



kubernetes简介
docker和k8s的时间简史
| 时间阶段 | 关键事件 |
|---|---|
| 萌芽与诞生 (2013-2014) |
• 2013: Docker开源 (基于go语言编写) • 2014: Google公司开源Kubernetes,默认以Docker 为运行时 • 生态分化: Docker Swarm容器编排工具 与 CoreOS rkt 容器 出现 |
| 格局初定 (2015-2016) |
• 2015: K8s 捐赠给 CNCF • 2016: K8s 在市场完胜 Docker Swarm • CNCF 推动 CRI 标准,并推出 dockershim适配器 |
| 运行时之争 (2017-2020) |
• 2017: Docker 将 containerd 捐赠给 CNCF • 2018: Red Hat 收购 CoreOS,rkt 退场 • 2019: Docker 公司被收购,Docker Swarm 战略放弃 • 2020: K8s 宣布弃用 Docker 运行时 |
| 后Docker时代 (2022-至今) |
• 2022: K8s 1.24 正式移除 dockershim • 2024: K8s 1.30 发布,生态完全基于 CRI, CNI, CSI 等标准 |
- 容器运行时:真正负责启动和运行容器的组件(containerd 是docker的容器运行时,它负责在宿主机上拉取镜像、创建和管理容器)
- CNCF(Cloud Native Computing Foundation 云原生计算基金会):是致力于培育和维护云原生技术(如Kubernetes、Prometheus等)生态的开源基金会
- CRI是Kubernetes定义的一个标准接口(k8s如何与容器运行时进行通信的接口标准),它让kubelet能够使用不同的容器运行时
- Dockershim:一个为了兼容 Docker 而创建的“翻译器”(让原本不支持CRI标准的Docker能够与Kubernetes通信)
- 国内基于k8s服务提供的容器编码服务
- 阿里云: 容器服务 Kubernetes 版 ACK
- 腾讯云: 腾讯云容器服务(Tencent Kubernetes Engine ,TKE)
- 华为云: 云容器引擎 CCE
- K8s 自 1.24 版本起,正式移除并弃用了内置的
dockershim组件- 对开发人员:依然可以使用 Docker 来构建、测试和推送镜像
- 运维人员:在部署新版本K8s集群时,若坚持使用docker运行时,则需要手动部署一个替代
dockershim的适配器(cri-dockerd) - 推荐1.23.17版本,因为该版本是k8s官方支持的最后一个docker容器运行时
k8s功能介绍
核心功能:自动化的部署、扩展和管理容器化应用程序
-
服务发现与负载均衡:自动为容器分配一个固定的域名或VIP,并将网络请求分发到健康的容器实例上。
-
存储编排:自动挂载您选择的存储系统(本地盘、云盘、NFS等)。
-
自动发布与回滚:可以控制您应用的发布节奏(如金丝雀发布),如果出现问题,立即回滚到上一个版本。
-
自我修复:当容器失败时,它会自动重启容器;当节点宕机时,它会重新调度容器到其他健康节点;如果容器不响应健康检查,它会停止对外提供服务。
-
密钥与配置管理:允许您存储和管理敏感信息(如密码、令牌)和应用配置,而无需将其硬编码在容器镜像中。
-
水平扩缩容:可以根据CPU使用率或自定义的指标,自动增加或减少容器实例的数量
k8s解决的docker核心缺陷
| Docker的缺陷 | K8S的解决方案 |
|---|---|
| 容器重启后IP变化,跨主机互联不便 | 服务发现与负载均衡:通过Service和DNS为一组容器提供固定的访问端点 |
| 不便于集群调度 | 自动化调度:根据资源需求、策略等自动将容器调度到合适的节点上 |
| 不方便集群监控、管理 | 统一的API和管理平面:通过kubectl或Dashboard统一管理整个集群 |
| 不便于做健康检查,无法实现故障转移 | 自我修复:通过探针(Liveness, Readiness)进行健康检查,并自动重启或替换故障容器 |
| 跨节点存储卷挂载问题 | 存储编排:通过Persistent Volume (PV) 和 Persistent Volume Claim (PVC) 抽象存储细节,实现跨节点的持久化存储 |
| 多个节点容器配置共享 | 配置管理:使用ConfigMap和Secret来管理配置,并作为文件挂载到容器中 |
Kubernetes集群架构与组件介绍
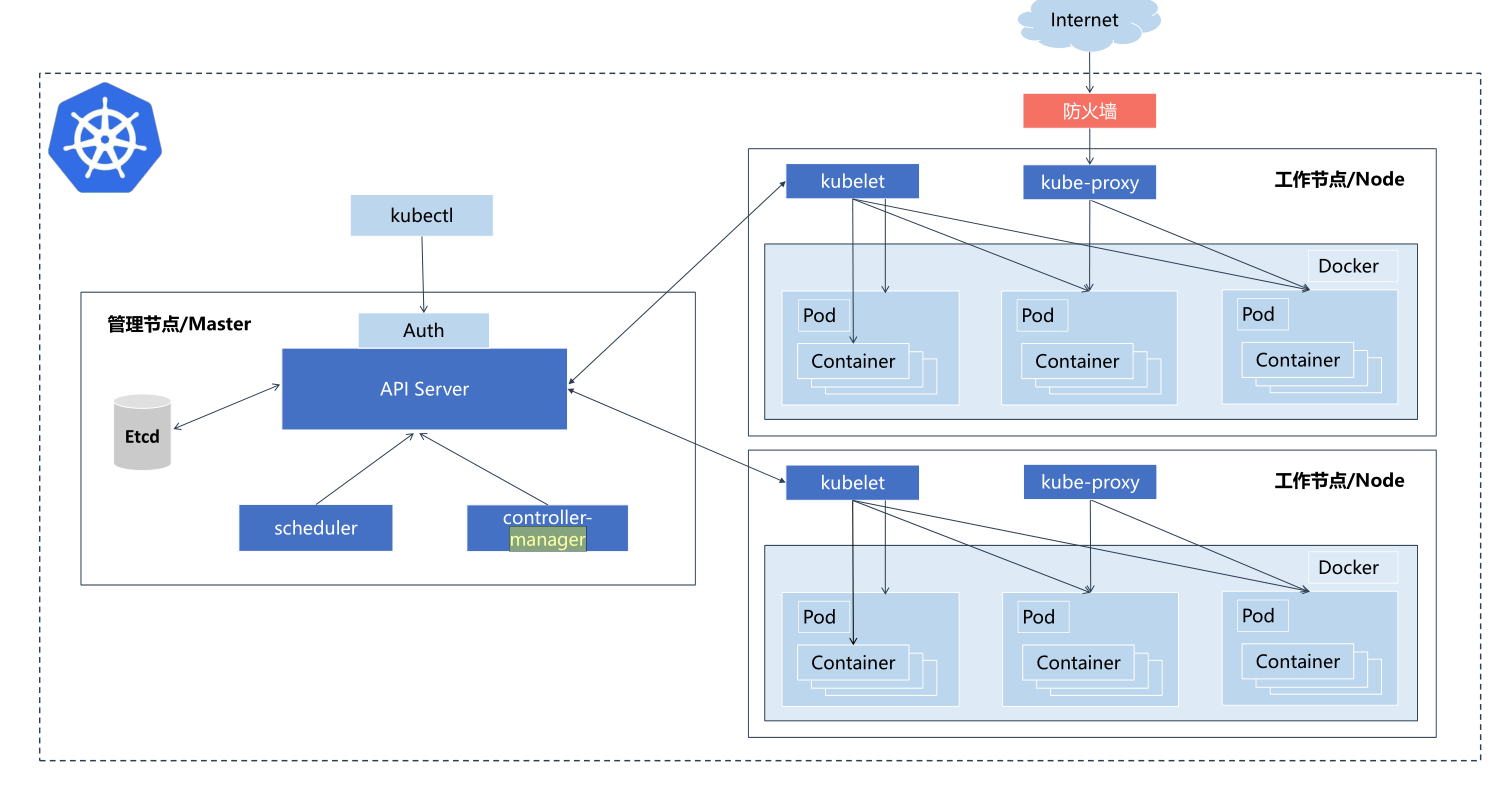
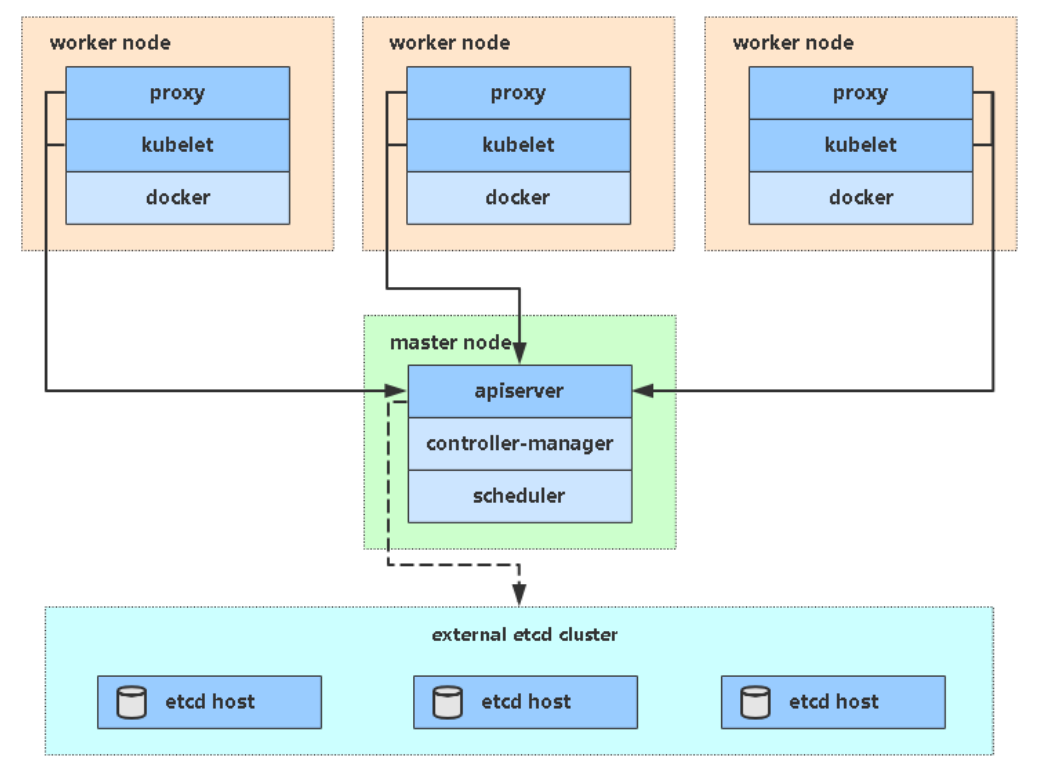
master / controll plane
不直接部署业务容器,而是负责集群的管理、调度和决策(管理salve节点) etcd
一个高可用的键值对数据库,用于保存集群状态数据,比如Pod、Service等对象信息 apiserver
所有内部组件和外部用户都必须通过apiserver来查询或更改集群状态
所有对象资源的增删改查和监听操作都交给APIServer处理后再提交给Etcd存储,是唯一直接与etcd交互的组件 scheduler 根据调度算法为新创建的Pod选择一个最合适的worker node节点 controller manager 控制器管理者,复制监控和修复集群状态 节点控制器:发现和响应节点故障 副本控制器:确保Pod的副本数量始终符合预期
slave / worker node
# 部署实际的业务容器,以提供客户端访问 kubelet 管理 Pod 内容器的完整生命周期(创建、启动、停止、重启) 持续向 API Server 报告本节点上 Pod 和容器的状态(如健康、资源使用情况)
Pod
K8s 中能够创建和管理的最小、最简单的部署单元,它代表一个或多个共享网络和存储的容器组
kube-proxy 集群的网络代理和负载均衡器,它通过维护节点上的网络规则 底层支持: iptables和ipvs工作模式,生产环境中推荐大家使用ipvs模式
docker或rocket
容器引擎,运行容器
CNI容器网络接口
# 为容器(特别是 Pod)提供跨主机节点的网络通信能力 # 常见的 CNI 插件 Bridge:创建 Linux 网桥并将容器连接到网桥。 Flannel:为 Kubernetes 提供覆盖网络(Overlay Network)。 Calico:基于 BGP 的网络方案,支持覆盖和非覆盖网络。 Macvlan:为容器分配独立的 MAC 地址,使其像物理设备一样工作。 IPvlan:为容器提供 IPvlan 网络接口。 Portmap:基于 iptables 实现端口映射
K8S的三种网络类型
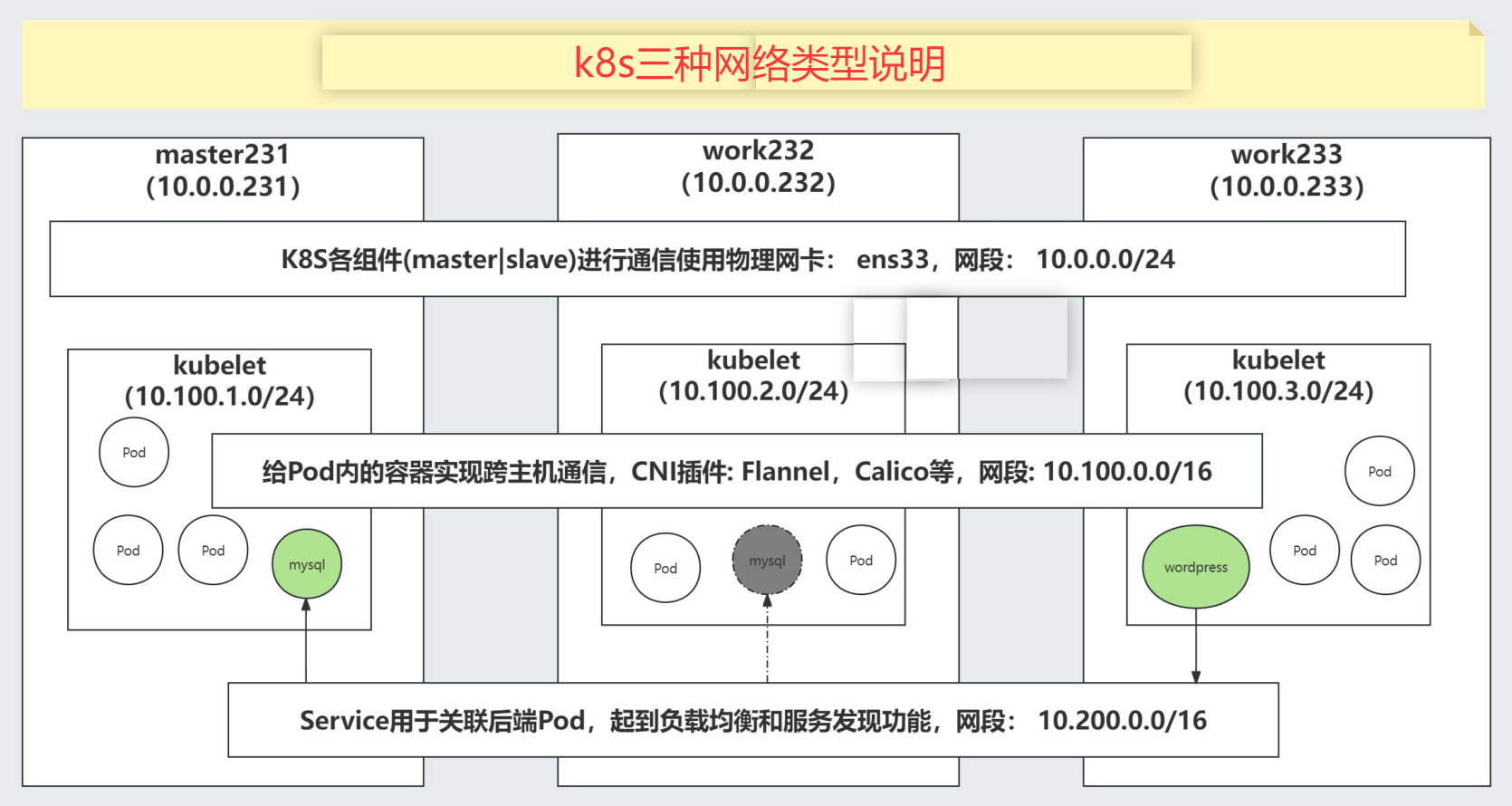
K8S各组件通信的网络: 使用时物理网卡,默认网段: 10.0.0.0/24跨节点容器实现通信的网段: 用户可以自定义,学习环境推荐: 10.100.0.0/16 但是在自定义网段时,要考虑将来能够分片的IP地址数量,"10.100.0.0/16"最多有65536个IP地址 如果将来容器运行的数量超过该规模时,应该考虑将网段地址调大,比如"10.0.0.0/8"Service网段: 为容器提供负载均衡和服务发现功能。也是需要一个独立的网段,比如"10.200.0.0/16"最多有65536个IP地址


 浙公网安备 33010602011771号
浙公网安备 33010602011771号