



文档解析方案(读取文件)
文档解析步骤
1. 文件加载:找到文件存放位置并载入处理流水线 常见问题:文件损坏、权限不足 2. 格式转换:消除格式差异,统一转为纯文本 将PDF中的表格转为Markdown格式 将图片转换为txt格式 3. 元数据提取:获取文档信息标签 捕捉文档的显性和隐性特征(作者、创建时间、文档类型等) 4. 结构化处理:将文本转化为有逻辑关系的知识网络(转化为机器可以理解的知识)
技术难点
# 处理扫描件: 1. 使用OCR(光学字符识别)技术识别文字 2. 校正识别错误(如将"3"识别为"B") 3. 保留原始版式信息 # 处理复杂表格: | 姓名 | 年龄 | 职业 | |-----|----- |-------| | 张三 | 28 | 工程师 | | 李四 | 35 | 设计师 |
文档解析案例
- 测试文档:包含表格和文字的pdf文件
# 测试文档:包含表格和文字的pdf文件 # 基础解析(使用llamaindex提供的文档解析方法具有局限性,只适合做单纯的文本处理) from llama_index.core import SimpleDirectoryReader reader = SimpleDirectoryReader( input_files=["/aiproject/data/report_with_table.pdf"] ) docs = reader.load_data() print(f"Loaded {len(docs)} docs") print(docs) # 高级解析(推荐使用python的第三方模块) import pdfplumber with pdfplumber.open(r"E:\ai大模型笔记\teacher\demo_19\data\report_with_table.pdf") as pdf: # 提取所有文本 text = "" for page in pdf.pages: text += page.extract_text() # extract_text: 取出页面的文本内容 print(text[:200]) # 打印前200字符 # 提取表格(自动检测) for page in pdf.pages: tables = page.extract_tables() for table in tables: print("\n表格内容:") for row in table: print(row)
- 测试文档:html网页
# 测试文档:html网页 import requests from bs4 import BeautifulSoup url = 'http://www.esjson.com/urlEncode.html' response = requests.get(url) soup = BeautifulSoup(response.content, 'html.parser') # soup返回的是一个html文件 print(soup) # 提取你需要的内容(获取文本内容) content = soup.get_text() # 或者根据需求提取特定元素
文本切分/分块方案
# dataconnecters在默认解析时一个文档会保留成一个node节点 # 文本切割太大 上下文丢失:过大的文本片段可能包含多个主题,使得模型难以理解特定上下文,导致答案不精准 计算资源消耗:处理大文本块需要更多的计算资源,可能导致效率低下,响应时间延长 信息冗余:大文本可能包含不必要的信息,使模型的注意力分散,从而影响关键信息的提取 # 文本切割太小 上下文不足:过小的文本片段可能缺乏必要的上下文,导致模型误解文本的意思 频繁拆分:切割过于细碎会导致模型在理解多段信息时出现困难,尤其是在推理和整合信息时 模型性能下降:太小的切割可能使得训练时数据样本稀疏,影响模型的学习效果和泛化能力
分块三要素
| 要素 | 说明 | 推荐值 |
| 块大小 | 每段文字的长度 | 200~500 |
| 块重叠 | 相邻重复内容 | 10%~20% |
| 切分依据 | 按句子/段落/语义划分 | 语义分割最优 |
分块策略对比表
| 策略类型 | 优点 | 缺点 | 使用场景 |
| 固定大小 | 实现简单 | 可能切断完整语义 | 技术文档 |
| 按段落分割 | 保持逻辑完整性 | 段落长度差异大 | 文学小说 |
| 语义分割 | 确保内容完整性 | 计算资源消耗大 | 专业领域文档 |
分块常见问题:
- 如何确定最佳块大小(测试不同尺寸查看检索效果)
# 测试块大小对召回率的影响 sizes = [128, 256, 512] for size in sizes: test_recall = evaluate_chunk_size(size) # evaluate_chunk_size评估块大小(自己编写该函数) print(f"块大小{size} → 召回率{test_recall:.2f}%")
- 分块重叠是否越多越好(适当重叠可防止信息断裂,过多会导致冗余)
from llama_index.core import SimpleDirectoryReader # 加载文档 documents = SimpleDirectoryReader(input_files=["/aiproject/data/ai_development_history.txt"]).load_data() # 使用固定节点分割 from llama_index.core.node_parser import TokenTextSplitter fixed_splitter = TokenTextSplitter(chunk_size=256, chunk_overlap=20) fixed_nodes = fixed_splitter.get_nodes_from_documents(documents) print("固定分块示例:", [len(n.text) for n in fixed_nodes]) # 输出:[200, 200, 200] print("第一个节点内容:\n", fixed_nodes[0].text) print("第二个节点内容:\n", fixed_nodes[1].text) # 使用句子分割器 from llama_index.core.node_parser import SentenceSplitter splitter = SentenceSplitter(chunk_size=256) nodes = splitter.get_nodes_from_documents(documents) # 查看结果 print("固定分块示例:", [len(n.text) for n in nodes]) print("第一个节点内容:\n", nodes[0].text) print("第二个节点内容:\n", nodes[1].text)
固定分块 vs 语义分块
# 案例1:固定分块 from llama_index.core.node_parser import TokenTextSplitter fixed_splitter = TokenTextSplitter(chunk_size=200, chunk_overlap=20) fixed_nodes = fixed_splitter.get_nodes_from_documents(docs) print("固定分块示例:", [len(n.text) for n in fixed_nodes[:3]]) # 输出:[200, 200, 200] 结果可能不是固定的分块[120,78,90],结果跟所选的分词器有关 # 案例2:语义分块 from llama_index.core.node_parser import SemanticSplitterNodeParser from llama_index.embeddings.huggingface import HuggingFaceEmbedding semantic_splitter = SemanticSplitterNodeParser( buffer_size=1, embed_model=HuggingFaceEmbedding("BAAI/bge-small") ) semantic_nodes = semantic_splitter.get_nodes_from_documents(docs) print("语义分块示例:", [len(n.text) for n in semantic_nodes[:3]]) # 输出:[183, 217, 195]
召回率提升方案
召回率介绍
真正例(TP):能正确识别为正样本的数量
假负例(FN):实际为正样本但被错误识别为负样本的数量
召回率=真正例/(真正例+假负例)
召回率:模型在所有真实正样本中正确识别出的比例
- 高召回率:意味着模型能够识别更多的正样本,适用于需要尽量减少漏报的场景,比如医疗诊断
- 低召回率:表示模型漏掉了很多正样本,可能导致重要信息的丢失
提升召回率的三大策略
查询扩展:给问题添加修饰词(获取跟多相关内容)
混合检索(不推荐):结合关键词搜索和语义搜索
混合检索通过结合不同搜索方法提高信息检索的全面性和相关性,但同时增加了系统复杂性和资源消耗
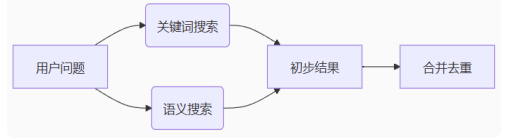
向量优化:微调模型使其更好的理解专业术语
效果验证方法
1. 准备测试问题集(至少50个典型问题)
2. 记录基础方案召回率
3. 应用优化策略后再次测试
4. 对比提升幅度
基础检索 vs 向量检索
# 案例1:基础(向量)检索 from llama_index.core import VectorStoreIndex vector_index = VectorStoreIndex(nodes) vector_retriever = vector_index.as_retriever(similarity_top_k=3) print("向量检索结果:", [node.text[:30] for node in vector_retriever.retrieve(query)]) # 案例2:混合检索 from llama_index.core import KeywordTableIndex keyword_retriever = KeywordTableIndex(nodes).as_retriever(retriever_mode="bm25", similarity_top_k=3) from llama_index.core.retrievers import QueryFusionRetriever fusion_retriever = QueryFusionRetriever([vector_retriever, keyword_retriever]) print("混合检索结果:", [node.text[:30] for node in fusion_retriever.retrieve(query)])
检索结果重排序(Rerank模型)
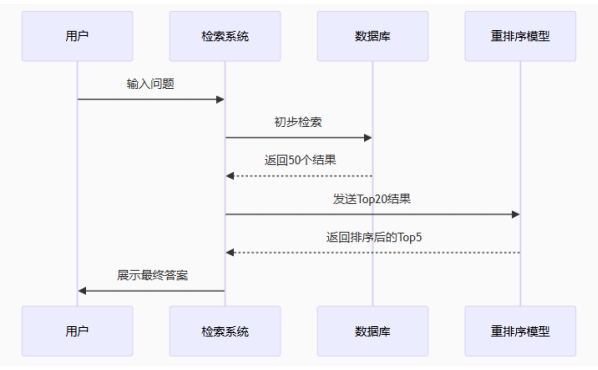
常见Rerank模型
| 模型名称 | 速度 | 精度 | 硬件要求 | 适用场景 |
| BM25 | 快 | 中 | 低 | 关键词搜索任务 |
| Cross-Encoder | 慢 | 高 | 高 | 小规模精准排序(较小规模数据集) |
| ColBERT | 中 | 高 | 中 | 速度与精度要保持平衡(较大规模数据集) |
无排序vs Cohere Reranker
# 初始检索结果(按相似度排序): results = [ "模型正则化方法简述", # 相关度0.7 "硬件加速技术进展", # 相关度0.65 "过拟合解决方案详解", # 相关度0.92 ← 正确答案 "数据集清洗方法" ] # 应用重排序 from llama_index.postprocessor.cohere_rerank import CohereRerank reranker = CohereRerank(api_key="YOUR_KEY", top_n=2) reranked_results = reranker.postprocess_nodes(results, query_str=query) print("重排序后结果:", [res.text for res in reranked_results])
排序变化对比
原始排序: 1. 模型正则化方法简述(相关度0.7) 2. 硬件加速技术进展(相关度0.65) 3. 过拟合解决方案详解(相关度0.92)← 正确答案 4. 数据集清洗方法 重排序后: 1. 过拟合解决方案详解(评分0.95)← 正确答案 2. 模型正则化方法简述(评分0.88)
ReRank模型位于RAG检索与生成模型之间,负责对检索出的文本进行重排序,从而提高相关性和准确度
Rerank模型与Embedding模型对比
| 方面 | Rerank模型 | Embedding模型 |
|---|---|---|
| 目标 | 对已有检索结果进行重新排序,提高结果相关性 | 将文本(词、句子、文档等)转换为向量,方便相似度计算和下游任务 |
| 输入 | 初步检索得到的一组候选结果和查询 | 原始文本(query、document) |
| 输出 | 按相关性重新排序的候选列表 | 向量表示(固定长度的实数向量) |
| 使用方法 | 通常基于深度学习模型对候选进行打分,如BERT做pair-wise或point-wise排序 | 通过训练得到固定或动态的向量,用于计算相似度、聚类、分类等 |
| 技术区别 | 重点是fine-tune排序任务,输入query和候选一起,生成相关性分数 | 重点是学习语义表示,向量捕捉文本语义和句法特征 |
| 应用场景 | 搜索引擎的二级排序、问答系统答案排序 | 语义检索、推荐系统、文本分类、聚类、相似度检索 |
完整流程


from llama_index.embeddings.huggingface import HuggingFaceEmbedding from llama_index.core import Settings, VectorStoreIndex from llama_index.llms.huggingface import HuggingFaceLLM from llama_index.core.schema import TextNode import json import torch # 初始化本地模型 # 1. 初始化本地模型 def setup_local_models(): # 设置本地embedding模型 embed_model = HuggingFaceEmbedding( model_name="/aiproject/model/embedding_model/sungw111/text2vec-base-chinese-sentence", device="cuda" if torch.cuda.is_available() else "cpu" ) # 设置本地LLM模型 llm = HuggingFaceLLM( model_name="/home/cw/llms/Qwen/Qwen1.5-1.8B-Chat", tokenizer_name="/home/cw/llms/Qwen/Qwen1.5-1.8B-Chat", model_kwargs={"trust_remote_code": True}, tokenizer_kwargs={"trust_remote_code": True}, device_map="auto", generate_kwargs={"temperature": 0.3, "do_sample": True} # 修改为do_sample=True避免警告 ) # 全局设置 Settings.embed_model = embed_model Settings.llm = llm Settings.chunk_size = 512 # 2. 加载数据并处理格式 def load_data(file_path): with open(file_path, 'r', encoding='utf-8') as f: data = json.load(f) nodes = [] for item in data: if isinstance(item, dict): # 处理DPR格式数据 if 'query' in item and 'positive_passages' in item: text = f"查询: {item['query']}\n相关文档: {item['positive_passages'][0]['text']}" # 处理QA对格式 elif 'question' in item and 'answer' in item: text = f"问题: {item['question']}\n答案: {item['answer']}" else: continue elif isinstance(item, str): text = item else: continue node = TextNode(text=text) nodes.append(node) return nodes # 3. 初始化本地模型 setup_local_models() # 4. 加载数据 data_path = "/home/cw/projects/demo_19/data/qa_pairs.json" nodes = load_data(data_path) # 5. 示例查询 query = "如何预防机器学习模型过拟合?" # 案例1:向量检索(使用本地embedding模型) vector_index = VectorStoreIndex(nodes) vector_retriever = vector_index.as_retriever(similarity_top_k=3) print("向量检索结果:", [node.text[:50] + "..." for node in vector_retriever.retrieve(query)]) # 案例2:关键词检索(不使用bm25模式) from llama_index.core import KeywordTableIndex keyword_index = KeywordTableIndex(nodes) keyword_retriever = keyword_index.as_retriever(similarity_top_k=3) # 使用默认模式 print("关键词检索结果:", [node.text[:50] + "..." for node in keyword_retriever.retrieve(query)]) # 案例3:查询引擎(使用本地LLM生成回答) query_engine = keyword_index.as_query_engine() response = query_engine.query(query) print("LLM生成回答:", response)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号