
第一次个人编程作业
java余弦相似度实现论文查重——第一次软工个人项目**
| 软件工程 | https://edu.cnblogs.com/campus/gdgy/informationsecurity1812 |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/gdgy/informationsecurity1812/homework/11155 |
| 作业目标 | 论文查重算法设计+单元测试+JProfiler+PSP表格+Git管理 |
代码链接
整体流程:
- 将文件地址输入到readTxtile类中进读取文件以及去除文本的标点符号,返回String变量data
- data进入Analyzer中,进行分词,返回list
- list进入Count中,进行getStringFrequency获取词频向量以及getDoubleStrForCosValue进行余弦相似度的公式计算
- 三个类由Main调用输出重复率
项目结构:
单元测试
测试覆盖率

单元测试代码
public class MainApplicationTest {
/**
* 测试 文本为空文本的情况
*/
@Test
public void testForEmpty(){
try {
Main.main("src/test/testcase/orig.txt","src/test/testcase/empty.txt","src/test/result/testEmptyResult.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试 输入的对比文本路径参数为错误参数的情况
*/
@Test
public void testForWrongOriginArgument(){
try {
Main.main("src/test/testcase/123.txt","src/test/testcase/orig_0.8_add.txt","src/test/result/testAddResult.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试 输出文件路径参数为错误参数的情况
*/
@Test
public void testForWrongOutputArgument(){
try {
Main.main("src/test/testcase/orig.txt","src/test/testcase/orig.txt","src/test/result/testAWrongArgumentResult");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试20%文本添加情况:orig_0.8_add.txt
*/
@Test
public void testForAdd(){
try {
Main.main("src/test/testcase/orig.txt","src/test/testcase/orig_0.8_add.txt","src/test/result/testAddResult.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试20%文本删除情况:orig_0.8_del.txt
*/
@Test
public void testForDel(){
try {
Main.main("src/test/testcase/orig.txt","src/test/testcase/orig_0.8_del.txt","src/test/result/testDelResult.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试20%文本乱序情况:orig_0.8_dis_1.txt
*/
@Test
public void testForDis1(){
try {
Main.main("src/test/testcase/orig.txt","src/test/testcase/orig_0.8_dis_1.txt","src/test/result/testDis1Result.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试20%文本乱序情况:orig_0.8_dis_3.txt
*/
@Test
public void testForDis3(){
try {
Main.main("src/test/testcase/orig.txt","src/test/testcase/orig_0.8_dis_3.txt","src/test/result/testDis3Result.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试20%文本乱序情况:orig_0.8_dis_7.txt
*/
@Test
public void testForDis7(){
try {
Main.main("src/test/testcase/orig.txt","src/test/testcase/orig_0.8_dis_7.txt","src/test/result/testDis7Result.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试20%文本乱序情况:orig_0.8_dis_10.txt
*/
@Test
public void testForDis10(){
try {
Main.main("src/test/testcase/orig.txt","src/test/testcase/orig_0.8_dis_10.txt","src/test/result/testDis10Result.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试20%文本乱序情况:orig_0.8_dis_15.txt
*/
@Test
public void testForDis15(){
try {
Main.main("src/test/testcase/orig.txt","src/test/testcase/orig_0.8_dis_15.txt","src/test/result/testDis15Result.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试20%文本格式错乱情况:orig_0.8_mix.txt
*/
@Test
public void testForMix(){
try {
Main.main("src/test/testcase/orig.txt","src/test/testcase/orig_0.8_mix.txt","src/test/result/testMixResult.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试20%文本错别字情况:orig_0.8_rep.txt
*/
@Test
public void testForRep(){
try {
Main.main("src/test/testcase/orig.txt","src/test/testcase/orig_0.8_rep.txt","src/test/result/testRepResult.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试相同文本:orig.txt
*/
@Test
public void testForSame(){
try {
Main.main("src/test/testcase/orig.txt","src/test/testcase/orig.txt","src/test/result/testSameResult.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
/**
* 测试文本的子集文本:orig_sub.txt
*/
@Test
public void testForSub(){
try {
Main.main("src/test/testcase/orig.txt","src/test/testcase/orig_sub.txt","src/test/result/testSubResult.txt");
}
catch (Exception e) {
e.printStackTrace();
// 如果抛出异常,证明测试失败,没有通过,没通过的测试计数在Failures中
Assert.fail();
}
}
算法分析
余弦相似度算法
计算公式
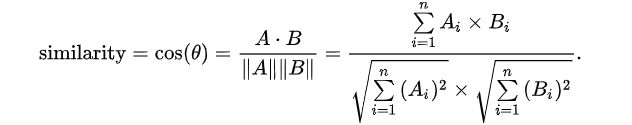
关键:余弦相似度 (Cosine Similarity) 通过计算两个向量的夹角余弦值来评估他们的相似度。将向量根据坐标值,绘制到向量空间中,求得他们的夹角,并得出夹角对应的余弦值,此余弦值就可以用来表征这两个向量的相似性。夹角越小,余弦值越接近于1,它们的方向越吻合,则越相似。
设计算法思路:
-
对文本进行处理变成纯文本(只含有文字)
-
对纯文本进行分词,利用ik分词器
-
记录分词后的词频,填入二维数组
-
利用数组中的数据进行循环来计算出点积和模,最后带入公式
具体实现
Count进行分次后的字符串的词频计算,用了两次循环分别对两个字符串进行词频计算,每遇到相同的的词语计数变量就自加,遍历完字符串后将当前变量的值放到数组相应位置。
getDoubleStrForCosValue利用Count中得到的字符串词频向量带入余弦相似度公式计算得出结果。
public class Count {
/**
* 获取两组字符串的词频向量
* @param str1List
* @param str2List
* @return
*/
public static int [][] getStringFrequency(List<String> str1List,List<String> str2List){
Set<String> cnSet = new HashSet<String>();
cnSet.addAll(str1List);
cnSet.addAll(str2List);
int [][] res = new int[2][cnSet.size()];
Iterator it = cnSet.iterator();
int i=0;
while(it.hasNext()){
String word = it.next().toString();
int s1 = 0;
int s2 = 0;
for(String str : str1List){
if(word.equals(str)){
s1++;
}
}
res[0][i] = s1;
for(String str : str2List){
if(word.equals(str)){
s2++;
}
}
res[1][i] = s2;
i++;
}
return res;
}
/**
* 获取两组向量的余弦值
* @param ints
* @return
*/
public static float getDoubleStrForCosValue(int [][] ints){
BigDecimal fzSum = new BigDecimal(0);
BigDecimal fmSum = new BigDecimal(0);
BigDecimal seq1SumBigDecimal = new BigDecimal(0);
BigDecimal seq2SumBigDecimal = new BigDecimal(0);
int num = ints[0].length;
for(int i=0;i<num;i++){
BigDecimal adb = new BigDecimal(ints[0][i]).multiply(new BigDecimal(ints[1][i]));
fzSum = fzSum.add(adb);
seq1SumBigDecimal = seq1SumBigDecimal.add(new BigDecimal(Math.pow(ints[0][i],2)));
seq2SumBigDecimal = seq2SumBigDecimal.add(new BigDecimal(Math.pow(ints[1][i],2)));
}
//开方
double sqrt1 = Math.sqrt(seq1SumBigDecimal.doubleValue());
double sqrt2 = Math.sqrt(seq2SumBigDecimal.doubleValue());
//使用BigDecimal保证精确计算浮点数
fmSum = new BigDecimal(sqrt1).multiply(new BigDecimal(sqrt2));
return fzSum.divide(fmSum,10,RoundingMode.HALF_UP).floatValue();
}
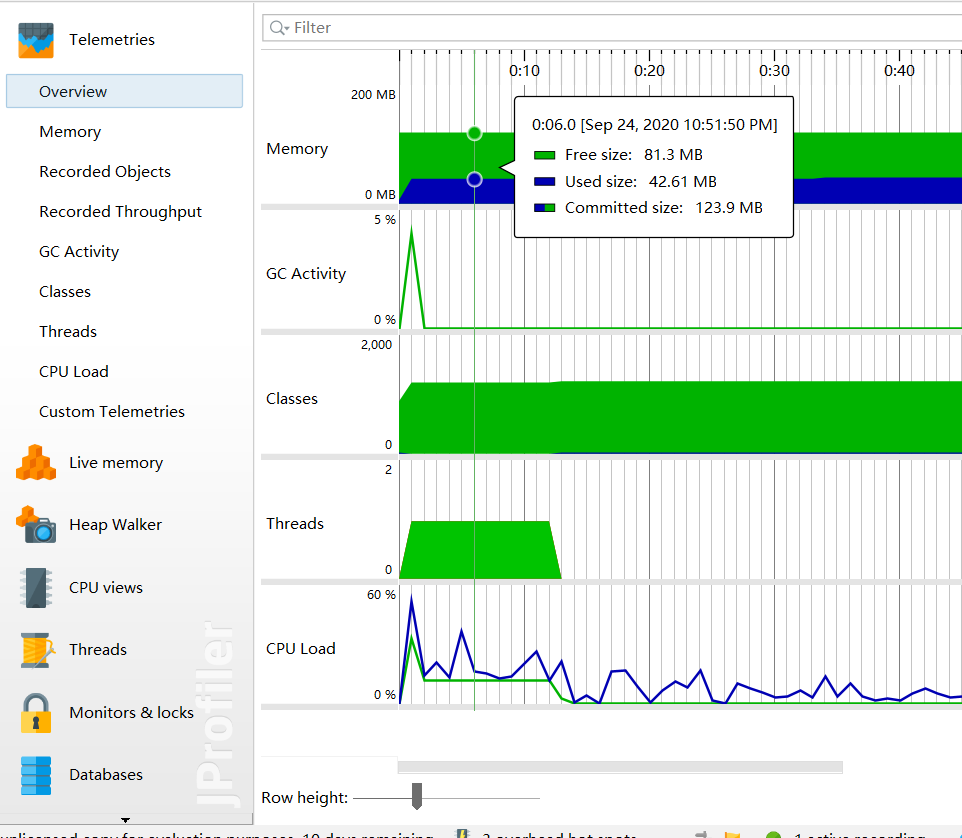
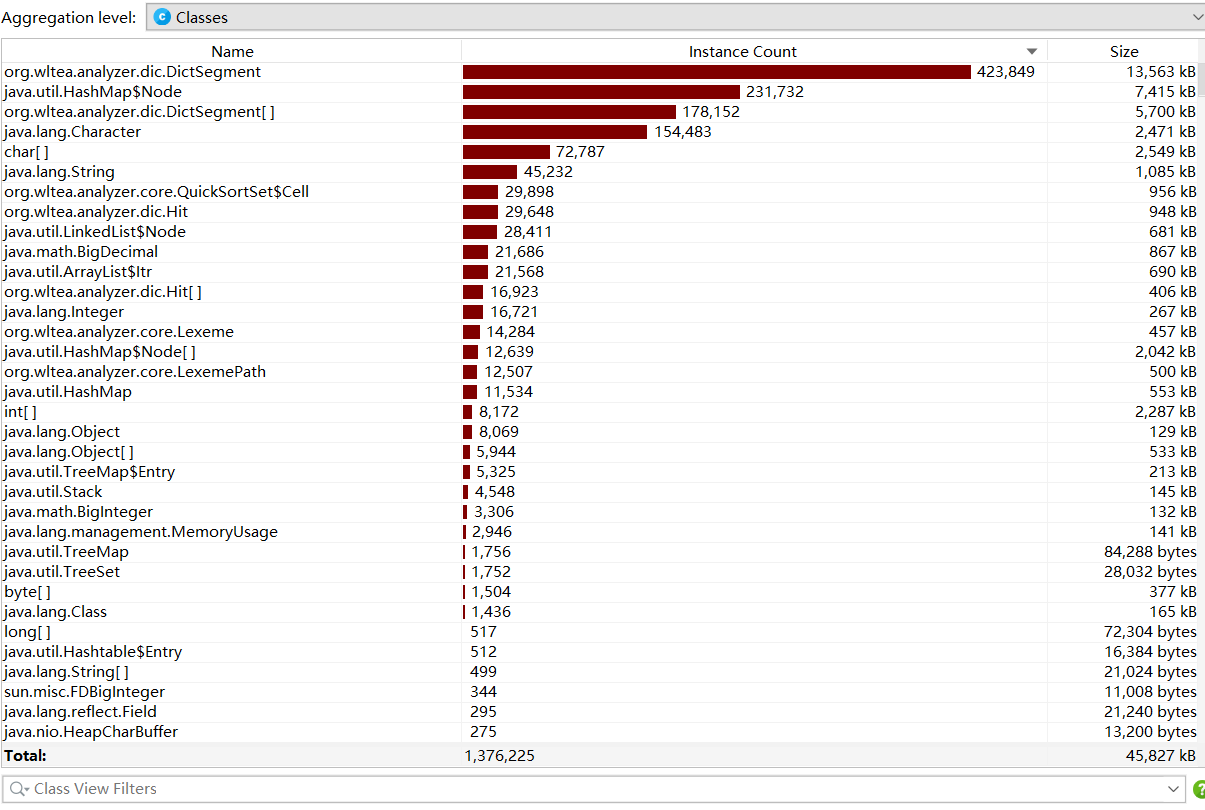
JProfile进行性能分析
类的内存消耗
堆内存情况

时间(时间为0.7s,满足要求,耗时较长的部分为获取字符串词频向量的类)

psp表格
| PSP 各个阶段 | 自己预估的时间(分钟) | 实际的记录(分钟) |
|---|---|---|
| 计划: 明确需求和其他因素,估计以下的各个任务需要多少时间 | 30 | 60 |
| 开发 (包括下面 8 项子任务) | 420 | 650 |
| 需求分析 (包括学习新技术、新工具的时间) | 60 | 120 |
| 生成设计文档 | 30 | 50 |
| 设计复审 | 30 | 20 |
| 代码规范 (为目前的开发制定或选择合适的规范) | 30 | 30 |
| 具体设计 | 60 | 100 |
| 具体编码 | 120 | 200 |
| 代码复审 | 30 | 20 |
| 测试(自我测试,修改代码,提交修改) | 60 | 90 |
| 报告 | 180 | 260 |
| 测试报告 | 60 | 80 |
| 计算工作量 | 30 | 30 |
| 事后总结, 并提出过程改进计划 | 90 | 150 |
| 合计 | 600 | 860 |
总结
- 第一次独立完成的个人项目,在网上查了很多资料,学习到了很多新的知识,第一次使用ik分词器,代码实现了余弦相似度的计算
- 需求分析做的不够好,由于是第一次做个人项目,在分析这一块做的非常差,在看到项目需求之前根本不知道从何下手,查了很多资料之后才明白
- 在psp中也体现出来预想的与实际确实差距很大,需要积累更多的项目经验
- 不足的地方太多了,学无止境,继续学习
