
python pyspark入门篇
一.环境介绍:
1.安装jdk 7以上
2.python 2.7.11
3.IDE pycharm
4.package: spark-1.6.0-bin-hadoop2.6.tar.gz
二.Setup
1.解压spark-1.6.0-bin-hadoop2.6.tar.gz 到目录D:\spark-1.6.0-bin-hadoop2.6
2.配置环境变量Path,添加D:\spark-1.6.0-bin-hadoop2.6\bin,此后可以在cmd端输入pySpark,返回如下则安装完成:

3.将D:\spark-1.6.0-bin-hadoop2.6\python下的pySpark文件拷贝到C:\Python27\Lib\site-packages
4.安装py4j , pip install py4j -i https://pypi.douban.com/simple
5.配置pychar环境变量:
三.Example
1.make a new python file: wordCount.py
#!/usr/bin/env python # -*- coding: utf-8 -*- import sys from pyspark import SparkContext from operator import add import re def main(): sc = SparkContext(appName= "wordsCount") lines = sc.textFile('words.txt') counts = lines.flatMap(lambda x: x.split(' '))\ .map( lambda x : (x, 1))\ .reduceByKey(add) output = counts.collect() print output for (word, count) in output: print "%s: %i" %(word, count) sc.stop() if __name__ =="__main__": main()
2.代码中的words.txt如下:
The dynamic lifestyle people lead nowadays causes many reactions in our bodies and the one that is the most frequent of all is the headache
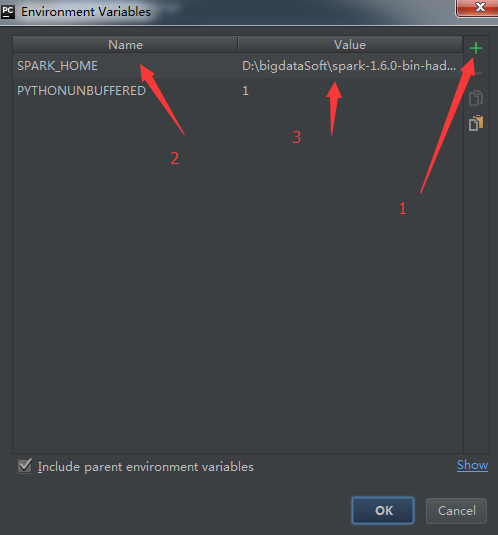
3.给当前运行程序配置spark环境变量:
3.1 工具栏 run --> Edit configuration-->点击Enviroment variables后面的三个点
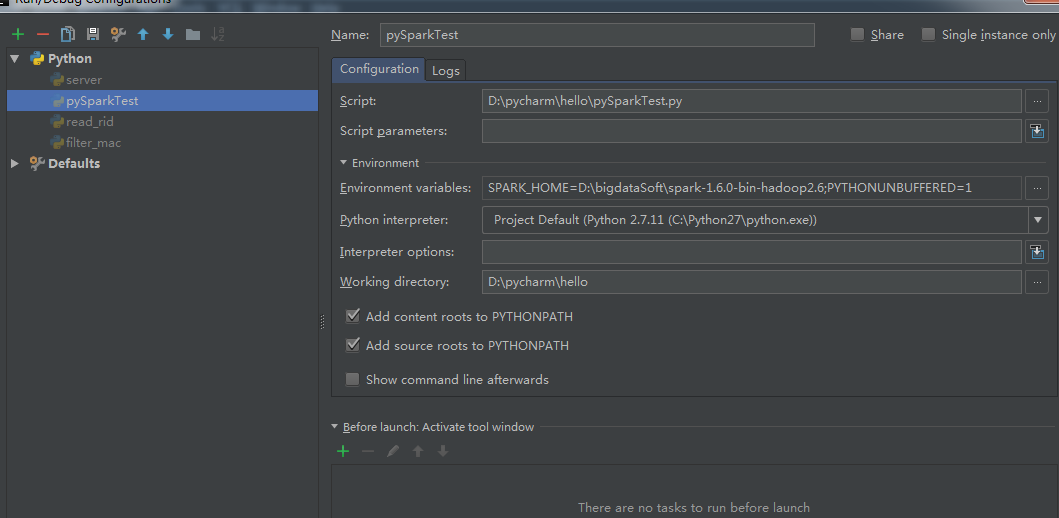
3.2 然后点击 + ,输入key:SPARK_HOME, value: D:\spark-1.6.0-bin-hadoop2.6
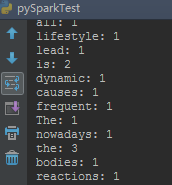
4.输出结果如下图:
四.深入练习:
1.文档:http://spark.apache.org/docs/latest/api/python/pyspark.html
2.在解压的Spark文档下,有example下有很多实例可以练习。D:\spark-1.6.0-bin-hadoop2.6\examples\src\main\python
作 者:小闪电
出处:http://www.cnblogs.com/yueyanyu/
本文版权归作者和博客园共有,欢迎转载、交流,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。如果觉得本文对您有益,欢迎点赞、欢迎探讨。本博客来源于互联网的资源,若侵犯到您的权利,请联系博主予以删除。
