQL的主从架构
1、主从架构有什么用?
通过搭建MySQL主从集群,可以缓解MySQL的数据存储以及访问的压力。
(1)数据安全
(2)读写分离
(3)故障转移--高可用
在一般项目中,如果数据库的访问压力没有那么大,那读写分离不一定是必须要做的,但是,主从架构和高可用架构则是必须要搭建的。
2、搭建主从集群(Bin log 方式)
- 双方MySQL必须版本一致。(至少需要主服务的版本低于从服务)
-
两节点间的时间需要同步。
双主的搭建:Master1的Binlog 配置给 Master2,Master2 的 Bin log 也配置给 Master1。
环状的多主搭建;
2.1、master配置
(1)开启 binlog,以及指定severId(每个机器的Server不能重复)。
[mysqld] # 表示是本机的序号为1,一般来讲就是master的意思 server-id=1 # 开启binlog,并指定文件名 log_bin=master-bin # binlog文件的索引文件 log_bin-index=master-bin.index
(2)创建复制账号并且授权:创建账号;授权;刷新权限;
# 创建用户名(syncUser)/密码(sync@123) CREATE USER 'syncUser'@'%' IDENTIFIED BY 'syncU@123'; # 给 syncUser 授予 REPLICATION SLAVE 权限 grant replication slave,replication client on *.* to syncUser@'%' identified by 'syncU@123'; # 刷新权限 FLUSH PRIVILEGES;
(3)查看配置的变量,执行 show variables like '%log_bin%'

(4)在 Master 的数据库执行 show master status,查看主服务器二进制日志状态及位置号:

说明: File:当前写入的binlog的文件名;Position:当前写入的位置号;
2.2、slave配置
(1)打开中继日志( relay log);
[mysqld] # 主库和从库需要不一致 server-id=2 # 打开MySQL中继日志 relay-log=slave-relay-bin relay-log-index=slave-relay-bin.index # 使得更新的数据写进二进制日志中 log-slave-updates=1 # 设置为只读 read_only=1
(2)设置同步的数据库;
默认情况下,master 的所有数据库及其下表的增、删、改都会被同步到 Slave;有些情况我们只想同步部分数据的部分表数据,这个怎么做呢?
(3)启动 slave 的同步 master 的线程;
# 设置同步主节点: CHANGE MASTER TO MASTER_HOST='192.168.172.20', MASTER_PORT=3306, MASTER_USER='syncUser', MASTER_PASSWORD='syncU@123', MASTER_LOG_FILE='master-bin.000002', MASTER_LOG_POS=1302
;
(4)开启 Slave
start slave;
(5)可使用SHOW SLAVE STATUS\G; 命令查看从服务器状态:
Slave_IO_Running: Yes //IO线程正常运行 Slave_SQL_Running: Yes //SQL线程正常运行

2.3 设置同步的数据库
(1)在 Master 端:在 my.cnf 文件,可以通过以下这些属性指定需要针对哪些库或者哪些表记录 binlog。
# 需要同步的二进制数据库名 binlog-do-db=masterdemo # 只保留7天的二进制日志,以防磁盘被日志占满(可选) expire-logs-days = 7 # 不同步的数据库 binlog-ignore-db=information_schema binlog-ignore-db=performation_schema binlog-ignore-db=sys
(2)在Slave端:在my.cnf中,需要配置备份库与主服务的库的对应关系。
#如果salve库名称与master库名相同,使用本配置 replicate-do-db = masterdemo #如果master库名[mastdemo]与salve库名[mastdemo01]不同,使用以下配置[需要做映射] ;若没有不同则不需要配置 replicate-rewrite-db = masterdemo -> masterdemo01 #如果不是要全部同步[默认全部同步],则指定需要同步的表 replicate-wild-do-table=masterdemo01.t_dict replicate-wild-do-table=masterdemo01.t_num
二、读写分离
在MySQL主从架构中,是需要严格限制从服务的数据写入的,一旦从服务有数据写入,就会造成数据不一致。并且从服务在执行事务期间还很容易造成数据同步失败,所以从库我们需要设置为只读模式; read_only=1
注意: read_only=1 ,设置为只读模式,限定的是普通用户进行数据修改的操作,但不会限定具有 super 权限的用户的数据修改操作。
三、主从复制
1、主从复制的原理
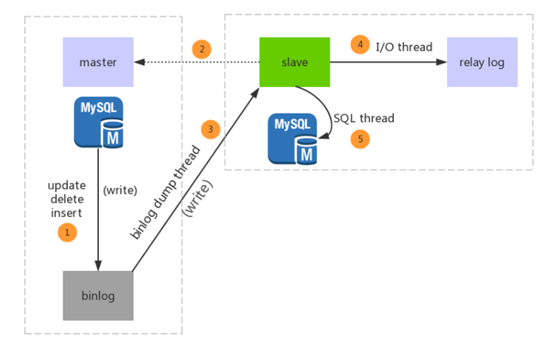
(1)master执行了写操作后会写入到 binlog 中,通知 dump 线程去推送更新的 binlog 到 slave;
(2)slave 接收到数据之后通过 I/O 线程写入到 relay log中;
(3)slave 的 SQL 线程会从 relay log 中读取数据并执行写入到DB中;
2、主从复制的方式
2.1 同步复制(MySQL不支持同步复制)
当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响。需要有超时时间。

2.2 异步复制
MySQL默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返回给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主如果crash掉了,此时主上已经提交的事务可能并没有传到从上,如果此时,强行将从提升为主,可能导致新主上的数据不完整。
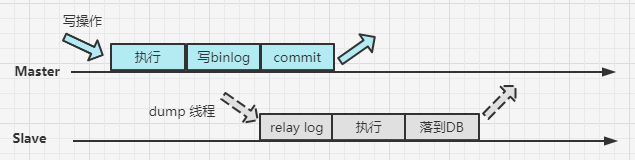
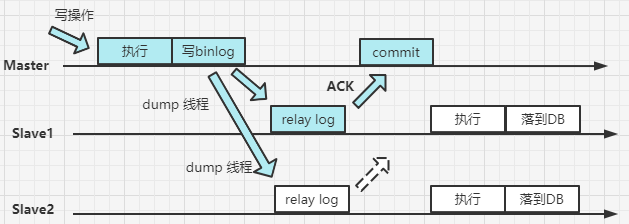
2.3 半同步方式
介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端。相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。
注意:Master在给 Slave 推送了一个数据之后,默认10s之后Slave 还未给 Master 一个 ACK,则半同步方式会给降级,变为异步同步的方式。
四、高可用架构方案
1、MMM高可用方案(已经淘汰)
MMM(Master-Master replication managerfor Mysql,Mysql主主复制管理器)是一套灵活的脚本程序,基于perl实现,用来对mysql replication进行监控和故障迁移,并能管理mysql Master-Master复制的配置(同一时间只有一个节点是可写的)
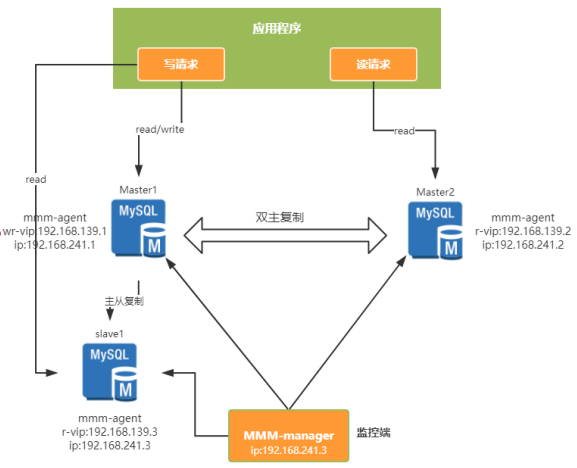
优点
(1)高可用性,扩展性好,出现故障自动转移,对于主主同步,在同一时间只提供一台数据库写操作,保证数据的一致性。
(2)配置简单,容易操作。
缺点
(1)需要一台备份服务器,浪费资源;
(2)需要多个虚拟IP;
(3)agent可能意外终止,引起裂脑。
若当前的 master1 产生了网络抖动的情况,将会把 master2 切换为 可读可写 的方式,master1 抖动过后也是 可读可写的方式,就产生了脑裂;
2、MHA方案
MHA服务,有两种角色, MHA Manager(管理节点)和 MHA Node(数据节点)。在MySQL故障切换过程中,MHA能做到在 0~30秒 之内自动完成数据库的故障切换操作,目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器。
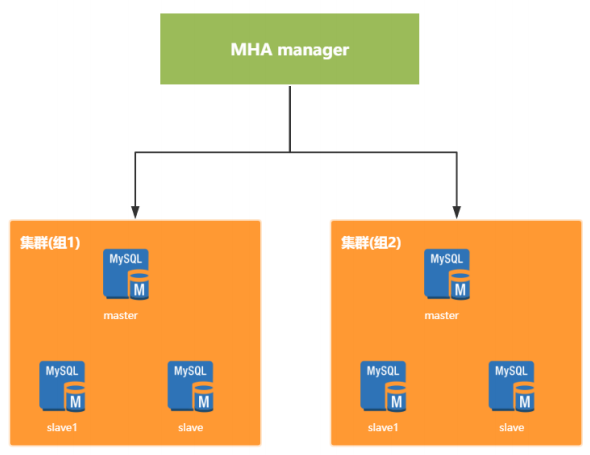
MHA 也可能发生脑裂,但是可以解决;在进行主从切换的时候,选出数据最接近master的slave的作为新的 master,将 slave 切换为 master 之后,允许执行一个 shell 脚本,将原来的 master 服务关掉。
优点
(1)不需要备份服务器;
(2)不改变现有环境;
(3)操作非常简单;
(4)可以进行日志的差异修复;
(5)可以将任意slave提升为master;
缺点
(1)需要全部节点做ssh秘钥;
(2)MHA出现故障后配置文件会被修改,如果再次故障转移需要重新修改配置文件。
(3)自带的脚本还需要进一步补充完善,且用perl开发,二次开发困难。
五、分库分表
1、为什么需要分库分表?
(1)读写分离;
(2)建索引,优化查询;
(3)
2、有哪些拆分方式?
横向拆分
数据量庞大的表,拆分为结果一样的几个表;
纵向拆分

 浙公网安备 33010602011771号
浙公网安备 33010602011771号